17 Jun 2026
 Planet GNOME
Planet GNOME
Hylke Bons: Bobby joins GNOME Circle
Excited that Bobby has been accepted as a GNOME Circle app!
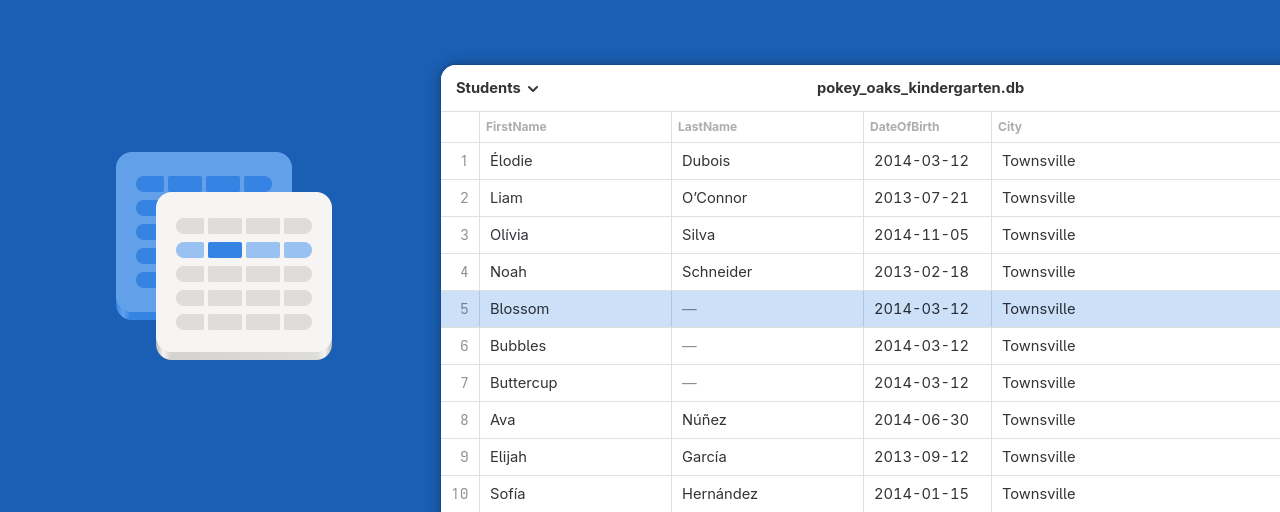
Who's Bobby?
Bobby is a viewer utility. It displays tables from SQLite files. The most deployed database format in the world. That's it.
Whilst hacking on the backend of Auroras I was missing an easy way to check my data tables. There are many database management tools, but they seemed too heavy for my use case.
GTK4 and Libadwaita
Releasing something smaller first also was a chance to refamiliarise myself with modern GNOME app development. It was my first serious project using Rust.
GTK is still the rock UI toolkit it has always been. Libadwaita makes it easy for your app to look beautiful and is a lot of fun to use.
The main challenge was hooking up the database backend to the ListModel required to be displayed by the new ColumnView. The struggle was worth it though as it enables Bobby to have lazy loading of rows, smooth scrolling, and a limited memory footprint.
After that using any other widget should be a breeze!
Future
I will keep the scope of the app small, but there are a few features I want to add in the future:
- Encrypted file support
- Updating values in place
- Search
Get Bobby on Flathub and always sanitise your database inputs!
17 Jun 2026 12:00am GMT
16 Jun 2026
Planet KDE | English
Week 3: Reviewer Feedback and Fixes
This is a weekly update from my Google Summer of Code 2026 project with KDE, improving effect widgets in Kdenlive, a free and open source video editor.
This week was driven entirely by reviewer feedback on MR !887; the draft MR for the Curves Widget.
Point snapping instead of rejection
When two curve control points are placed too close on the x-axis, avfilter/MLT crashes with Key point coordinates are too close or not strictly increasing.
The original guard in AssetParameterModel::internalSetParameter silently rejected the update, the user moved a point but nothing happened visibly. Reviewer Bernd Jordan flagged this as confusing UX.
The fix: instead of rejecting, snap the offending point so it maintains the minimum safe x-distance (~0.00266) from its neighbor. The curve is always valid, always sent to MLT, and the user sees immediate feedback.
Removing the 5 point limit for avfilter.curves
The curve editor had a maximum of 5 control points, inherited from frei0r.curves. JB pointed out there is no reason to keep this limit for avfilter.curves, it is a frei0r-specific constraint.
The fix: setMaxPoints is now only called for frei0r.curves. The avfilter.curves widget has no upper limit on control points.
Both fixes are in MR !887.
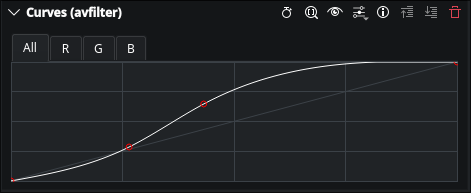
JB also noted the null placeholder approach in m_widgets for secondary av_curve params is not ideal long term, waiting on his direction before touching that.
16 Jun 2026 4:18pm GMT
Week 3 — Bug Fixes and Import/Export Feature
This week, I worked on two things: a bug fix that was created during the ActionCollection port and starting the import/export feature.
Bug fix: Lock/Unlock action text:
A bug was created after !29 was merged. When a wallet was locked, the placeholder message displayed a "Lock" button instead of "Unlock". The issue came from ActionData using static text, while the lock action needs to reflect the wallet's current state. The fix was easy - switch between the lock and unlock ActionData dynamically based on the locked property.
AC.ActionCollection.action: locked ? "unlock" : "lock"
This was submitted as !31 and merged.
Configure Shortcuts menu item:
I added a "Configure Shortcuts…" menu item to the globalDrawer(!32), using AC.StandardActionData.KeyBindings to attach to the action automatically created by ActionCollectionManager.
Import/Export feature: I started implementing the import/export feature. The format is KWalletManager-compatible XML, so users can migrate between KWalletManager and KeepSecret. The implementation adds: -ImportExportManager C++ class with exportToFile() and importFromFile() methods. -Export… and Import… menu items in the globalDrawer. -File picker dialogs using QtQuick.Dialogs.
The merge request !33 is open and under review.
16 Jun 2026 8:22am GMT
Oxygen 6.7 is here: a breath of fresh air for KDE’s classic theme
Logo by: Nuno Pinheiro The year started off bleak. As I was gallivanting through KDE themes at hand, I decided to stick with the Oxygen one. It didn't take long to notice that this old theme, once the default in the KDE 4 era, wasn't looking its best. A slew of little bugs had accumulated,...... Continue Reading →
16 Jun 2026 6:49am GMT
15 Jun 2026
Planet GNOME
Jussi Pakkanen: Beware of Star Trek managers, especially when bearing MBAs
Almost exactly three years ago the Oceangate submarine implosion happened. The disaster came about when a billionaire called Stockton Rush created his own unclassified submarine to go sightseeing on the Titanic. Ignoring all advice from experts he created a "macgyveresque death trap" that eventually killed him and sadly also 4 innocent people. The whole thing was a massive display of stupidity and arrogance with unfortunate outcomes. We are not going to go into the actual event any deeper, but those interested can find lots of material online.
Instead we are going to look more deeply into one often overlooked points of Stockton Rush's character. Apparently he felt like he was something of a "new James T. Kirk" (link1 paywalled, link2). Liking Star Trek is not that unusual. I'm guessing that more than 99% of the readers of this blog are fellow Star Trek fans. The problem lies elsewhere, but to understand it we first have travel back in time.
A brief overview of the British navy during the Napoleonic wars (by a non-historian, so probably inaccurate)
The original concept for Star Trek was, approximately, The Adventures of Horatio Hornblower in Space! The Enterprise is basically a British warship sailing through the vast ocean of outer space. The command structure mirrors this, where you have a captain, navigator, ship's doctor and so on. The Next Generation leaned into this even further by having a first officer and so on. The original Star Trek never went into detail on how the main cast got to their current positions, just that there was an Starfleet Academy they went to.
In the Napoleonic era of Hornblower things were quite different. Anyone who wanted to become a captain pretty much had to be from the upper classes. They had to obtain a letter of recommendation so that they could join a vessel as a midshipman at the age of 13 or so. They were expected to be able seamen by this time and then spent the next six to seven years working on the ship rigging sails and doing all manner of random jobs. This went on for six to nine years depending on circumstances, after which the person could take a formal examination to become a lieutenant. The test was not trivial, many people could not pass even after trying multiple times.
A lieutenant then had to work successfully for several years before obtaining the rank of captain. Even that did not guarantee a commission. Some captains never commanded a ship simply because there were not enough of them to go around. All in all becoming a ship's captain was a long and difficult journey. In a surprisingly non-British turn of events it was not possible for aristocrats to sneak past the gates. Getting a midshipman position was obviously easier with connections, but the lieutenant's test was something they had to pass on their own.
All of this is to say that every captain of the time was an expert with decades of working experience on many different positions aboard the ship.
What does a captain actually do?
[Note: I have not fact checked this portion at all. Feel free to consider it fanfiction.]
The year is 1808 and we are aboard a British warship about to leave for a mission of great importance. The captain gives the order to set sail. Whistles are blown, bells are rung and sailors springs into action. Every single man, with one exception, is either doing manual labour or directly supervising their underlings. That exception is the captain, who seemingly stands around doing nothing (at least if you ask the crew). This is not so.
What he is doing is crucial. He is observing the state of the ship and her crew. This includes things like overall crew morale, any aberrations from normal operations that could cause problems, thinking of workflow improvements and so on. In a sense he has to sense the ship itself. This only works because of two things. First of all he has personal experience doing the exact work he is observing. If you have not personally "been there", you can't really know if a crew is working well or not. You need a "gut feeling" to be able to sense this. Secondly the captain does not have any manual labour so he can focus all of his mental energy on observing the ship's state. He is preparing for all the unexpected things that may occur in the future. This can only happen if your brain is free from menial tasks.
This is exactly what most books on business and project management advocate. It is a time tested way of improving your chances of success. A highly skilled commander can take an average team of people and lead them to victory. It is the basic plot of most military and sports movies.
Getting back to the present
Now take a typical modern day billionaire-via-inheritance and show them Star Trek at an impressionable age. Do they see the advantages of education, hard work and ethics? The foundation upon which Gene Roddenberry carefully built the show? Hell no! What they see is this (TNG screenshot used because TOS did not have a suitable maritime episode).

And then they think: "Wow! I want to be exactly like that! Parading around in a funny hat while everyone obeys my orders without question is my life's mission from now on. And I get to have sexy space sex with hot sexy space ladies of sex whenever I want. This appeals to me even more profoundly than Atlas Shrugged." Some of them might go on to watch Master and Commander and shed tears upon realizing that they cant publicly flog employees for failing to salute their superiors. Yet. Expect this to be made legal in Silicon Valley any day now.
Liking Kirk is not in any way a bad thing. Wanting to "be just like Kirk" is, because in the real world running a business like Kirk runs the Enterprise is a terrible way to do things. An example will illustrate this nicely. Let's imagine a random episode where the Enterprise has gotten into trouble. Eventually Kirk will call for Scotty and tell him: "You need to <babble> <babble> <babble>." Scotty will then reply with a varying level of scottish accent something like: "I cannae change the laws of physics, captain". Kirk will then say the same thing again, just more aggressively and in a close up shot. Scotty replies with "Well in that case I can get it done in sixty minutes." Kirk counters with: "You have five." And thus the problem is solved. Kirk gets a commendation for incredible valour under stress while Scotty, who did all of the actual work, is never mentioned.
In "Kirk style" management the Big Boss tells his underlings what to do. If they try to give any sort of feedback, the Boss ignores everything and just repeats his original orders again and again until the other party yields. The only reason underlings ever resist The Vision is that they are lazy and it is the job of the manager to put them in their place. This seems like a bit from a comedy show, but I have unfortunately worked under bosses like this. Either you try to talk at least some sense into them, fail, get labeled as a "not team player", watch the project crash and get blamed for the failure, or you try to do the impossible task given to you, fail watch the project crash and get blamed for the failure.
Another major problem with Kirk is that due to the way tv shows and movies need to be structured, he is actually an obsessive gambler. The stakes must always get higher and the ways to get out of trouble must become ever crazier. Kirk will break any and all laws and regulations he sees fit and then, once he has succeeded, no disciplinary action is taken. The ends justify the means. Idolising this sort of behaviour leads to thinking that wild one-in-a-million gambits will succeed at least 99 times out of a hundred. And even if it fails, you can get out of it by betting everything on an even bigger gamble. The real world does not work like that. Reality is not a story and you are not its hero. It does not owe you eternal, or even eventual, success. Had Stockton Rush survived his death trap, he would most likely have faced criminal charges and, if convicted, gone to jail.
The myth of the existence of the professional manager
Let's make one last detour in the 1800s and assume that the 7th Earl of Sidcup or some such really wants to get his idiot son instated as a captain. He and contacts the appropriate naval officers.
"My offspring needs to become a captain of a ship post haste!"
"Well first he has to become a midshipman and ..."
"Phah! None of that nonsense. It's way too slow and not becoming of my statute. Also my son is 35 years old so the post of a midshipman would be beneath him."
"I see. Well what sort of prior naval experience does he have?"
"None."
"Has he even ever been out to sea?"
"Not to my knowledge. But that does not matter. He is highly skilled in using the abacus excelius to compute annual budgets."
"By himself?"
"Of course not. That is what secretaries are for. He just gives them orders. That he can do. And that is all that matters. Same as in sailing."
This person is unlikely to get his wish with this line of reasoning. On the other hand in modern business life this is common. For example when startups get VC money, a common requirement is that they need to get a "proper manager" as a CEO. Typically this means the investor's friend, and more often than not an MBA.
Contrary to common belief, having an MBA does not make you incompetent at managing a technical company (though there is a strong positive correlation). It is entirely possible to be a good manager on a field you have no personal experience in. You just have to have a lot of humility, listen (actually, properly listen) to your employees and let the people with hands-on experience make the most technical, product and development decisions. In other words you have to be the enabler, not the maverick decision maker. People with these sorts of personality traits are rare and typically their career choices steer as far away from getting an MBA as possible.
The absolute worst thing happens if the CEO in question combines the (lack of) skills of an MBA with the attitude of Kirk. That leads to incompetent decisions based on willful ignorance, executed with the fury of an egomaniac who refuses to even entertain the notion that they might be wrong. Further, any person inside the organisation who dares to point out potential flaws in the plan will soon find themselves outside said organisation. Disagreement is treason. Treason shall not go unpunished.
In the 1800s the British navy could be said to be the best in the world. It seems plausible that one component of this success was the requirement that the officers running their ships had to have actual experience operating the ship. Not looking at other people operating it. Not pretending to read about operating it for a test. Actually doing it. If we look around how MBA wielding sociopath CEOs are enshittifying absolutely everything about the tech industry, bringing this requirement back into active use starts to feel awfully tempting.
Epilogue: Why doesn't everything immediately explode?
A reasonable counterpoint to everything written above would be that if managers truly are that bad, shouldn't all those companies be bankrupt by now? In an ideal world they would be, but there are opposing forces that keep them going.
The first one is that all corporations have inertia. If you took an established major company and actively started to mismanage it to death, it would still take years for things to eventually collapse.
The second one is a dirty little secret. Many employees care more about the product they work on than "corporate visions" that seem to stem from overuse of peyote. They don't blindly obey idiotic commands but instead try to make things silently work within the system. Basically this means that corporations thrive despite their mad kings, not because of them. I know several people who have worked in these kinds of organizations and this is not as rare of an occurrence as one might imagine.
I have also experienced it personally. Years ago I was at a company, whose CEO (who, to the best of my knowledge, did not have an MBA) wanted to change the company's product so that it would do a specific thing X. Everybody thought this was a horrible idea and tried to reason with him using solid business and technical reasons (which turned out to be 100% correct). That failed. Spectacularly. This lead to an eternal series of secret meetings. The participants were main developers and all managers except the CEO. The only item on the agenda was "How can we make the CEO think that we did what he ordered while doing the exact opposite".
Eventually we did succeed, but boy was that a surreal couple of weeks.
15 Jun 2026 7:29pm GMT
Arun Raghavan: Notes from the PipeWire Hackfest 2026: Part 2
(these notes are being posted in two parts to make the length more manageable, part 1 is here)
Continuing from where we left off, about topics discussed at the PipeWire hackfest in Nice…
DSP features
We discussed a number of features related to digital signal processing blocks which are typically realised on specialised hardware (often a DSP core that can directly interface with physical audio inputs and outputs on your laptop/phone/…).
There is currently no standard way for the firmware running on these DSPs to signal what features can be realised directly on DSP. We also would want to allow such features, if exposed from PipeWire, to be realisable on CPU.
Now we do have a way to hide away signal processing in a specific node, which is the filter-graph parameter on the audioconvert node that wraps all audio nodes.
We could extend this mechanism to allow the internal node (say the ALSA node implementation), to expose what filtering it can perform "in hardware" (i.e. the software running on DSP). This would allow the audioconvert to delegate some or all processing to the internal node, with fallbacks available on the CPU.
We would need a number of pieces to do this, including:
-
Some standard definition of filters and associated parameters, so different implementations could have a standard "API" to express any given filter.
-
The DSP block would need to expose what features it has and how they might be used. We could imagine extending the ALSA UCM configuration to do that.
-
The
audioconvertnode would need to have a way to push downfilter-graphparams to the internal node, and negotiate what work it is doing vs. what is being delegated
This is a non-trivial effort, but gives us some sketch of what might be possible.
More DSP features
In addition to standard filters, we spoke about two topics that have come up commonly in the past.
The first is some way to expose the processing graph in the DSP, so PipeWire and other userspace daemons have a better view of what is happening on the DSP. With the ability to push dynamic topologies to DSP, there was some renewed interest in exposing and using the ASoC DAPM widget graph. As always, the devil is in the details.
The second thing that came up is speaker calibration. There is a lot of processing and tuning that goes into driving speakers on modern devices as much as possible without destroying them. Some of these are one-time parameters decided at product design time, and some of these translate to runtime parameters based on voltage and current feedback from the speaker amplifier.
For some systems (like Qualcomm platforms), speaker calibration might be run on each system start to perform dynamic tuning. We had some discussion of how this might tie in with the rest of the system for both determining the parameters (separate startup daemon vs. in-process initialisation), as well as uploading parameters to the speaker (some ALSA UCM extensions to load parameters on PCM open but before start, or preloading parameters into ALSA kernel controls and having the driver feed them in at the right point).
Volume limits
A way to set a limit on the maximum volume for a given device has been a common user request ([1] [2]). We discussed the possibility of creating a per-route property (with a fallback to the node, if there are no routes), which WirePlumber could manage to provide users a simple interface to control.
Since the hackfest, Wim has already done some work on this, and we need to bubble this up as a more user-accessible setting.
Performance
A number of performance-related topics were discussed.
The first was an option of a combined DSP mode, where instead of one port per channel, a node would expose one port for all the channels of the stream (but continue to run in the configured "DSP" format/rate). This would improve stream performance for non-JACK-like use-cases, especially in resource-constrained environments.
On the WirePlumber side, there was a discussion about using LuaJIT instead of standard Lua. There are some compatibility issues to be determined there (such as language version supported, etc.), but there might be some quick performance wins to be made if this is feasible.
There is a plan to move some of the WirePlumber core to Rust, and that might be a good time to also port over some of the more standard functionality that tends not to change from Lua to Rust (though that could happen in a Lua->C transition and does not really need to wait on a Rust port).
Declarative Session Management
Another interesting, and broader, thread is the imperative nature of WirePlumber scripts - that is, policy decisions and associated action are often interwoven. It might be helpful to be able to make a clearer split where all policy decisions are first run, and then decisions are translated into actions at one go.
There are some historical choices that make this hard - for example, changing the profile of a device might create and destroy nodes, which makes it hard to be able to make decisions that are independent of the action. There were some ideas around redoing the profile concept such that all nodes are always exposed, but nodes could get a new state to signal availability (and profiles that would allow availability to change). That might make a declarative system possible to implement.
We also discussed the possibility of a "transaction" system. Something that would allow a client to submit a set of objects (think links between nodes), and then "commit" that transaction. This would also help reduce the number of roundtrips between PipeWire and WirePlumber, and generally help performance.
Bluetooth
Being colocated with the BlueZ face-to-face meeting, we had representation from the BlueZ community, so we were able to dive into a number of topics related to Bluetooth, primarily LE Audio.
The first topic was Auracast, the LE Audio system for broadcast audio, allowing listeners to tune into public broadcasts in a space, or to have a device stream audio to multiple headsets concurrently for shared listening. George had a demo system showing an implementation of Auracast with PipeWire, WirePlumber and BlueZ.
We had some discussion of where this feature should live, and the consensus was that we would probably want a separate daemon to manage Auracast settings and loading up the appropriate nodes (either for receiving or sending) based on users' preferences.
This led to a more general discussion about the current split of the Bluetooth implementation in PipeWire being SPA modules, which include streaming and some policy, and a lot more policy living inside WirePlumber. We could, and likely should, move all of this into higher level PipeWire modules instead, which could make these easier to work with overall.
There was also a discussion about the complexities of LE Audio, and the state of the current user experience with actual devices:
- Device interop is not always great, as the spec is new, the BlueZ implementation is still being completed, and device implementations seem of variable quality
- Reliable pairing/feature detection is hard, partly due to how BlueZ exposes the ability to talk to devices in Bluetooth Classic or Bluetooth LE modes
- Pairing left/right pairs currently needs individual pairing, which does not seem to be needed by other implementations (Android for example)
- Inter-device synchronisation might need some work as well
While there is much work to be done here, the pieces are coming together for first-class LE Audio support on Linux-based systems.
Audio analytics
We also spoke about "analytics" - using local neural networks to implement things like text-to-speech, speech-to-text, language translation, or other forms of processing.
These pose an interesting problem, because they look like a standard-ish audio stream on one side, but are effectively a sparse stream on the other side if we are talking about text. Even conversion between languages does not look like a standard filter, because the underlying model might consume a varying amount of data before generating an output, and the input and output lengths are not tightly correlated.
While it should be possible to implement such a system with PipeWire, it is not quite clear whether we should. As the application space in this area becomes more mature, it may become clearer what the right place in the stack is for these features.
Click detection and elimination
We spoke about detecting and eliminating clicks at the stop or start of a stream.
If an application is playing back audio, and suddenly stops (i.e. feeds silence, or just nothing), then the sudden drop in the signal might cause a click to be output. If you think of the corresponding waveform as representing the physical displacement of the speaker, then the drop to zero is like a sudden brake to a halt, which isn't possible, and manifests as a jolt that you hear as a clicky noise. The same analogy holds for resuming from a pause, but in the opposite direction.
The solution is usually to smooth out the end of the sound by fading out, but most applications do not do this, so this problem manifests quite clearly for most browser or application streams if you listen closely.
Wim described a number of experiments he has done for detecting such abrupt changes in audioconvert, but he was not happy with the results. We discussed some of these approaches, and what might work as acceptable tradeoffs to capture the most common cases while still trying to respect the integrity of the signal being sent by the application.
(sorry about the vagueness here, I missed taking more detailed notes)
Miscellanea
The rest of the discussion covered disparate topics that I don't have long form notes on:
-
Hardware profiles: Shipping hardware-specific configuration for PipeWire and WirePlumber is hard. We discussed some approaches using context properties and conditions, but this is an area that needs more work.
-
Data loop management: PipeWire allows splitting work across data loops so different nodes in a graph can be assigned to different threads. This is currently an all-or-nothing system, where either all nodes go to a single data loop, or every node must be manually assigned a specific data loop. There was some desire to have the ability for there to be a default data loop to make the manual management less cumbersome.
-
ACP -> UCM: PipeWire inherits the ALSA card profile configuration from PulseAudio, which has been helpful in making the migration path smoother on most hardware. There was always some desire to have a single configuration system (probably ALSA UCM) for all hardware, but this likely needs some work on what we can express in UCM configuration, but we also need to clean up how we translate our UCM handling code (George has an RFC for this).
Thanks
That's it, thank you for reading if you made it this far, and a shout out to George, Mark, and others organising the event!
It was great to see continued interest and so much exciting work that is yet to come. I hope to see more of the community in the next edition of the hackfest.
15 Jun 2026 2:23am GMT