13 Jun 2026
 Planet KDE | English
Planet KDE | English
KDE Android News (June 2026)
Quite a few things have happened around the Android platform support for KDE applications in recent months, so high time for another update on that.
Qt 6.11
As already mentioned previously, we have updated the Qt version to 6.11. That has the unfortunate consequence of losing support for Android 8 and older. Due to that we also removed the ARM32 builds, as devices running Android 9 or higher are very likely capable of using ARM64 builds anyway, cutting down the CI cost by a third.
The previously often annoying interactions between input focus and the virtual keyboard seems to have improved somewhat with Qt 6.11. Changes in how the back key/gesture is handled however also caused a few regressions, like a double page pop in more deeply nested applications (Kirigami MR 2100).
SafeArea support
While the previous focus of dealing with "safe" screen areas (ie. parts of the application window not being covered by screen cutouts or system controls like the Android status and navigation bars) had been on not breaking horribly due to Android's changed default behavior we have meanwhile been working on polishing this to actually look decent.
- Fixed misplaced drawer handles (Kirigami MR 2102).
- Fixed NeoChat's chat bar being placed behind the bottom navigation bar (NeoChat MR 2893).
- Fixed a double bottom margin in NeoChat (Kirigami MR 2107).
- Fixed floating buttons in Itinerary getting misplaced (Kirigami MR 2105).
- Fixed Alligator global drawer expanding into the status bar (Alligator MR 172).
- Fixed runtime warnings in Tokodon when computing safe margins (Kirigami MR 2110).
If you spot places where this still doesn't work correctly, let us know in the #kde-android Matrix channel!
Notifications
There's also a number of improvements and extensions for notification handling:
- Fixed interactions with notification actions or the notification itself having no effect (MR 200).
- Implemented confirming inline replies (MR 202). This fixes the notification showing a spinner animation indefinitely after submitting an inline reply.
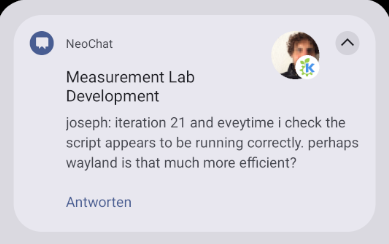
- Improved icon handling. We can now properly distinguish between what Android calls the "small" and "big" notification icons, a symbolic application icon and an image of e.g. a chat avatar. This will require small changes to applications to get the best result, in most cases providing a symbolic application icon should be enough already (MR 201).
- A new API for cross-platform notification configuration is in review (MR 203). This will also benefit Flatpak applications.
Safe JNI usage
Interaction between our C++ code and Android's Java platform APIs happens via the so-called Java Native Interface (JNI). That's a rather low-level C interface with little to no type safety and the need for error-prone handwritten arcane signature strings. Already back in the Qt 5 era I had therefore written a few helpers for a more type-safe use of this in KAndroidExtras.
Much of this functionality is meanwhile available in Qt 6 in a very similar fashion, with the JNI array support being the latest addition in Qt 6.9. Compared to raw JNI use this is already a massive improvement, see e.g. MR 204 making use of this in KNotifications. It avoids practically all hand-written JNI signatures as well as much of the manual type conversion.
One part is still missing though, type-safe wrappers so that function arguments and property types are checked at compile-time. That has been extracted and rebased on top of Qt's JNI code in KJniExtras now. It's only 10% of the code, with most of the complex template magic gone.
As a small downside we are unfortunately losing the ability to test JNI code on Linux with this, as the old approach provided a mock implementation when not building for Android.
Calendar access
With the type-safe JNI wrappers small enough now to be copied as a single header file, this finally unblocked the move of the Android platform calendar backend from Itinerary upstream to KCalendarCore (MR 242).
Together with the calendar runtime permission API already in Qt, this should make e.g. an "add to calendar" feature for Kongress or KTrip easy to add now.
File dialogs and remote files
An often reported issue against several of our applications is that they seemingly don't do anything when opening a file via the platform file dialog. This happens for files on a cloud share, which the Qt Quick file dialog silently discards due to not being local files, making this look like as if the user has canceled the dialog to the application. Therefore just nothing happens and no error message is shown either.
Interestingly enough, that problem also happens on KDE Plasma, where the native file dialog also can select remote files, it's just much less common there. But since we can tell the Plasma file dialog to only allow selecting local files, this one is easy to fix (CR 742273, available in Qt 6.12).
On Android we don't have that option, nor would that be really satisfying anyway, opening files from a cloud share is a very valid usecase. Therefore there's now also a proposed change to the Qt Quick file dialog to optionally allow selecting arbitrary URLs, similar to what its Qt Widgets counter-part already offers (CR 743681). This wont automatically fix the problem, but it would at least give applications a chance to do something about this.
Locale-aware sorting
Something fairly basic that Qt on Android so far didn't do properly (at least when not bundling it with multi-10MB worth of ICU libraries) was locale-aware sorting. When using English you might not notice that, but in many other languages this results in weird and confusing lists. In German for example the letter "Ä" gets basically treated like "A" for sorting, while so far it ended up after "Z" on Android.
There's now a proposed Qt patch (CR 741548) implementing a QCollator backend for Android using platform infrastructure. This uses Android's native ICU flavor when available and otherwise falls back to the less efficient and less featureful Java API.

Crash reporting
While we have automatic crash reporting on Linux since some time (see e.g. Harald's LAS talk for more details), crashes on Android were not handled at all by our applications so far.
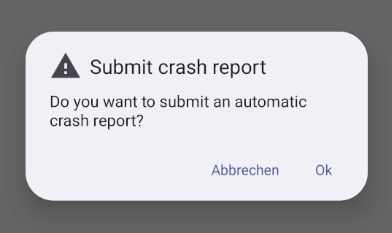
Based on discussions at the Graz Sprint in April this has now changed, KCrash can now detect a previous crash when starting an application, and offers to submit an automatic crash report to KDE's Sentry instance.
Those reports have been very helpful on Linux already, providing very important information about issues and allowing to prioritize those with the most impact, but it's nevertheless crucial we don't submit anything without user consent.
The bulk of the implementation is in KCrash MR 101, a few changes are necessary for integrating this into applications as well though.
In your build.gradle, add sentry-android-core as a dependency:
dependencies {
...
implementation 'io.sentry:sentry-android-core:8.43.0'
}In your AndroidManifest.xml, add a meta-data entry configuring the Sentry DSN for your application:
<application ...>
<meta-data android:name="io.sentry.dsn" android:value="https://<token>@crash-reports.kde.org/<app-id>"/>
</application>And finally, remove the build system and preprocessor conditions excluding KCrash use on Android. Note that verifying this part is crucial, without KCrash you'll get the aggressive default behavior of Sentry, uploading without user consent.
Inhibition
Earlier this year KGuiAddons got a new API for inhibiting system actions such as locking the screen. The obvious usecase for this is a video player, but e.g. Itinerary uses this as well for ensuring your screen stays on while showing a barcode to be scanned at a ticket check.
Android platform support for this has also been added (MR 203), allowing the removal of corresponding code in applications.
Outlook
While all of that is good progress, things are likely about to change. Later this year Google is planning to roll out measures making it significantly harder to provide and install applications on Android.

For more information check out Keep Android Open, a campaign supported by the KDE e.V. among many other organizations.
Regardless of how this will eventually materialize, the direction is clear, Android isn't going to be a viable long-term platform for FOSS software, not even in its Google-free form. I have mostly considered it a stop-gap solution until Linux on the phone is ready anyway, so this is another reason to increase the effort into that direction.
13 Jun 2026 6:45am GMT
This Week in Plasma: 6.7 is Very Close!
Welcome to a new issue of This Week in Plasma!
This week the Plasma team put the finishing touches on Plasma 6.7 with another big push on bug fixing. It's looking really good for release next Tuesday!
As a result, some feature work and UI polishing started to trickle in for Plasma 6.8.
Check it out:
Notable new features
Plasma 6.8
Plasma Browser Integration now supports the Flatpak version of Microsoft Edge. (Conley Dawson, KDE Bugzilla #521109)
Notable UI improvements
Plasma 6.6.6
Window actions that involve the mouse wheel no longer respect your "natural scrolling" preference; we reasoned that in this situation, up should always mean up and down should always mean down. (Vlad Zahorodnii and David Edmundson, KDE Bugzilla #442789)
Plasma 6.7
If you authorize an app to be able to remote-control the system without asking for permission first (for example, a remote desktop app), when it does so, now Plasma shows a notification that it's happening. (David Redondo, xdg-desktop-portal-kde MR #571)
When navigating by using the number pad keys to move the pointer, pressing multiple keys now moves the pointer in a direction halfway between them. (Vlad Zahorodnii, KDE Bugzilla #486520)
KRunner-powered searches now suppress results from the "Global Shortcuts" provider when there are better results from other ones, which makes the search results more relevant for common searches. (Oliver Beard, KDE Bugzilla #3710)
Changed the automatic day/night theme switcher to switch halfway between the start and end of dawn or dusk, rather than at the end. (Vlad Zahorodnii, Bugzilla #511973)
Added kde-shader-wallpaper to the list of allowed wallpaper plugins in Plasma Login Manager. (y4m y4m, plasma-login-manager MR #141)
Plasma 6.8
Improved Plasma's ability to detect dark GTK 2 themes and apply a matching icon theme, which should substantially reduce cases of illegible icons in old GTK 2 apps when using a dark color theme. (Luan Oliveira, kde-gtk-config MR #144)
The top edges of non-maximized Breeze-themed windows now have as much extra draggable area as the bottom and side edges already do. (Sergey Katunin, KDE Bugzilla #504225)
Made the portal-based permission dialogs more consistent in their presentation and wording. (Nate Graham, xdg-desktop-portal-kde MR #575)
Frameworks 6.28
You can now use the Meta key on its own to trigger KWin's Overview screen. (Vlad Zahorodnii, KDE Bugzilla #518302)
Improved the alignment of thumbnail previews in open/save dialogs. (John Doe, frameworks-kio MR #2249)
Notable bug fixes
Plasma 6.6.6
Fixed an issue that made KWin accidentally leak the CAP_SYS_NICE capability to child processes it launched, which would break the Bubblewrap sandboxing system when applied to those processes. (Vlad Zahorodnii, KDE Bugzilla #521013)
Fixed a bug that could make Plasma crash when changing the monitor layout during the login process. (Marco Martin, KDE Bugzilla #510477)
Fixed an issue that could make the "Today" button on the Digital Clock widget's calendar popup highlight the wrong day when in a time zone later than UTC and the local time was before midnight in UTC time. (Fushan Wen, KDE Bugzilla #521114)
The feature that lets apps screencast without asking permission no longer requires the screen setup to be identical to what it was when the permission was granted. (David Redondo, KDE Bugzilla #519122)
SVG-based wallpapers are now able to fully participate in the dark/light wallpaper switching feature. (David W., KDE Bugzilla #519168)
Fixed a bug that prevented explanatory text showing up as expected in the generic "[app] wants to do [thing]" portal dialog. (David Redondo, xdg-desktop-portal-kde MR #584)
Plasma 6.7
Fixed a very odd issue that would break the Icons-Only Task Manager widget if you created a file named metadata.desktop right inside your home folder. (Christoph Wolk, KDE Bugzilla #521247)
If you somehow manage to delete a multi-activity setup's active activity, Plasma now switches you to the next one instead of crashing and leaving you with a broken desktop. (Angel Parra, KDE Bugzilla #521124)
Fixed a case where Discover could crash while processing changes to distro packages. (Aleix Pol Gonzalez, discover MR #1335)
Fixed a case where Plasma could crash when waking from sleep after monitors were added or removed during sleep. (David Edmundson, KDE Bugzilla #https://bugs.kde.org/show_bug.cgi?id=521078)
Fixed a case where System Monitor would crash when quit while the column configuration dialog was open. (Nicolas Fella, KDE Bugzilla #491000)
Worked around an issue in GTK 4 that could make selected text in some GTK 4 apps become irritatingly de-selected. (Vlad Zahorodnii, KDE Bugzilla #517573)
Fixed a weird regression that could make the pointer inappropriately display the "app is launching" animation when minimizing windows using the Plastik window decoration style. (Vlad Zahorodnii, KDE Bugzilla #516264)
Fixed a regression that made non-random wallpaper slideshows start over from the first one at every login, instead of remembering the last-seen wallpaper. (Fushan Wen, KDE Bugzilla #512559)
Fixed a regression that made System Monitor's Process Table view display unformatted data. (Arjen Hiemstra, libksysguard MR #476)
Fixed a very weird issue that could make KWin get confused and stop running animations and animated effects properly after opening an app that creates an invisible window. (Vlad Zahorodnii, KDE Bugzilla #519789)
Fixed an issue that could sometimes make the Weather Report widget endlessly reload after waking the system from sleep. (Ce Sun, KDE Bugzilla #517280)
Made System Monitor graphs' axis labels show fractional values when needed. (Tobias Fella, KDE Bugzilla #521041)
Made it possible to un-favorite apps that are marked as favorites in Kickoff/Kicker/etc. even if they contain some weird character combinations. (Christoph Wolk, KDE Bugzilla #520894)
Fixed an issue that could make the notification icon in the System Tray get stuck in a half-rotated state if the animation got interrupted for any reason. (Kai Uwe Broulik, KDE Bugzilla #458156)
Fixed an issue that made a translated label turn into an English label after changing and saving settings on System Settings' Screen Locking page. (Sergey Katunin, KDE Bugzilla #521293)
Made the Color Picker widget not visually overflow when placed inside a Grouping widget. (Tobias Fella, KDE Bugzilla #517052)
Frameworks 6.28
Fixed a weird issue that could make Plasma freeze if you created a .desktop file, set its icon to be a local AVIF image, and put it on the desktop. (Akseli Lahtinen, KDE Bugzilla #521200)
Qt 6.11.2
Fixed an apparently fairly common way that Plasma could crash when fetching album art for remote media (for example, on YouTube) shown in Media Player widgets. (Mårten Nordheim, KDE Bugzilla #505490)
How you can help
KDE has become important in the world, and your time and contributions have helped us get there. As we grow, we need your support to keep KDE sustainable.
Would you like to help put together this weekly report? Introduce yourself in the Matrix room and join the team!
Beyond that, you can help KDE by directly getting involved in any other projects. Donating time is actually more impactful than donating money. Each contributor makes a huge difference in KDE - you are not a number or a cog in a machine! You don't have to be a programmer, either; many other opportunities exist.
You can also help out by making a donation! This helps cover operational costs, salaries, travel expenses for contributors, and in general just keeps KDE bringing Free Software to the world.
To get a new Plasma feature or a bug fix mentioned here
Push a commit to the relevant merge request on invent.kde.org.
13 Jun 2026 12:00am GMT
12 Jun 2026
Planet KDE | English
Web Review, Week 2026-24
Let's go for my web review for the week 2026-24.
Total Reciprocity Public License
Tags: tech, foss, licensing, copyright
More an experiment than something I'd recommend for real. Still it shows there's a gap we need to close in the licenses available. Let's hope the OSI and the FSF will do strong moves toward closing this gap.
Forms of Open Source Government
Tags: tech, foss, governance, satire
In part useful, in part satire I think. Still it gives a good idea of various governance models in FOSS communities.
https://nesbitt.io/2026/06/09/forms-of-open-source-government.html
Retro-Tech Parenting
Tags: tech, culture, learning, parenting
There's a path to get people (children included) to get into technology with enough of the veneer of convenience to make sure it is a learning experience… While keeping it pleasurable.
https://havenweb.org/2026/05/28/retro-tech.html
Pokémon Go Scans Quietly Trained The Navigation Tech Now Headed Into Military Drones
Tags: tech, game, surveillance, attention-economy, defense
How do you like our particular brand of dystopia? That's what you get for using proprietary data farming game I guess.
https://dronexl.co/2026/06/09/pokemon-go-scans-niantic-vantor-military-drone-navigation/
The Blight Reaches Microsoft: 73 Repos Disabled in 105 Seconds
Tags: tech, microsoft, github, security, supply-chain, ai, machine-learning, gpt, copilot
There's really something nasty at play. Those coding agents are clearly not insulated from the system enough and too easy to manipulate in order to exfiltrate sensitive information.
https://opensourcemalware.com/blog/miasma-reaches-azure
our workplace LLM mass delusion
Tags: tech, ai, machine-learning, gpt, management, trust
This piece asks a very profound question in fact. If you're in a workplace where senior management allows and pushes everyone to get deluded about the real capabilities of those tools, how do you later move forward and rebuild trust?
https://blog.avas.space/llm-circus/
To my students
Tags: tech, learning, culture, ethics, politics, quality
Very nice piece, timely and needed. Indeed, let's hope people stick to those principles.
http://ozark.hendrix.edu/~yorgey/forest/00FD/index.xml
How LLMs Actually Work
Tags: tech, ai, machine-learning, gpt, architecture, neural-networks
A good primer on the main architecture traits of transformer models.
https://www.0xkato.xyz/how-llms-actually-work/
Local-First Software Is Easier to Scale
Tags: tech, performance, architecture
It's definitely easier not having to scale at all. Which is what you get when you design for local first / client side.
https://elijahpotter.dev/articles/local-first-software-is-easier-to-scale
Linux latency measurements and compositor tuning
Tags: tech, graphics, linux, desktop, performance, debugging
Interesting read, this is really tricky to measure such latency. It looks like we might have room for improvements on latency still. Curious to see if the proposed fixes will make it in kwin.
https://farnoy.dev/posts/linux-latency
Test-case Reducers Are Underappreciated Debugging Tools
Tags: tech, tests, debugging
Interesting family of testing and debugging tools indeed. I should definitely reach out to those more.
https://tratt.net/laurie/blog/2026/test_case_reducers_are_underappreciated_debugging_tools.html
Why Queues Don't Fix Overload (And What To Do Instead)
Tags: tech, queuing, architecture, distributed
Queues are not magic. If they're unbounded you're in for a world of pain as load increases.
https://pmbanugo.me/blog/why-queues-dont-fix-overload-and-what-to-do-instead
The User Doesn't Care - But you should
Tags: tech, programming, quality
Indeed, when people say "users don't care about quality" (tests or otherwise), this is mostly folklore. As soon as something goes wrong they'll care.
https://lewiscampbell.tech/blog/260607.html
The un-hateable engineering managers
Tags: tech, engineering, management
Sometimes, you got to deliver the bad news… It's healthy if you feel uneasy about it though.
https://newsletter.manager.dev/p/the-un-hateable-engineering-managers
Bye for now!
12 Jun 2026 12:30pm GMT