11 Apr 2026
 Planet Grep
Planet Grep
Lionel Dricot: Ne rien avoir à penser

Ne rien avoir à penser
Après le « Je n'ai rien à cacher », voici venu l'ère du « Je n'ai rien à penser »
Se faire prendre pour des crétins parce que ça fonctionne
Google l'annonce : il y a plus de personnes dans le monde avec un smartphone Android que de personnes qui ont accès à de l'eau propre et des égouts.
Cela implique, toujours selon Google, qu'il faut plus d'IA pour ces personnes.
Non, sérieusement, je ne déconne pas. C'est vraiment ce que les gens de Google vont raconter dans les universités dans des événements qui ressemblent un peu à ce que des vendeurs de cigarettes pourraient organiser dans des clubs de sport pour former la jeunesse à fumer en offrant un an de cigarettes gratuites.
Et ils enfoncent le clou: de toute façon, personne n'a le choix d'utiliser l'IA ou non. C'est comme ça. Exactement ce que disait Anthropic: « Que vous le vouliez ou non, préparez-vous pour ce monde stupide ! »
Mon exemple du vendeur de cigarettes semble exagéré, mais je viens d'être témoin, dans ma ville universitaire de Louvain-La-Neuve, d'une compétition qui consistait à faire le tour du lac en courant tout en buvant quatre bières de 33cl. La course était sponsorisée par… une marque de bière, bien entendu. L'université semble avoir donné sa bénédiction pour cet événement et beaucoup d'étudiants sont assez naïfs pour trouver ça cool…
Je suis moi-même un grand naïf. Je croyais que les personnes étaient majoritairement moralement « bonnes ». Elles produisent souvent un impact négatif lorsqu'elles travaillent à maximiser le profit d'une entreprise. C'est juste qu'elles ne s'en rendent pas compte.
Mais c'est faux. Nous savons aujourd'hui que des personnes comme Mark Zuckerberg sont tout simplement moralement inhumaines et que toutes les personnes impliquées savent très bien ce qu'elles font et pourquoi elles le font. Les produits Meta sont spécifiquement modifiés pour rendre les adolescents les plus addicts possibles, pour les perturber durant leur scolarité. Ce n'est pas une conséquence, c'est le but premier du produit. La distraction incessante n'est pas un effet insoupçonné, c'est littéralement ce que cherchent à faire les ingénieurs de Facebook.
Et dire que la plupart des profs sont en mode : « Il faut vivre avec, il faut apprendre à utiliser raisonnablement ».
Non. C'est faux et c'est complètement stupide. C'est comme donner aux adolescents des formations, sponsorisées par Philip Morris, où ils apprendraient à fumer « sans inhaler la fumée ». Ou leur dire que c'est cool de courir en buvant plus de bières que ton estomac ne peut en supporter.
La vérité c'est que la plupart des profs sont complètement addicts à leur smartphone et que c'est plus rassurant d'enseigner son addiction comme un truc positif que de se remettre en question.
La pub nous prend pour des crétins. Elle prend les politiciens pour des crétins. Et, expérimentalement parlant, elle a bien raison. Nous le sommes ! Ça fonctionne encore mieux que prévu parce que, du coup, nous allons leur donner raison et soutenir ceux qui se foutent de notre gueule !
Regardez le RGPD et les bannières de cookies qui ennuient tout le monde et pour lesquelles on accuse « l'Europe ».
Contrairement à une idée reçue, les ennuyeuses bannières de cookies sur les sites ne sont pas la faute du RGPD. D'ailleurs, dans l'immense majorité des cas, ces bannières sont illégales. Gee l'explique très bien en BD :
Mais il y a pire : si ces bannières sont ennuyeuses, c'est parce qu'elles ont été explicitement conçues pour ça. Et oui, pour faire baisser le degré d'adhésion du peuple envers le RGPD. C'est une pure manipulation politique volontaire et consciente de l'industrie publicitaire. Ils savent très bien ce qu'ils font : nous pourrir la vie pour décrédibiliser les institutions politiques afin de nous fourguer plus de pub.
La fin de l'intellectualisme
Un article important sur le retour à l'oralité et le déclin de la lecture. L'oralité, c'est l'émotion au lieu de l'information, c'est le charisme au lieu de la vérité, c'est la manipulation au lieu de la rationalité. C'est également la disparition de l'effort sur le long terme.
Cela semble alarmiste, mais, factuellement, lorsque les chercheurs scientifiques, censés représenter l'élite intellectuelle du monde, en sont réduits à générer des articles qui citent des articles qui n'existent pas, cela pose quand même des questions.
Oui, c'est la fin du monde, la fin d'un monde !
Mais ChatGPT n'est que la cerise sur le gâteau. La raison réelle, c'est que nous dévalorisons l'intellectualité depuis des décennies. Nous valorisons le CEO qui prend des décisions aléatoires en 5 minutes. Nous demandons à tout le monde de creuser des trous et de les reboucher pour « faire tourner l'économie ». Nous vivons dans un monde où Julius grimpe les échelons !
Bref, nous ne faisons que mener le monde vers sa destination la plus logique en regard des indicateurs que nous utilisons pour l'optimiser. C'est tout à fait normal. C'est tout à fait attendu. On ne réduira jamais les émissions de CO₂ tant qu'on tentera de maximiser le PIB d'un pays. Faire tourner l'économie implique de maximiser le travail et donc de consommer le plus de joules possible. Joules qu'il faut produire en émettant du CO₂. Les énergies dites « renouvelables » ne sont qu'une manière d'émettre « moins de CO₂ par joule ». Ce qui est une bonne chose en soi, mais ne résout pas le problème de base que nous cherchons justement à consommer le plus de joules possible. Le résultat du succès des énergies renouvelables est d'ailleurs évident : nous consommons plus de joules, tout simplement.
Nous sommes en train de connaître la fin de l'intellectualité comme nous avons traversé la fin de la vie privée. Non, ce n'est pas réellement la fin. C'est juste que l'intellectualité, tout comme la vie privée avant elle, a perdu son statut de valeur fondamentale pour devenir un truc underground, uniquement valorisée par quelques cercles de plus en plus considérés comme marginaux, y compris, surtout, au sein des plus prestigieuses institutions académiques.
« Je n'ai rien à cacher » s'est subtilement transformé en « Je n'ai rien à penser ».
Depuis les smartphones à ChatGPT en passant par les séries en streaming, les géants technologiques se sont ligués pour nous convaincre de ne plus penser, que penser est has been, que c'est fatigant, que ça ne sert à rien. Nul besoin d'avoir un doctorat en sciences politiques pour comprendre que ça arrange beaucoup de monde.
Ma défense : l'effet bibliothèque
Les chatbots ne font, au fond, qu'augmenter la disponibilité de l'information, y compris fausse. Cette disponibilité réduit l'engagement cognitif et donc le développement du cerveau. Cet effet était déjà visible et étudié en 2011 comme "l'effet Google". Si nous savons qu'une information est disponible en ligne, nous ne tentons plus de nous la rappeler, nous la cherchons (combien de fois avez-vous pris votre téléphone parce que vous ne vous souveniez plus du nom d'un acteur dans un film?)
Ce qui est amusant à constater c'est que, bien avant d'avoir lu ces études, j'ai instinctivement adopté la posture inverse depuis quelques années. Je me refuse de chercher immédiatement une info. Ma motivation était de ne pas interrompre une conversation en cours (je dissuade d'ailleurs mon interlocuteur de sortir son téléphone) ou ne pas interrompre mon travail en cours (je me connais, je sais que si je cherche l'info, je suis 30 minutes plus tard en train de lire la page Wikipédia consacrée à la biographie d'Henri IV ou à une espèce rare de méduse en Nouvelle-Calédonie).
On pourrait arguer qu'il en est de même avec une bibliothèque. Mais je vois des différences fondamentales.
Premièrement, il y a la composante physique : lorsque je cherche une information dans un livre, je me déplace, je cherche dans un rayon. Mon cerveau associe le mouvement avec la mémorisation. Ma bibliothèque a beau être fluide et mouvante, elle garde une structure. Avec le temps, se souvenir d'une information revient à se souvenir du déplacement à effectuer pour aller chercher le livre.
En second lieu, les informations dans les livres sont stables et figées. Elles peuvent être fausses, mais je sais qu'elles ne sont pas générées pour améliorer le SEO du livre ou obtenir des likes. Elles ne se transforment pas subitement en erreur 404.
Cette stabilité rassure mon cerveau. Celui-ci n'est pas dans la "perception", la tentative de comprendre un environnement changeant, ce qui est source de stress. Il est au contraire dans le familier et peut se permettre d'extrapoler, d'imaginer, de faire des liens imprévus.
Bref, je donne à mon cerveau la possibilité d'être créatif, je lui offre un espace stable où il peut expérimenter la mouvance et le changement dans ce qu'il crée : les mots, les histoires. Ce n'est pas un hasard si je n'écris que sur une machine à écrire ou depuis mon terminal dans un éditeur qui change très peu depuis 40 ans (Vim). Je veux libérer de l'espace mental pour créer et réfléchir.
Si vous avez déjà été dans une bibliothèque juste pour être au calme et réfléchir, vous voyez très bien ce que je veux dire.
Bref, je suis un technopunk ringard… Mais ça, vous le saviez déjà !
À propos de l'auteur :
Je suis Ploum et je viens de publier Bikepunk, une fable écolo-cycliste entièrement tapée sur une machine à écrire mécanique. Pour me soutenir, achetez mes livres (si possible chez votre libraire) !
Recevez directement par mail mes écrits en français et en anglais. Votre adresse ne sera jamais partagée. Vous pouvez également utiliser mon flux RSS francophone ou le flux RSS complet.
11 Apr 2026 6:35am GMT
Frederic Descamps: A response to Percona’s 2026 MySQL ecosystem benchmark: useful data, but not a realistic MariaDB comparison
 Percona's new 2026 benchmark report is interesting because it puts several MySQL-family releases on the same graphs and shares a public repository for the test harness. That openness is welcome. But after reading both the article and the published scripts, I do not think the post supports broad conclusions about "ecosystem performance," and I especially […]
Percona's new 2026 benchmark report is interesting because it puts several MySQL-family releases on the same graphs and shares a public repository for the test harness. That openness is welcome. But after reading both the article and the published scripts, I do not think the post supports broad conclusions about "ecosystem performance," and I especially […]
11 Apr 2026 6:35am GMT
Dries Buytaert: Introducing headers.dev

My HTTP Header Analyzer started as a small tool on my blog six years ago. It makes HTTP headers visible and explains what they do. You give it a URL, it fetches the response headers, and it breaks down what is present, what is missing, and what is possibly misconfigured.
It has been used more than 5 million times, despite being buried at https://dri.es/headers. So last week I finally registered headers.dev and gave it a proper home.
While I was at it, I also audited the analyzer against OWASP's recommendations for HTTP headers. I found a few gaps worth fixing. A site could have a Content Security Policy that included unsafe-inline and unsafe-eval, and the analyzer would describe each directive without mentioning that those two keywords effectively disable XSS protection. Or you could set HSTS with preload but forget includeSubDomains, which means your preload submission gets silently rejected. These are the kinds of issues a human reviewer might miss but an automated tool should catch. I fixed those and more, so if you've used the analyzer before, your scores might look different now.
The analyzer also learned about dozens of new headers. Speculation-Rules, for example, tells browsers to prerender pages a user is likely to visit next. Cache-Status replaces the patchwork of vendor-specific X-Cache headers with a single structured format that can describe multiple cache layers in one value. And Reporting-Endpoints is the modern replacement for Report-To, using a simpler key-value syntax for telling browsers where to send security violation reports.
Try it at headers.dev. It now explains over 150 headers and catches misconfigurations that it used to miss. The Open Web is better when more people check their HTTP headers.
11 Apr 2026 6:35am GMT
14 Apr 2026
Fedora People
Fedora Infrastructure Status: Matrix server maintenance
14 Apr 2026 11:15am GMT
11 Apr 2026
LXer Linux News
Calibre 9.7 E-Book Manager Released With Offline HTTPS Content Server Mode
Calibre 9.7 introduces full offline mode for HTTPS content server connections, improved annotations grouping, viewer zoom enhancements, and several bug fixes.
11 Apr 2026 6:07am GMT
Stacking Directories With "pushd" and "popd" Commands for Easy Navigation
The pushd and popd commands are ways to efficiently navigate between different directory paths by stacking them in memory and popping them out when they are required using the index number.
11 Apr 2026 4:36am GMT
Red Hat RHELocates its Chinese engineering team to India
Hundreds of layoffs, but this smells of geopolitics, not downsizingRed Hat appears to have fired its entire engineering team in China, which it no longer thinks is a country it needs to prioritize. Most of the team will move to India.…
11 Apr 2026 3:04am GMT
10 Apr 2026
Fedora People
Rénich Bon Ćirić: HowTo: Cómo instalar y anclar una versión específica con Flatpak

¿Te ha pasado que sale la actualización de tu software favorito y nomás no puedes saltar a ella? Pues resulta que Bitwig Studio llegó a su versión 6 y, pues, yo andaba sin chamba y sin feria para el upgrade.
Lo uso con Flatpak porque, la neta, yo mismo inicié, propuse y doné la primera implementación en Flathub. Total, me tuve que quedar en la versión 5.x y nunca había tenido que anclar una versión usando Flatpak.
Le pregunté a un LLM cómo hacerle (pa' qué le miento, compa) y me dió la respuesta. Así de fácil se hace:
Paso a paso
- Revisar el log:
-
Primero hay que ver qué versiones hay disponibles en el historial de Flathub.
flatpak remote-info --log flathub com.bitwig.BitwigStudio
- Instalar la versión deseada:
-
Copia el hash del commit que te interese e instálalo.
sudo flatpak update --commit=00535d779d2ebead55f129a406ed819064b7d3a28bd638aa25a0c8dda919197e com.bitwig.BitwigStudio
- Anclar (mask):
-
Esto es lo más importante para que no se te actualice por error la próxima vez que hagas un update general.
flatpak mask com.bitwig.BitwigStudio
No tiene chiste, ¿verdad? Con esto ya puedes estar tranquilo de que tu flujo de trabajo no se va a romper por una actualización que no pediste... o, mejor dicho, pa' la que no te alcanza. ;D
Sobre el software privativo
La neta, yo no soy muy partidario de estas cosas. Siempre recomiendo estar al día pero, con software privativo y que pagas por usar, pues no me quedó de otra. Estos batos de Bitwig no mantienen versiones anteriores de forma sencilla; hay que estar al día con ellos a huevo.
Note
A muchos les parecerá una patraña o una traición usar software no libre en Fedora. En mi caso, pasé varios años intentando grabar mis rolas con software libre. Nunca pude. No por falta de software sino, más que nada, por la falta de infraestructura.
Para grabar con puro Open Source como Ardour, que es una chulada, necesitas un estudio pro: micros, batería, un baterista y que todos tengan tiempo. Como yo soy bien huevón para coordinar gente, si no hago las cosas en el momento, ya no las hice. Bitwig Studio me resuelve la vida porque ya trae todo el arsenal: samples, instrumentos y FX de súper buena calidad.
Al menos no tengo que usar Windows. Es mucho más de lo que tuve en los 2000s con el buen Renoise o LMMS. El flujo de trabajo importa bastante, y aunque en GNU/Linux hay plugins increíbles (como los Calf en LV2), armar una sesión estable era un pinche desmadre impráctico.
Conclusión
Ahí se las dejo, compas. Ojalá y a alguien le sirva este mini-howto para no andar batallando con las versiones de Flatpak. ¡A seguirle dando a la música!
10 Apr 2026 8:30pm GMT
Planet KDE | English
Analyzing KDE Project Health With git!
I was reading the latest edition of Kevin Ottens' excellent weekly web review and one particular article caught my eye: "The Git Commands I Run Before Reading Any Code". In a nutshell, you can use the git version control tool to quickly assess a project's health, what breaks, who's a key figure, how bad emergencies are, and so on.
So useful!
I immediately wanted to apply this to KDE projects. So I took the commands from the post and made some shell aliases and functions for convenience:
# git repo analysis toolsalias what-changes="echo 'What changes a lot?' && git log --format=format: --name-only --since='1 year ago' | rg -v 'po$|json$|desktop$' | sort | uniq -c | sort -nr | head -20"alias what-breaks="echo 'What breaks a lot?' && git log -i -E --grep='fix|bug|broke|bad|wrong|incorrect|problem' --name-only --format='' | sort | uniq -c | sort -nr | head -20"alias emergencies="echo 'And what were the emergencies?' && git log --oneline --since='1 year ago' | grep -iE 'revert|hotfix|emergency|urgent|rollback'"alias momentum="echo \"What's the project's momentum over the past 5 years?\" && git log --format='%ad' --date=format:'%Y-%m' | sort | uniq -c | tail -n 60"alias maintainers-recently="echo \"Who's been driving this project in the past year?\" && git shortlog -sn --no-merges --since='1 year ago' | rg -v 'l10n daemon script' | head -n 30"alias maintainers-alltime="echo 'And what about for all time?' && git shortlog -sn --no-merges | rg -v 'l10n daemon script' | head -n 30"function repo-analysis {what-changesechowhat-breaksechoemergenciesechomomentumechomaintainers-recentlyechomaintainers-alltime}Now let's run it on Plasma. Here's plasma-workspace, the core of Plasma:
$ git clone ssh://git@invent.kde.org/plasma/plasma-workspace.git
$ cd plasma-workspace
$ repo-analysis
What changes a lot?
1519
38 CMakeLists.txt
29 shell/shellcorona.cpp
24 runners/services/servicerunner.cpp
21 wallpapers/image/imagepackage/contents/ui/config.qml
19 libnotificationmanager/notifications.cpp
18 shell/org.kde.plasmashell.desktop.cmake
18 devicenotifications/devicenotifications.cpp
17 kcms/lookandfeel/kcm.cpp
16 wallpapers/image/plugin/model/packagelistmodel.cpp
16 kcms/cursortheme/xcursor/xcursor.knsrc
15 wallpapers/image/plugin/model/imagelistmodel.cpp
15 applets/notifications/global/Globals.qml
15 applets/devicenotifier/devicecontrol.cpp
14 wallpapers/image/plugin/imagebackend.cpp
14 shell/panelview.cpp
14 .kde-ci.yml
14 applets/systemtray/systemtray.cpp
13 runners/services/autotests/servicerunnertest.cpp
12 krunner/qml/RunCommand.qml
What breaks a lot?
225 shell/shellcorona.cpp
183 shell/panelview.cpp
83 CMakeLists.txt
74 applets/systemtray/package/contents/ui/main.qml
71 applets/digital-clock/package/contents/ui/DigitalClock.qml
63 klipper/klipper.cpp
62 applets/notifications/package/contents/ui/NotificationItem.qml
58 wallpapers/image/imagepackage/contents/ui/config.qml
56 shell/desktopview.cpp
56 libtaskmanager/tasksmodel.cpp
54 shell/main.cpp
54 applets/systemtray/systemtray.cpp
53 shell/shellcorona.h
52 krunner/view.cpp
48 applets/digital-clock/package/contents/ui/CalendarView.qml
47 runners/services/servicerunner.cpp
46 wallpapers/image/imagepackage/contents/ui/main.qml
45 applets/notifications/package/contents/ui/NotificationPopup.qml
44 applets/systemtray/package/contents/ui/ExpandedRepresentation.qml
43 startkde/startplasma.cpp
And what were the emergencies?
4f526a7bd1 Revert "applets/systemtray: Prevent popups from overlapping with the panel"
dca5788fee lookandfeel/components: Revert Plasma::setupPlasmaStyle
2c0fd34541 Revert "ContainmentLayoutManager: send recursive mouse release events too"
b6b230f4ff Revert "Read selenium-webdriver-at-spi-run location from CMake"
b8651b56f6 hotfix: Remove doc translations without actual doc
1f43f576e8 Revert "Add forceImageAnimation property to force animated image play"
f0349b6c81 hotfix: remove stray .po file
3ff7ae4269 Revert "CI: enable parallel testing"
83bebc7896 Revert "Limit evaluateScript execution at 2 seconds"
4f45f672be Revert "kcms/componentchooser: Don't offer NoDisplay services"
3bf0ff8f56 Revert "Disable linux-qt6-next while the regression in Qt gets fixed"
80996f0633 Revert "kcms/wallpaper: set roleNames for WallpaperConfigModel"
What's the project's momentum over the past 5 years?
148 2021-05
87 2021-06
62 2021-07
85 2021-08
121 2021-09
106 2021-10
146 2021-11
190 2021-12
191 2022-01
84 2022-02
168 2022-03
130 2022-04
146 2022-05
141 2022-06
136 2022-07
107 2022-08
232 2022-09
234 2022-10
181 2022-11
150 2022-12
154 2023-01
161 2023-02
156 2023-03
156 2023-04
163 2023-05
137 2023-06
186 2023-07
190 2023-08
275 2023-09
226 2023-10
283 2023-11
157 2023-12
131 2024-01
147 2024-02
249 2024-03
180 2024-04
188 2024-05
158 2024-06
128 2024-07
146 2024-08
169 2024-09
156 2024-10
116 2024-11
98 2024-12
145 2025-01
126 2025-02
120 2025-03
116 2025-04
131 2025-05
131 2025-06
132 2025-07
115 2025-08
110 2025-09
97 2025-10
147 2025-11
114 2025-12
140 2026-01
131 2026-02
119 2026-03
44 2026-04
Who's been driving this project in the past year?
116 Vlad Zahorodnii
113 Nicolas Fella
87 Christoph Wolk
82 Fushan Wen
78 Nate Graham
66 Kai Uwe Broulik
48 Bohdan Onofriichuk
37 Harald Sitter
34 Tobias Fella
31 Marco Martin
30 David Edmundson
25 Akseli Lahtinen
21 Ismael Asensio
17 David Redondo
16 Niccolò Venerandi
15 Bhushan Shah
11 Alexander Lohnau
11 Kristen McWilliam
9 Oliver Beard
9 Shubham Arora
8 Alexey Rochev
8 Han Young
8 Philipp Kiemle
7 Albert Astals Cid
6 Aleix Pol
6 Méven Car
5 Devin Lin
5 Joshua Goins
4 Alexander Wilms
4 Arjen Hiemstra
And what about for all time?
1543 Fushan Wen
1497 Marco Martin
1374 Kai Uwe Broulik
1030 David Edmundson
772 Nate Graham
658 Alexander Lohnau
551 Aleix Pol
548 Nicolas Fella
438 ivan tkachenko
385 Eike Hein
264 Sebastian Kügler
250 Martin Gräßlin
238 Harald Sitter
232 Martin Klapetek
223 Jonathan Riddell
207 Vlad Zahorodnii
194 David Redondo
190 Friedrich W. H. Kossebau
189 Laurent Montel
144 Bhushan Shah
134 Christoph Wolk
134 Ismael Asensio
126 Lukáš Tinkl
121 Niccolò Venerandi
117 Méven Car
105 Natalie Clarius
91 Konrad Materka
80 Vishesh Handa
80 Volker Krause
79 Ivan Čukić
ShellCorona both changing and breaking a lot is no great surprise to me; it's fiddly and complicated. We need to do something about that. The number of emergencies doesn't look too bad, and momentum feels fine too. The project also appears to have a nice healthy diversity of contributors. Excellent!
It's been quite illuminating to run these tools on KDE projects that I'm both more and less familiar with. Give it a try!
10 Apr 2026 8:24pm GMT
Linuxiac
Debian 13 Stable Users Can Now Install Hyprland from Backports

Hyprland arrives in Debian 13 (Trixie) backports, giving stable users an official way to install the dynamic Wayland compositor.
10 Apr 2026 5:05pm GMT
Planet Debian
Reproducible Builds: Reproducible Builds in March 2026
Welcome to the March 2026 report from the Reproducible Builds project!

These reports outline what we've been up to over the past month, highlighting items of news from elsewhere in the increasingly-important area of software supply-chain security. As ever, if you are interested in contributing to the Reproducible Builds project, please see the Contribute page on our website.
- Linux kernel hash-based integrity checking proposed
- Distribution work
- Tool development
- Upstream patches
- Documentation updates
- Two new academic papers
- Misc news
Linux kernel hash-based integrity checking proposed

Eric Biggers posted to the Linux Kernel Mailing List in response to a patch series posted by Thomas Weißschuh to introduce a calculated hash-based system of integrity checking to complement the existing signature-based approach. Thomas' original post mentions:
The current signature-based module integrity checking has some drawbacks in combination with reproducible builds. Either the module signing key is generated at build time, which makes the build unreproducible, or a static signing key is used, which precludes rebuilds by third parties and makes the whole build and packaging process much more complicated.
However, Eric's followup message goes further:
I think this actually undersells the feature. It's also much simpler than the signature-based module authentication. The latter relies on PKCS#7, X.509, ASN.1, OID registry,
crypto_sigAPI, etc in addition to the implementations of the actual signature algorithm (RSA / ECDSA / ML-DSA) and at least one hash algorithm.
Distribution work

In Debian this month,
-
Lucas Nussbaum announced Debaudit, a "new service to verify the reproducibility of Debian source packages":
debaudit complements the work of the Reproducible Builds project. While reproduce.debian.net focuses on ensuring that binary packages can be bit-for-bit reproduced from their source packages, debaudit focuses on the preceding step: ensuring that the source package itself is a faithful and reproducible representation of its upstream source or
Vcs-Gitrepository. -
kpcyrd filed a bug against the
librust-const-random-devpackage reporting that thecompile-time-rngfeature of theahashcrate uses theconst-randomcrate in turn, which uses a macro to read/generate a random number generator during the build. This issue was also filed upstream. -
60 reviews of Debian packages were added, 4 were updated and 16 were removed this month adding to our knowledge about identified issues. One new issue types was added,
pkgjs_lock_json_file_issue.

Lastly, Bernhard M. Wiedemann posted another openSUSE monthly update for their work there.
Tool development

diffoscope is our in-depth and content-aware diff utility that can locate and diagnose reproducibility issues. This month, Chris Lamb made a number of changes, including preparing and uploading versions, 314 and 315 to Debian.
-
Chris Lamb:
-
Jelle van der Waa:
-
Michael R. Crusoe:
In addition, Vagrant Cascadian updated diffoscope in GNU Guix to version 315.

rebuilderd, our server designed monitor the official package repositories of Linux distributions and attempt to reproduce the observed results there; it powers, amongst other things, reproduce.debian.net.
A new version, 0.26.0, was released this month, with the following improvements:
- Much smoother onboarding/installation.
- Complete database redesign with many improvements.
- New REST HTTP API.
- It's now possible to artificially delay the first reproduce attempt. This gives archive infrastructure more time to catch up.
- And many, many other changes.
Upstream patches
The Reproducible Builds project detects, dissects and attempts to fix as many currently-unreproducible packages as possible. We endeavour to send all of our patches upstream where appropriate. This month, we wrote a large number of such patches, including:
-
Bernhard M. Wiedemann:
minify(rust random HashMap) / (alternative by kpcyrd)rpm-config-SUSE(toolchain)
-
Chris Lamb:
- #1129544 filed against
python-nxtomomill. - #1130622 filed against
dh-fortran. - #1130623 filed against
python-discovery. - #1130666 filed against
kanboard. - #1131168 filed against
moltemplate. - #1131384 filed against
stacer. - #1131385 filed against
libcupsfilters. - #1131395 filed against
django-ninja. - #1131403 filed against
python-agate. - #1132074 filed against
aetos. - #1132508 filed against
python-bayespy.
- #1129544 filed against
-
kpcyrd:
Documentation updates

Once again, there were a number of improvements made to our website this month including:
-
kpcyrd:
-
Robin Candau:
-
Timo Pohl:
- Add new From Constrictor to Serpent: Investigating the Threat of Cache Poisoning in the Python Ecosystem paper to the Academic publications page. […]
- Add GitLab registration confirmation to How to join the Salsa group page. […]
Two new academic papers

Marc Ohm, Timo Pohl, Ben Swierzy and Michael Meier published a paper on the threat of cache poisoning in the Python ecosystem:
Attacks on software supply chains are on the rise, and attackers are becoming increasingly creative in how they inject malicious code into software components. This paper is the first to investigate Python cache poisoning, which manipulates bytecode cache files to execute malicious code without altering the human-readable source code. We demonstrate a proof of concept, showing that an attacker can inject malicious bytecode into a cache file without failing the Python interpreter's integrity checks. In a large-scale analysis of the Python Package Index, we find that about 12,500 packages are distributed with cache files. Through manual investigation of cache files that cannot be reproduced automatically from the corresponding source files, we identify classes of reasons for irreproducibility to locate malicious cache files. While we did not identify any malware leveraging this attack vector, we demonstrate that several widespread package managers are vulnerable to such attacks.
A PDF of the paper is available online.

Mario Lins of the University of Linz, Austria, has published their PhD doctoral thesis on the topic of Software supply chain transparency:
We begin by examining threats to the software distribution stage - the point at which artifacts (e.g., mobile apps) are delivered to end users - with an emphasis on mobile ecosystems [and] we next focus on the operating system on mobile devices, with an emphasis on mitigating bootloader-targeted attacks. We demonstrate how to compensate lost security guarantees on devices with an unlocked bootloader. This allows users to flash custom operating systems on devices that no longer receive security updates from the original manufacturer without compromising security. We then move to the source code stage. [Also,] we introduce a new architecture to ensure strong source-to-binary correspondence by leveraging the security guarantees of Confidential Computing technology. Finally, we present The Supply Chain Game, an organizational security approach that enhances standard risk-management methods. We demonstrate how game-theoretic techniques, combined with common risk management practices, can derive new criteria to better support decision makers.
A PDF of the paper is available online.
Misc news
On our mailing list this month:
-
Holger Levsen announced that this year's Reproducible Builds summit will almost certainly be held in Gothenburg, Sweden, from September 22 until 24, followed by two days of hacking. However, these dates are preliminary and not 100% final - an official announcement is forthcoming.
-
Mark Wielaard posted to our list asking a question on the difference between
debugeditand relative debug paths based on a comment on the Build path page: "Have people tried more modern versions ofdebugeditto get deterministic (absolute) DWARF paths and found issues with it?
Finally, if you are interested in contributing to the Reproducible Builds project, please visit our Contribute page on our website. However, you can get in touch with us via:
-
IRC:
#reproducible-buildsonirc.oftc.net. -
Mastodon: @reproducible_builds@fosstodon.org
-
Mailing list:
rb-general@lists.reproducible-builds.org
10 Apr 2026 4:13pm GMT
OMG! Ubuntu
Ghostty terminal is now available in the Ubuntu repos
![]() The Ghostty terminal is now packaged in the Ubuntu 26.04 LTS repositories - meaning for those on the new long-term support release, it's only an apt install away. Ghostty is a fast, open-source terminal emulator for macOS and Linux (Windows support is seemingly trapped between planes), made by Mitchell Hashimoto. It's picked up millions of users since its launch in December 2024, and has been available on Ubuntu via a community-maintained PPA, DEB and Snap packages for a while. This is its first appearance in the Ubuntu repos proper. What makes Ghostty different? "Ghostty is a fast, feature-rich, and cross-platform […]
The Ghostty terminal is now packaged in the Ubuntu 26.04 LTS repositories - meaning for those on the new long-term support release, it's only an apt install away. Ghostty is a fast, open-source terminal emulator for macOS and Linux (Windows support is seemingly trapped between planes), made by Mitchell Hashimoto. It's picked up millions of users since its launch in December 2024, and has been available on Ubuntu via a community-maintained PPA, DEB and Snap packages for a while. This is its first appearance in the Ubuntu repos proper. What makes Ghostty different? "Ghostty is a fast, feature-rich, and cross-platform […]
You're reading Ghostty terminal is now available in the Ubuntu repos, a blog post from OMG! Ubuntu. Do not reproduce elsewhere without permission.
10 Apr 2026 3:36pm GMT
Planet Debian
Jamie McClelland: AI Hacking the Planet
A colleague asked me if we should move all our money to our pillow cases after reading the latest AI editorial from Thomas Friedman. The article reads like a press release from Anthropic, repeating the claim that their latest AI model is so good at finding software vulnerabilities that it is a danger to the world.
I think I now know what it's like to be a doctor who is forced to watch Gray's Anatomy.
By now every journalist should be able to recognize the AI publicity playbook:
Step 1: Start with a wildly unsubstantiated claim about how dangerous your product is:
AI will cause human extinction before we have a chance to colonize mars (remember that one? Even Kim Stanley Robinson, author of perhaps the most compelling science fiction on colonizing mars calls bull shit on it).
AI will eliminate all of our jobs (this one was extremely effective at providing cover for software companies laying off staff but it has quickly dawned on people that the companies that did this are living in chaos not humming along happily with functional robots)
AI will discover massive software vulnerabilities allowing bad actors to "hack pretty much every major software system in the world". (Did Friedman pull that directly from Anthropic's press release or was that his contribution?)
Step 2: To help stave off human collapse, only release the new version to a vetted group of software companies and developers, preferably ones with big social media followings
Step 3: Wait for the limited release developers to spew unbridled enthusiasm and shocking examples that seem to suggest this new AI produce is truly unbelievable
Step 4: Watch stock prices and valuations soar
Step 5: Release to the world, and experience a steady stream of mockery as people discover how wrong you are
Step 6: Start over
Even if Friedman missed the text book example of the playbook, I have to ask: if you think bad actors compromising software resulting in massive loss of private data, major outages and wasted resources needs to be reported on, then where have you been for the last 10 years? This literally happens on a daily basis due to the fundamentally flawed way capitalism has been writing software even before the invention of AI. A small part of me wonders - maybe AI writing software is not so bad, because how could it be any worse than it is now?
Also, let's keep in mind that AI's super ability at finding vulnerable software depends on having access to the software's source code, which most companies keep locked up tight. That means the owners of the software can use AI to find vulnerabilities and fix them but bad actors can't.
Oh, but wait, what if a company is so incompetent that they accidentally release their proprietary software to the Internet?
Surely that would allow AI bots to discover their vulnerabilities and destroy the company right? I'm not sure if anyone has discovered world ending vulnerabilities in Anthropic's Claude code since it was accidentally released, but it is fun to watch people mock software that is clearly written by AI (and spoiler alert, it seems way worse that software written now).
Well… we probably should all be keeping our money in a pillow case anyway.
10 Apr 2026 12:27pm GMT
Linuxiac
KDE Frameworks 6.25 Brings New Fixes and Developer Improvements

KDE Frameworks 6.25 is out now with new fixes and maintenance updates for the collection of libraries powering KDE software.
10 Apr 2026 10:59am GMT
Planet KDE | English
Web Review, Week 2026-15
Let's go for my web review for the week 2026-15.
France Launches Government Linux Desktop Plan as Windows Exit Begins
Tags: tech, foss, politics, desktop, france, europe
Well, what can I say? This is excellent news and I'm excited to see it happen. Let's hope more governments do the same. It'll take a while of course, so we'll have to be patient.
https://linuxiac.com/france-launches-government-linux-desktop-plan-as-windows-exit-begins/
The Free Market Lie: Why Switzerland Has 25 Gbit Internet and America Doesn't
Tags: tech, infrastructure, economics
A good explanation and illustration of how natural monopolies work. This is why you want to regulate infrastructure properly.
https://sschueller.github.io/posts/the-free-market-lie/
You can absolutely have an RSS dependent website in 2026
Tags: tech, blog, rss
The stats are clear there. Beside in term of experience, RSS feeds are so superior to newsletters… I wish more bloggers would give up on the newsletter focus. There's also a good point in this post: as soon as you have a newsletter you will sit on a database of email addresses, it's definitely a liability.
https://matduggan.com/you-can-absolutely-have-an-rss-dependent-website-in-2026/
The Downfall and Enshittification of Microsoft in 2026
Tags: tech, microsoft, github, apple, linux, business, product-management
Indeed, the giant managed to make itself weak. This means opportunities for other ecosystems to grow faster than before.
https://caio.ca/blog/the-downfall-and-enshittification-of-microsoft.html
Let's talk about LLMs
Tags: tech, ai, machine-learning, copilot, productivity, craftsmanship
Long but very precise piece about why you can likely ignore LLM for development purpose. Starting from older Fred Brooks work is spot on. Indeed whatever will remain of LLM based tools in the years to come, it's much smarter to focus on fundamental skills than chase the new tools. At least, I'm trying to do my share in getting myself and others better at the craft.
https://www.b-list.org/weblog/2026/apr/09/llms/
Almost Half of US Data Centers That Were Supposed to Open This Year Slated to Be Canceled or Delayed
Tags: tech, ai, machine-learning, gpt, energy, economics, infrastructure
It's getting clearer that the industrial LLM complex will have a hard time meeting its targets.
https://futurism.com/science-energy/data-centers-construction-supply
"Cognitive surrender" leads AI users to abandon logical thinking, research finds
Tags: tech, ai, machine-learning, gpt, cognition, bias
It feels like it's supercharging an old bias… We tend to confuse confidence for competence.
The machines are fine. I'm worried about us.
Tags: tech, ai, machine-learning, gpt, copilot, learning, science, research
Excellent piece, it show quite well the problem of skipping the "grunt work". Without it you can't really learn your trade (be it astrophysics or anything else). It also shows how the incentives on scientific careers are wrong. It's not new, but when LLM agents become available, things are definitely changing for the worst.
https://ergosphere.blog/posts/the-machines-are-fine/
Giving LLMs a Formal Reasoning Engine for Code Analysis
Tags: tech, ai, machine-learning, copilot, prolog, logic
Definitely interesting approach. I think neurosymbolic approaches are what we ultimately need so I'm probably biased. At least it means using LLMs for what they're good at (language skills) and only that. Then rely on proper code symbolic models which do the reasoning heavy lifting. I'd expect it can give nice output with smaller models.
https://yogthos.net/posts/2026-04-08-neurosymbolic-mcp.html
Open source security at Astral
Tags: tech, security, ci, supply-chain
Lots of interesting measures to reduce the risk of supply chain issues. Definitely to be considered on your projects.
https://astral.sh/blog/open-source-security-at-astral
another memory corruption case
Tags: tech, hardware, memory, failure
Failing DRAM chips are real. Here is the case of debugging a single bit flip.
https://trofi.github.io/posts/347-another-memory-corruption-case.html
The Git Commands I Run Before Reading Any Code
Tags: tech, git, version-control, team, audit
Nice little commands to use to discover quickly the state of a code base… Or rather of its team.
https://piechowski.io/post/git-commands-before-reading-code/
Zsh: select generated files with (om[1]) glob qualifiers
Tags: tech, zsh, shell
Oh this is super neat and convenient! I didn't know about those glob patterns modifiers in zsh.
https://adamj.eu/tech/2026/01/27/zsh-om1-glob-qualifiers/
Two little scripts: addup and sumup
Tags: tech, unix, shell, scripting
A friendly reminder that one can go far mainly with awk.
https://utcc.utoronto.ca/~cks/space/blog/sysadmin/LittleScriptsIX
All of the String types
Tags: tech, memory, unicode, encodings
So many string types! They all have a purpose of course. It's a good reminder that something mundane like a string type is not that simple.
https://lambdalemon.gay/posts/string-types
Stamp It! All Programs Must Report Their Version
Tags: tech, version-control, debugging
Examples of how i3 and go stamp versions. This is indeed good habits to ease dealing with errors in production.
https://michael.stapelberg.ch/posts/2026-04-05-stamp-it-all-programs-must-report-their-version/
The MVC Mistake
Tags: tech, architecture, complexity
Shows the problem with layer cakes in applications or how you might want to go toward onion architectures.
https://entropicthoughts.com/mvc-mistake
The Mouse That Roared
Tags: tech, leadership, tests, tdd, agile, organisation
Cryptic title to be honest. But this is a good explanation of why any "agile transformation" better start close to the code and in particular with automated tests. If you can crack that nut (and it takes time), the rest will follow naturally.
https://codemanship.wordpress.com/2026/03/30/the-mouse-that-roared/
If you thought the speed of writing code was your problem - you have bigger problems
Tags: tech, productivity, organisation, leadership, ai, machine-learning, copilot
So much this… There are so many organisational problems that churning code faster is likely not what you need. When did we start to obsess with the number of lines of code?
Are We Idiocracy Yet?
Tags: satire, culture
Getting there, one day at a time.
Bye for now!
10 Apr 2026 10:43am GMT
Fedora People
Fedora Community Blog: Community Update – Week 15 2026

This is a report created by CLE Team, which is a team containing community members working in various Fedora groups for example Infrastructure, Release Engineering, Quality etc. This team is also moving forward some initiatives inside Fedora project.
Week: 06 - 10 Apr 2026
Fedora Infrastructure
This team is taking care of day to day business regarding Fedora Infrastructure.
It's responsible for services running in Fedora infrastructure.
Ticket tracker
- [Badges/Outreachy] Over 45 pull requests reviewed in the last week [Repo A] [Repo B]
- Zabbix monitoring for PSQL added [ticket]
- Cleanup of websites ansible role [ticket]
- Fedora ostree pruner crashlooping because of missing policy
- DNS: Add A records for rpmeta.fedoraproject.org and rpmeta.stg.fedoraproject.org
CentOS Infra including CentOS CI
This team is taking care of day to day business regarding CentOS Infrastructure and CentOS Stream Infrastructure.
It's responsible for services running in CentOS Infratrusture and CentOS Stream.
CentOS ticket tracker
CentOS Stream ticket tracker
- Decommission old composes.centos.org CDN
- Create "toplink" links for Koji
- Email notifications from Jenkins CI no longer works
- unreachable risc-v builders
- Deploy django-allauth 0.62.1 on lists.centos.org
- [SN#1708] Adding back ppc64le arch as option for CI tenants
QE
This team is taking care of quality of Fedora. Maintaining CI, organizing test days
and keeping an eye on overall quality of Fedora releases.
- General release validation and bug reporting work throughout the whole week, in preparation for F44 Final.
- Automated a new openQA test for basic IPv4 and IPv6 connectivity (https://forge.fedoraproject.org/quality/os-autoinst-distri-fedora/pulls/504)
- Blockerbugs migration to Forge almost ready for staging deployment
- Ongoing collaboration with OSCI team to improve and rationalize generic test pipelines
- Contributed Kiwi and Koji logging improvements to Pungi as part of compose-critical script work
Forgejo
This team is working on introduction of https://forge.fedoraproject.org to Fedora
and migration of repositories from pagure.io.
- Documented the Forgejo W2FM support [Commit] [Documentation]
UX
This team is working on improving User experience. Providing artwork, user experience,
usability, and general design services to the Fedora project
- Madeline submitted a proposal for All Things Open
If you have any questions or feedback, please respond to this report or contact us on #admin:fedoraproject.org channel on matrix.
The post Community Update - Week 15 2026 appeared first on Fedora Community Blog.
10 Apr 2026 10:00am GMT
Planet KDE | English
KDE in Graz
I've been on the Akademy organizing team and contributing in various cat-herding capacities since 2023, but this is the first time I've joined other contributors for a Sprint.
My mission this week has been to scout locations and activities for the Akademy conference later this year. One of the members of our local organizing team let me (temporarily) adopt their stuffed Konqi, so I have been wandering around Graz and the state of Styria with a stuffed dragon taking a bunch of pictures, drinking Aperol Spritz, eating chocolate, and petting animals to make sure that all the places we visit in September will be fun and accessible for everyone who joins.



This year KDE turns 30, so we are planning a big celebration for Akademy. I have been thrilled to discover that Graz is very accessible. The town tourism website has a guide for navigating with a wheelchair or other mobility devices; many restaurants have mocktails or homemade juice/tea options for non-alcoholic drinks; the city is full of plazas you can sit and sip a coffee in for hours when you need a break from walking, and there is an abundance of parks and fountains that children can expel their energy playing in.
I can't wait to introduce the KDE community to Graz this September!
10 Apr 2026 8:49am GMT
Linuxiac
Deepin 25.1 Arrives With Linux Kernel 6.18 and New AI Features

Deepin 25.1 updates the desktop with Linux kernel 6.18, new UOS AI tools, file manager enhancements, and many fixes.
10 Apr 2026 8:27am GMT
Planet GNOME
Thibault Martin: TIL that Kubernetes can give you a shell into a crashing container
When a container crashes, it can be for several reasons. Sometimes the log won't tell you much about why the container crashed, and you can't get a shell into that container because... it has already crashed. It turns out that kubectl debug can let you do exactly that.
I was trying to ship Helfertool on our Kubernetes cluster. The firs step was to get it to work locally in my Minikube. The container I was deploying kept crashing, with an error message that put me on the right track: Cannot write to log directory. Exiting.
The container expected me to mount a volume on /log so it could write logs, which I did. I wanted to run a quick test from within the container to see if I could create a file in that directory. But when your container has already crashed you can't get a shell into it.
My better informed colleague Quentin told me about kubectl debug, a command that lets me create a copy of the crashing container but with a different COMMAND.
So instead of running its normal program, I can ask the container to run sh with the following command
$ kubectl debug mypod -it \
--copy-to=mypod-debug \
--container=my-pods-image \
-- sh
And just like that I have shell inside a similar container. Using this trick I could confirm that I can't touch a file in that /log directory because it belongs to root while my container is running unprivileged.
That's a great trick to troubleshoot from within a crashing container!
10 Apr 2026 8:00am GMT
This Week in GNOME: #244 Recognizing Hieroglyphs
Update on what happened across the GNOME project in the week from April 03 to April 10.
GNOME Core Apps and Libraries
Blueprint ↗
A markup language for app developers to create GTK user interfaces.
James Westman reports
blueprint-compiler is now available on PyPI. You can install it with
pip install blueprint-compiler.
GNOME Circle Apps and Libraries
Hieroglyphic ↗
Find LaTeX symbols
FineFindus reports
Hieroglyphic 2.3 is out now. Thanks to the exciting work done by Bnyro, Hieroglyphic can now also recognize Typst symbols (a modern alternative to LaTeX). Hardware-acceleration will now be preferred, when available, reducing power-consumption.
Download the latest version from FlatHub.

Amberol ↗
Plays music, and nothing else.
Emmanuele Bassi says
Amberol 2026.1 is out, using the GNOME 50 run time! This new release fixes a few issues when it comes to loading music, and has some small quality of life improvements in the UI, like: a more consistent visibility of the playlist panel when adding songs or searching; using the shortcuts dialog from libadwaita; and being able to open the file manager in the folder containing the current song. You can get Amberol on Flathub.

Third Party Projects
Alexander Vanhee says
A new version of Bazaar is out now. It features the ability to filter search results via a new popover and reworks the add-ons dialog to include a page that shows more information about a specific entry. If you try to open an add-on via the AppStream scheme, it will now display this page, which is useful when you want to redirect users to install an add-on from within your app.
Also, please take a look at the statistics dialog - it now features a cool gradient.
Check it out on Flathub

dabrain34 reports
GstPipelineStudio 0.5.1 is out now. It's a great pleasure to announce this new version allowing to deal with DOT files directly. Check the project web page for more information or the following blog post for more details about the release.

Anton Isaiev announces
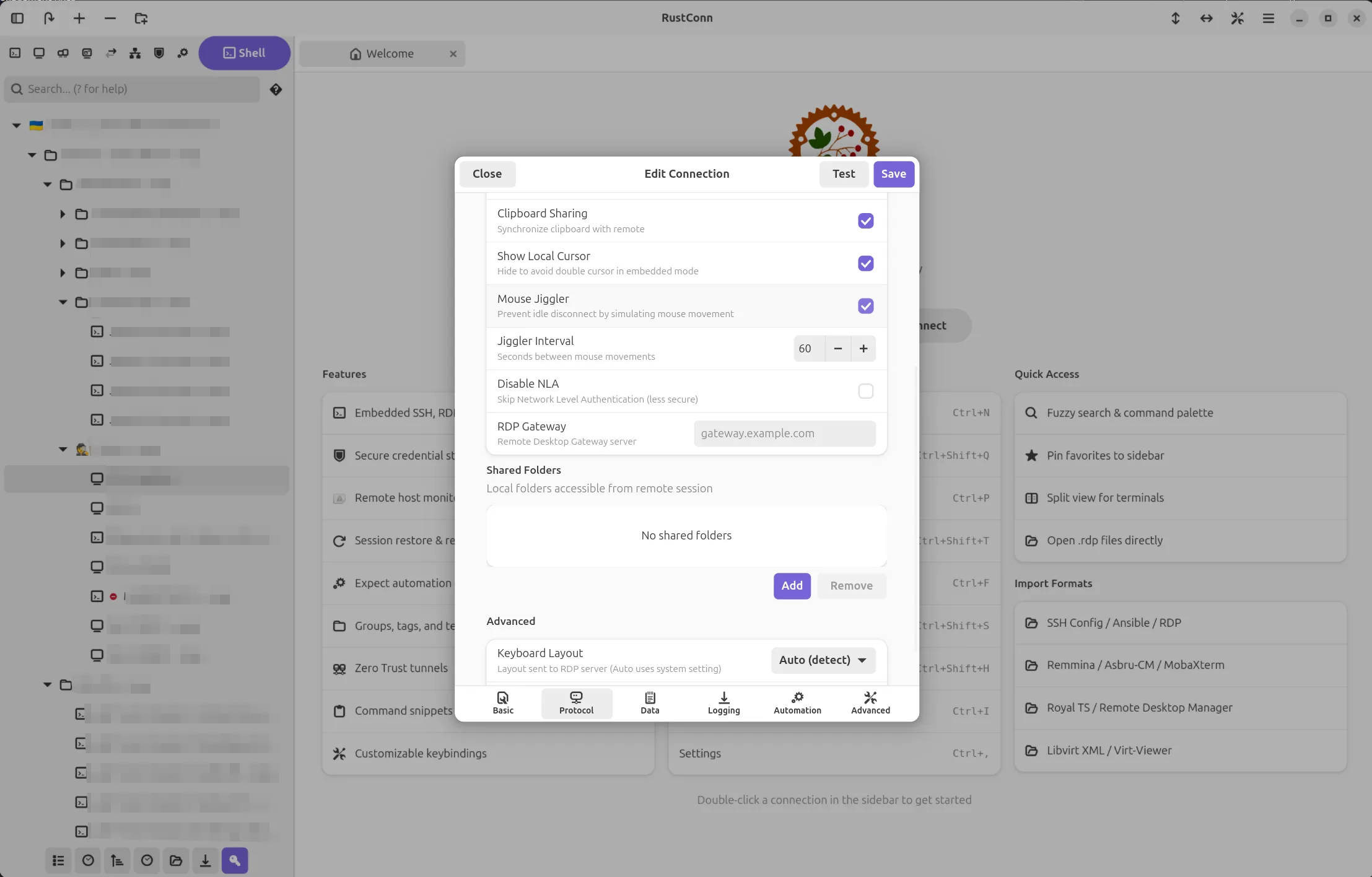
RustConn (connection manager for SSH, RDP, VNC, SPICE, Telnet, Serial, Kubernetes, MOSH, and Zero Trust protocols)
Versions 0.10.9-0.10.14 landed with a solid round of usability, security, and performance work.
Staying connected got easier. If an SSH session drops unexpectedly, RustConn now polls the host and reconnects on its own as soon as it's back. Wake-on-LAN works the same way: send the magic packet and RustConn connects automatically once the machine boots. You can also right-click any connection to check if the host is online, and a new "Connect All" option opens every connection in a folder at once. For RDP there's a Mouse Jiggler that keeps idle sessions alive.
Terminal Activity Monitor is a new per-session feature that watches for output activity or silence, which is handy for long-running jobs. You get notifications as tab icons, toasts, and desktop alerts when the window is in the background.
Security got a lot of attention. RDP now defaults to trust-on-first-use certificate validation instead of blindly accepting everything. Credentials for Bitwarden and 1Password are no longer visible in the process list. VNC passwords are zeroized on drop. Export files are written with owner-only permissions. Dangerous custom arguments are blocked for both VNC and FreeRDP viewers.
Hoop.dev joins as the 11th Zero Trust provider. There's also a new custom SSH agent socket setting that lets Flatpak users connect through KeePassXC, Bitwarden, or GPG-based SSH agents, something the Flatpak sandbox previously made difficult.
Smoother on HiDPI and 4K. RDP frame rendering skips a 33 MB per-frame copy when the data is already in the right format. Highlight rules, search, and log sanitization patterns are compiled once instead of on every keystroke or terminal line.
GNOME HIG polish. Success notifications now use non-blocking toasts instead of modal dialogs. Sidebar context menus are native PopoverMenus with keyboard navigation and screen reader support. Translations completed for all 15 languages.
Project: https://github.com/totoshko88/RustConn Flatpak: https://flathub.org/en/apps/io.github.totoshko88.RustConn
Phosh ↗
A pure wayland shell for mobile devices.
Guido announces
Phosh 0.54 is out:
There's now a notification when an app fails to start, the status bar can be extended via plugins, and the location quick toggle has a status page to set the maximum allowed accuracy.
On the compositor side we improved X11 support, making docked mode (aka convergence) with applications like emacs or ardour more fun to use.
The on screen keyboard Stevia now supports Japanese and Chinese input via UIM, has a new
us+workmanlayout and automatic space handling can be disabled.There's more - see the full details here.

.jpg){kind=link}
Documentation
Emmanuele Bassi announces
The GNOME User documentation project has been ported to use Meson for its configuration, build, and installation. The User documentation contains the desktop help and the system administration guide, and gets published on the user help website, as well as being available locally through the Help browser. The switch to Meson improved build times, and moved the tests and validation in the build system. There's a whole new contribution guideline as well. If you want to help writing the GNOME documentation, join us in the Docs room on Matrix!
Shell Extensions
Weather O'Clock ↗
Display the current weather inside the pill next to the clock.
Cleo Menezes Jr. reports
Weather O'Clock 50 released with fluffier animations: smooth fades between loading, weather and offline states; instant temperature updates; first-fetch spinner; offline indicator; GNOME Shell 45-50 support; and various bug fixes.
That's all for this week!
See you next week, and be sure to stop by #thisweek:gnome.org with updates on your own projects!
10 Apr 2026 12:00am GMT
Planet Debian
Reproducible Builds (diffoscope): diffoscope 317 released
The diffoscope maintainers are pleased to announce the release of diffoscope version 317. This version includes the following changes:
[ Chris Lamb ]
* Limit python3-guestfs Build-Dependency to !i386. (Closes: #1132974)
* Try to fix PYPI_ID_TOKEN debugging.
[ Holger Levsen ]
* Add ppc64el to the list of architectures for python3-guestfs.
You find out more by visiting the project homepage.
10 Apr 2026 12:00am GMT
Planet GNOME
Jakub Steiner: Moving to Zola

I've finally gotten around to porting this blog over to Zola. I've been running on Jekyll for years now, after originally conceiving this blog in Middleman (and PHP initially). But time catches up with everything, and the friction of maintaining Ruby dependencies eventually got to me.
The Speed
I can't stress this enough - Zola is fast. Not "for a static site generator" fast. Just fast. My old Jekyll setup needed a good few seconds to rebuild after a change. Zola builds in milliseconds. The entire site rebuilds almost before I can release the key. It's not critical for a site that gets updated 5 times a year, but it's still impressive.
No Dependencies
This is the big one. Every time you leave a project alone for a few months and come back, you know it's not just going to magically work. The gem versions drift, Bundler gets confused, and suddenly you're down a rabbit hole of version conflicts. The only reason all our Jekyll projects were reasonably easy to work with was locking onto Ruby 3.1.2 using rvm. But at some point the layers of backwardism catch up with you.
Zola is a single binary. That's it. No bundle install, no Gemfile, no "works on my machine" prayers. Download, run, done. It even embeds everything - syntax highlighting, image processing, Sass compilation (if you haven't embraced the modern CSS light yet) - all built-in. The site builds the same on any machine with zero setup.
The Heritage
Zola started life as Gutenberg in 2015/2016, a learning project for Rust by Vincent Prouillet. He was using Hugo before, but hated the Go template engine. That spawned Tera, the Jinja2-inspired template engine that Zola uses.
The project got renamed to Zola in 2018 when the name conflicts with Project Gutenberg got too annoying. It's pure Rust, which means it's fast, memory-safe, and ships as a tiny static binary.
Asset Colocation
One thing I've always focused on for this blog architecture wise is the structure - images and media live right alongside the post, not stuffed into some shared /images/ folder somewhere like most Jekyll sites seem to do. Zola calls this "asset colocation," and it's a first-class feature. No plugins needed. Just put your images in the same folder as your index.md, reference them directly, and Zola handles the rest.
This is how I'd already been running things with Jekyll, so the port was refreshingly painless on that front.
The Templating
The main work was porting the templates. It was the main shostopper when Bilal suggested Zola a couple of years ago. I was hoping something with liquid to pop up, but it seems like people running their own blogs is not a Tik Tok trend. Zola uses Tera instead of Liquid. The syntax is similar enough to get by, but there's enough branches in your path to stumble on. The error messages actually make sense though and point you at the problem, which is a refreshing change from debugging broken Liquid includes.
The Improvements
Beyond speed, I've been cleaning up things the old theme dragged along:
- Dark mode without JavaScript: The original Klise theme injected a script to toggle themes. The new setup uses CSS-only theming via custom properties, no flash of wrong theme, no JS required.
- Legibility: I'm getting older, and apparently so are my readers. Font sizes bumped up, contrast dialled in. What looked crisp at 30 looks muddy at 50.
The site's cleaner now, light by default, faster to build, and I don't need to invoke Ruby just to write a blog post. The experience was so damn good, it motivated me to jump at a much larger project I'm hopefully going to post about next.
10 Apr 2026 12:00am GMT
09 Apr 2026
OMG! Ubuntu
Your old Kindle won’t stop working on 20 May – but it could
 Amazon is dropping support for Kindle older models from 20 May, 2026, meaning owners of pre-2013 models will be unable to download new books or set up a device that has been factory reset - deregistering a device will effectively 'brick' it. While no company can support all of their products forever (one could argue a company the size of this one could, mind), most of the devices impacted, listed below, have not received firmware updates for over a decade, and most lost on-device access the Kindle Store. The following 2012 or earlier Kindles are affected, as of 20 May, […]
Amazon is dropping support for Kindle older models from 20 May, 2026, meaning owners of pre-2013 models will be unable to download new books or set up a device that has been factory reset - deregistering a device will effectively 'brick' it. While no company can support all of their products forever (one could argue a company the size of this one could, mind), most of the devices impacted, listed below, have not received firmware updates for over a decade, and most lost on-device access the Kindle Store. The following 2012 or earlier Kindles are affected, as of 20 May, […]
You're reading Your old Kindle won't stop working on 20 May - but it could, a blog post from OMG! Ubuntu. Do not reproduce elsewhere without permission.
09 Apr 2026 10:59pm GMT
Rust API and a new plugin system added to Miracle-WM
 A new version of Miracle-wm, a tiling window manager built around the Wayland compositor Mir, has been released with a new WebAssembly plugin system and Rust API. Developer Matthew Kosarek, an engineer at Canonical who created miracle-wm as a personal side project, says the new plugin system in v0.9 release will allow for greater window management, animation and configuration, thus making miracle-wm "truly hackable". He also shared a video overview of the changes in the latest update: A new Rust API for writing plugins is supported in Miracle 0.9, with documentation available for fans of the memory-safe language to swot over; […]
A new version of Miracle-wm, a tiling window manager built around the Wayland compositor Mir, has been released with a new WebAssembly plugin system and Rust API. Developer Matthew Kosarek, an engineer at Canonical who created miracle-wm as a personal side project, says the new plugin system in v0.9 release will allow for greater window management, animation and configuration, thus making miracle-wm "truly hackable". He also shared a video overview of the changes in the latest update: A new Rust API for writing plugins is supported in Miracle 0.9, with documentation available for fans of the memory-safe language to swot over; […]
You're reading Rust API and a new plugin system added to Miracle-WM, a blog post from OMG! Ubuntu. Do not reproduce elsewhere without permission.
09 Apr 2026 6:36pm GMT
06 Apr 2026
Kernel Planet
Linux Plumbers Conference: Changes to Registration Availability for 2026
As most of you are painfully aware, Linux Plumbers Conference registrations can run out very fast (yes, we got lots of complaints last year). This year, we're taking a couple of steps to alleviate the issue. Firstly, we're expanding the venue size in Prague to match the number of attendees we got in Vienna (800) which will hopefully mean we have more than enough places to keep registration open all the way up to the beginning of the conference. Secondly, we're going to have an pre-registration period starting two weeks before general registration opens for anyone who submits content. The way this will work is that if you submit anything via indico before general registration opens, you'll receive a voucher and instructions to participate (this applies to every track and MC submission regardless of the accept/reject or pending state). The cost will be the same as general registration (US$600) but you'll be under no obligation to take up the voucher, which will expire when general registration opens. We're aligning the acceptance/rejection notices of the tracks we directly control (Refereed and Kernel Summit) to be complete around the time we open pre-registration. However, for other tracks and MC submissions that aren't aligned, if you take up an early registration voucher but are subsequently offered a free pass, we'll refund it (although if your company pays, we'd appreciate not having to since cvent charges us).
As a reminder of free pass distribution: every accepted Track Speaker (Refereed, Kernel Summit, Net, BPF and Toolchain) gets a free pass. However, Microconferences operate differently and accepted Microconference discussion leads may not receive a free pass (Microconferences have two free passes each and can distribute them arbitrarily to encourage key attendees).
The anticipated date for the opening of early registration is Friday 10 July 2026, but remember this may change due to logistical problems with the cvent website (which we don't control).
06 Apr 2026 4:13pm GMT
03 Apr 2026
Planet Arch Linux
800 Rust terminal projects in 3 years
I have discovered and shared ~800 open source Rust CLI projects over the past 3 years.
03 Apr 2026 12:00am GMT
02 Apr 2026
Planet Gentoo
The Gentoo Big Forum Upgrade

It's taken a lot of time, but we have finally made the big step to upgrade our Gentoo Forums to phpBB3. You will notice a few differences between phpBB2 and today:
- It's definitely not Discourse.
- Everyone must change their password at first login, just to freshen them up.
- Reports are more private-like now, but we may get the old public reporting topic back later.
Discussion and feedback are welcome on the 'The Gentoo Big Forum Upgrade' discussion thread.
At the moment there are still a few know rough edges around, e.g.,
- Styles may need more or less tweaks, especially the dark one.
- Some BB codes are missing or/and need tweaking.
- The only language available is English.
And of course new issues may still pop up. In any case, enjoy the forums!
02 Apr 2026 5:00am GMT
01 Apr 2026
Kernel Planet
Dave Airlie (blogspot): drm subsystem contributor numbers
I'm doing a podcast recording this week, so I wanted to run some numbers so I could have some facts rather than feels. It turns out my feels were off by a factor of 3 or so.
If asked, I've always said the contributor count to the drm subsystem is probably in the 100 or so developers per release cycle.
Did the simplest:
git log --format='%aN' v6.14..v6.15 drivers/gpu/drm/ include/uapi/drm/ include/drm/ | sort -u | wc -l
Iterated over a few kernel releases
v6.15 326
v6.16 322
v6.17 300
v6.18 334
v6.19 332
v7.0-rc6 346
The number for the complete kernel in those scenarios are ~2000 usually, which means drm subsystem has around 15-16% of the kernel contributors.
I'm a bit spun out, that's quite a lot of people. I think I'll blame Sima for it. This also explains why I'm a bit out of touch with the process problems other maintainers have, and when I say stuff like a lot of workflows don't scale, this is what I mean.
01 Apr 2026 8:59pm GMT
Planet Gentoo
Supercharging our forums with AI

This turned out to be an April Fool's post. For the real upgrade announcement see here.
The Gentoo Forums are being upgraded for us to be able to leverage the latest in modern bleeding edge technologies. As many of you are no doubt aware, phpBB has been a challenging maintenance burden and despite years of effort, migrating to phpBB 3 has been eternally stuck. It is time to acknowledge this and find another solution. Fortunately, there is precedent from other FOSS communities that faced a similar problem.
tl;dr, we have chosen Discourse as the new forum software.
It seems doubtful that we will be able to import any of the old posts, and will likely start completely clean. However, we have been working on implementing AI features utilised via the Discourse API, which will scrape the internet for our old forums content (and more!), and post them for us in our new home. Due to this, viewing new posts will include old posts as well for the next few years or so, depending on how much of the old forums are backed up via the Internet Archive and similar archival sites. We have reasonably high hopes that many threads will appear exactly as they used to (after all, AI can only regurgitate what already existed…).
We understand that this move will be controversial, and have been working on some light themeing skins that will make it look a bit more like the classic phpbb2 of old, which hopefully should help alleviate most concern.
01 Apr 2026 5:00am GMT
Gentoo GNU/Hurd

We are proud to announce a new port of Gentoo to GNU Hurd! Our crack team has been working hard to port Gentoo to the Hurd and can now share that they've succeeded, though it remains still in a heavily experimental stage. You can try Gentoo GNU/Hurd using a pre-prepared disk image. The easiest way to do this is with QEMU:
$ wget https://distfiles.gentoo.org/experimental/x86/hurd/hurd-i686-preview.qcow2.sig
$ wget https://distfiles.gentoo.org/experimental/x86/hurd/hurd-i686-preview.qcow2
$ gpg --verify hurd-i686-preview.qcow2.sig hurd-i686-preview.qcow2
$ qemu-system-i386 -drive file=hurd-i686-preview.qcow2,format=qcow2 -m 2G -net user,hostfwd=tcp:127.0.0.1:2222-:2222 -net nic,model=ne2k_pci --enable-kvm -M q35
To log in, input login root, then use gnuhurdrox as the password. Upon logging in, you can run ./setup-net.sh and /etc/init.d/sshd restart to get SSH. Connect via ssh -p 2222 root@127.0.0.1 on your host.
We have developed scripts to build this image locally and conveniently work on further development of the Hurd port. Release media like stages and automated image builds are future goals, as is feature parity on x86-64. Further contributions are welcome, encouraged, and needed. Be patient, expect to get your hands dirty, anticipate breakage, and have fun!
Oh, and Gentoo GNU/Hurd also works on real hardware!
 |
 |
 |
 |
April Fool's post
This was originally the topic of a post on April 1st. Here's the original text for posterity…
We are proud to announce that Gentoo plans to switch to GNU Hurd as its primary kernel. Our crack team of boffins has been working hard to port Gentoo to the Hurd and can now share that that they've succeeded, though it remains still in a heavily experimental stage.
Linux has long been a source of unreliability. Despite the experimental status of the port, we've found the Hurd to be immensely more robust, and hope to be able to discontinue Linux support by the end of 2026. Previous generations of developers already attempted to port Gentoo to the Hurd, but the world was not yet ready. It is now. You can try Gentoo GNU Hurd using a pre-prepared disk image. The easiest way to do this is with QEMU: (…)
01 Apr 2026 5:00am GMT
Kernel Planet
Matthew Garrett: Self hosting as much of my online presence as practical
Because I am bad at giving up on things, I've been running my own email server for over 20 years. Some of that time it's been a PC at the end of a DSL line, some of that time it's been a Mac Mini in a data centre, and some of that time it's been a hosted VM. Last year I decided to bring it in house, and since then I've been gradually consolidating as much of the rest of my online presence as possible on it. I mentioned this on Mastodon and a couple of people asked for more details, so here we are.
First: my ISP doesn't guarantee a static IPv4 unless I'm on a business plan and that seems like it'd cost a bunch more, so I'm doing what I described here: running a Wireguard link between a box that sits in a cupboard in my living room and the smallest OVH instance I can, with an additional IP address allocated to the VM and NATted over the VPN link. The practical outcome of this is that my home IP address is irrelevant and can change as much as it wants - my DNS points at the OVH IP, and traffic to that all ends up hitting my server.
The server itself is pretty uninteresting. It's a refurbished HP EliteDesk which idles at 10W or so, along 2TB of NVMe and 32GB of RAM that I found under a pile of laptops in my office. We're not talking rackmount Xeon levels of performance, but it's entirely adequate for everything I'm doing here.
So. Let's talk about the services I'm hosting.
Web
This one's trivial. I'm not really hosting much of a website right now, but what there is is served via Apache with a Let's Encrypt certificate. Nothing interesting at all here, other than the proxying that's going to be relevant later.
Inbound email is easy enough. I'm running Postfix with a pretty stock configuration, and my MX records point at me. The same Let's Encrypt certificate is there for TLS delivery. I'm using Dovecot as an IMAP server (again with the same cert). You can find plenty of guides on setting this up.
Outbound email? That's harder. I'm on a residential IP address, so if I send email directly nobody's going to deliver it. Going via my OVH address isn't going to be a lot better. I have a Google Workspace, so in the end I just made use of Google's SMTP relay service. There's various commerical alternatives available, I just chose this one because it didn't cost me anything more than I'm already paying.
Blog
My blog is largely static content generated by Hugo. Comments are Remark42 running in a Docker container. If you don't want to handle even that level of dynamic content you can use a third party comment provider like Disqus.
Mastodon
I'm deploying Mastodon pretty much along the lines of the upstream compose file. Apache is proxying /api/v1/streaming to the websocket provided by the streaming container and / to the actual Mastodon service. The only thing I tripped over for a while was the need to set the "X-Forwarded-Proto" header since otherwise you get stuck in a redirect loop of Mastodon receiving a request over http (because TLS termination is being done by the Apache proxy) and redirecting to https, except that's where we just came from.
Mastodon is easily the heaviest part of all of this, using around 5GB of RAM and 60GB of disk for an instance with 3 users. This is more a point of principle than an especially good idea.
Bluesky
I'm arguably cheating here. Bluesky's federation model is quite different to Mastodon - while running a Mastodon service implies running the webview and other infrastructure associated with it, Bluesky has split that into multiple parts. User data is stored on Personal Data Servers, then aggregated from those by Relays, and then displayed on Appviews. Third parties can run any of these, but a user's actual posts are stored on a PDS. There are various reasons to run the others, for instance to implement alternative moderation policies, but if all you want is to ensure that you have control over your data, running a PDS is sufficient. I followed these instructions, other than using Apache as the frontend proxy rather than nginx, and it's all been working fine since then. In terms of ensuring that my data remains under my control, it's sufficient.
Backups
I'm using borgmatic, backing up to a local Synology NAS and also to my parents' home (where I have another HP EliteDesk set up with an equivalent OVH IPv4 fronting setup). At some point I'll check that I'm actually able to restore them.
Conclusion
Most of what I post is now stored on a system that's happily living under a TV, but is available to the rest of the world just as visibly as if I used a hosted provider. Is this necessary? No. Does it improve my life? In no practical way. Does it generate additional complexity? Absolutely. Should you do it? Oh good heavens no. But you can, and once it's working it largely just keeps working, and there's a certain sense of comfort in knowing that my online presence is carefully contained in a small box making a gentle whirring noise.
01 Apr 2026 2:35am GMT
28 Mar 2026
Planet Arch Linux
Building a guitar trainer with embedded Rust
All I wanted was to learn how to play guitar, but ended up building a DIY kit for it.
28 Mar 2026 12:00am GMT
30 Jan 2026
Planet Arch Linux
How to review an AUR package
On Friday, July 18th, 2025, the Arch Linux team was notified that three AUR packages had been uploaded that contained malware. A few maintainers including myself took care of deleting these packages, removing all traces of the malicious code, and protecting against future malicious uploads.
30 Jan 2026 12:00am GMT
26 Jan 2026
Planet Maemo
Igalia Multimedia contributions in 2025
Now that 2025 is over, it's time to look back and feel proud of the path we've walked. Last year has been really exciting in terms of contributions to GStreamer and WebKit for the Igalia Multimedia team.
With more than 459 contributions along the year, we've been one of the top contributors to the GStreamer project, in areas like Vulkan Video, GstValidate, VA, GStreamer Editing Services, WebRTC or H.266 support.
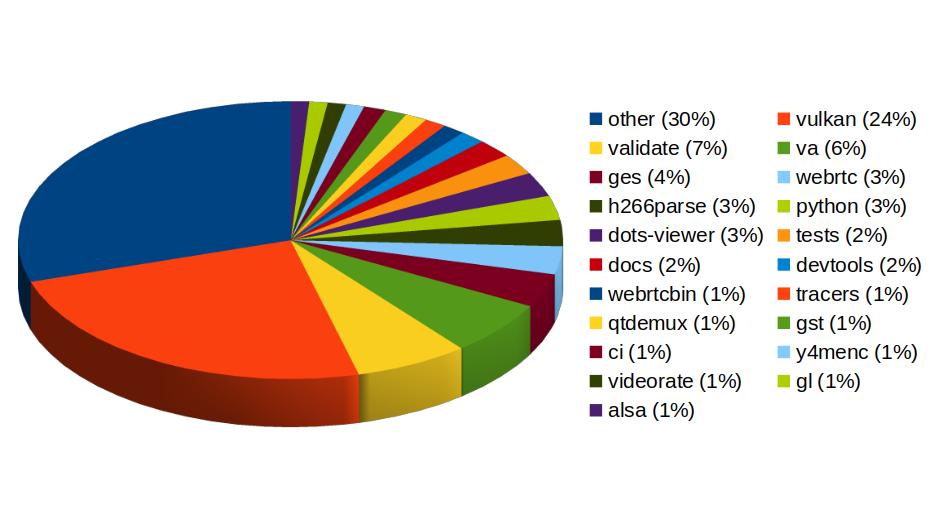
In Vulkan Video we've worked on the VP9 video decoder, and cooperated with other contributors to push the AV1 decoder as well. There's now an H.264 base class for video encoding that is designed to support general hardware-accelerated processing.
GStreaming Editing Services, the framework to build video editing applications, has gained time remapping support, which now allows to include fast/slow motion effects in the videos. Video transformations (scaling, cropping, rounded corners, etc) are now hardware-accelerated thanks to the addition of new Skia-based GStreamer elements and integration with OpenGL. Buffer pool tuning and pipeline improvements have helped to optimize memory usage and performance, enabling the edition of 4K video at 60 frames per second. Much of this work to improve and ensure quality in GStreamer Editing Services has also brought improvements in the GstValidate testing framework, which will be useful for other parts of GStreamer.
Regarding H.266 (VVC), full playback support (with decoders such as vvdec and avdec_h266, demuxers and muxers for Matroska, MP4 and TS, and parsers for the vvc1 and vvi1 formats) is now available in GStreamer 1.26 thanks to Igalia's work. This allows user applications such as the WebKitGTK web browser to leverage the hardware accelerated decoding provided by VAAPI to play H.266 video using GStreamer.
Igalia has also been one of the top contributors to GStreamer Rust, with 43 contributions. Most of the commits there have been related to Vulkan Video.
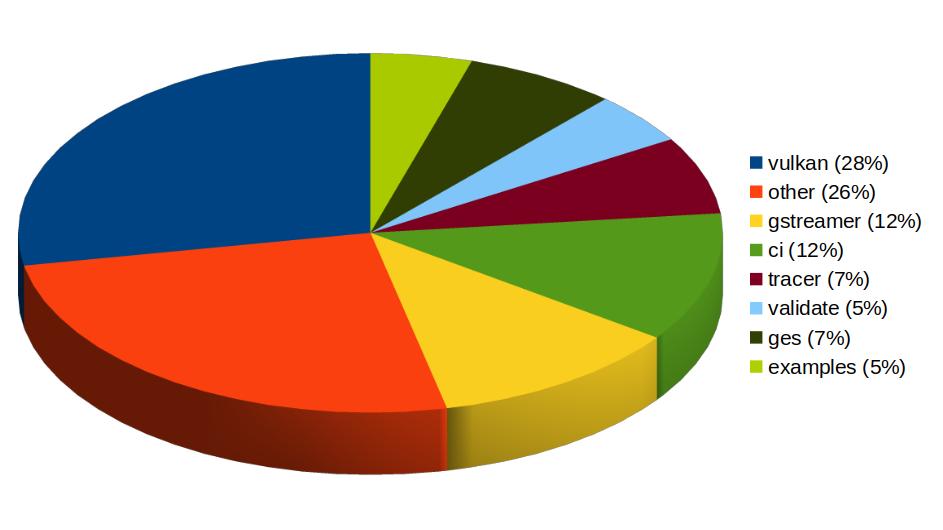
In addition to GStreamer, the team also has a strong presence in WebKit, where we leverage our GStreamer knowledge to implement many features of the web engine related to multimedia. From the 1739 contributions to the WebKit project done last year by Igalia, the Multimedia team has made 323 of them. Nearly one third of those have been related to generic multimedia playback, and the rest have been on areas such as WebRTC, MediaStream, MSE, WebAudio, a new Quirks system to provide adaptations for specific hardware multimedia platforms at runtime, WebCodecs or MediaRecorder.
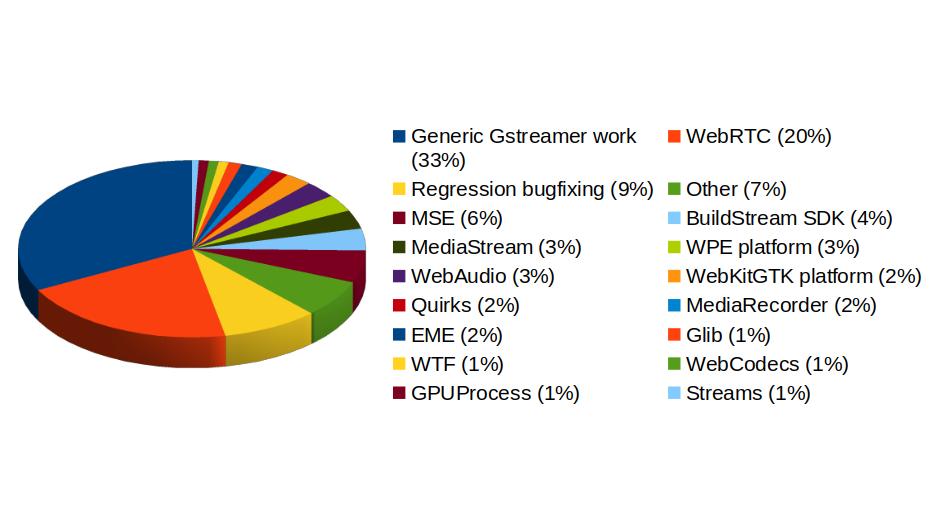
We're happy about what we've achieved along the year and look forward to maintaining this success and bringing even more exciting features and contributions in 2026.
0  0
0 
26 Jan 2026 9:34am GMT
05 Dec 2025
Planet Maemo
Meow: Process log text files as if you could make cat speak
Some years ago I had mentioned some command line tools I used to analyze and find useful information on GStreamer logs. I've been using them consistently along all these years, but some weeks ago I thought about unifying them in a single tool that could provide more flexibility in the mid term, and also as an excuse to unrust my Rust knowledge a bit. That's how I wrote Meow, a tool to make cat speak (that is, to provide meaningful information).
The idea is that you can cat a file through meow and apply the filters, like this:
cat /tmp/log.txt | meow appsinknewsample n:V0 n:video ht: \
ft:-0:00:21.466607596 's:#([A-za-z][A-Za-z]*/)*#'
which means "select those lines that contain appsinknewsample (with case insensitive matching), but don't contain V0 nor video (that is, by exclusion, only that contain audio, probably because we've analyzed both and realized that we should focus on audio for our specific problem), highlight the different thread ids, only show those lines with timestamp lower than 21.46 sec, and change strings like Source/WebCore/platform/graphics/gstreamer/mse/AppendPipeline.cpp to become just AppendPipeline.cpp", to get an output as shown in this terminal screenshot:
Cool, isn't it? After all, I'm convinced that the answer to any GStreamer bug is always hidden in the logs (or will be, as soon as I add "just a couple of log lines more, bro"  0 0
0 0
05 Dec 2025 11:16am GMT
15 Oct 2025
Planet Maemo
Dzzee 1.9.0 for N800/N810/N900/N9/Leste



1 0
15 Oct 2025 11:31am GMT
18 Sep 2022
Planet Openmoko
Harald "LaF0rge" Welte: Deployment of future community TDMoIP hub
I've mentioned some of my various retronetworking projects in some past blog posts. One of those projects is Osmocom Community TDM over IP (OCTOI). During the past 5 or so months, we have been using a number of GPS-synchronized open source icE1usb interconnected by a new, efficient but strill transparent TDMoIP protocol in order to run a distributed TDM/PDH network. This network is currently only used to provide ISDN services to retronetworking enthusiasts, but other uses like frame relay have also been validated.
So far, the central hub of this OCTOI network has been operating in the basement of my home, behind a consumer-grade DOCSIS cable modem connection. Given that TDMoIP is relatively sensitive to packet loss, this has been sub-optimal.
Luckily some of my old friends at noris.net have agreed to host a new OCTOI hub free of charge in one of their ultra-reliable co-location data centres. I'm already hosting some other machines there for 20+ years, and noris.net is a good fit given that they were - in their early days as an ISP - the driving force in the early 90s behind one of the Linux kernel ISDN stracks called u-isdn. So after many decades, ISDN returns to them in a very different way.
Side note: In case you're curious, a reconstructed partial release history of the u-isdn code can be found on gitea.osmocom.org
But I digress. So today, there was the installation of this new OCTOI hub setup. It has been prepared for several weeks in advance, and the hub contains two circuit boards designed entirely only for this use case. The most difficult challenge was the fact that this data centre has no existing GPS RF distribution, and the roof is ~ 100m of CAT5 cable (no fiber!) away from the roof. So we faced the challenge of passing the 1PPS (1 pulse per second) signal reliably through several steps of lightning/over-voltage protection into the icE1usb whose internal GPS-DO serves as a grandmaster clock for the TDM network.
The equipment deployed in this installation currently contains:
-
a rather beefy Supermicro 2U server with EPYC 7113P CPU and 4x PCIe, two of which are populated with Digium TE820 cards resulting in a total of 16 E1 ports
-
an icE1usb with RS422 interface board connected via 100m RS422 to an Ericsson GPS03 receiver. There's two layers of of over-voltage protection on the RS422 (each with gas discharge tubes and TVS) and two stages of over-voltage protection in the coaxial cable between antenna and GPS receiver.
-
a Livingston Portmaster3 RAS server
-
a Cisco AS5400 RAS server
For more details, see this wiki page and this ticket
Now that the physical deployment has been made, the next steps will be to migrate all the TDMoIP links from the existing user base over to the new hub. We hope the reliability and performance will be much better than behind DOCSIS.
In any case, this new setup for sure has a lot of capacity to connect many more more users to this network. At this point we can still only offer E1 PRI interfaces. I expect that at some point during the coming winter the project for remote TDMoIP BRI (S/T, S0-Bus) connectivity will become available.
Acknowledgements
I'd like to thank anyone helping this effort, specifically * Sylvain "tnt" Munaut for his work on the RS422 interface board (+ gateware/firmware) * noris.net for sponsoring the co-location * sysmocom for sponsoring the EPYC server hardware
18 Sep 2022 10:00pm GMT
08 Sep 2022
Planet Openmoko
Harald "LaF0rge" Welte: Progress on the ITU-T V5 access network front
Almost one year after my post regarding first steps towards a V5 implementation, some friends and I were finally able to visit Wobcom, a small German city carrier and pick up a lot of decommissioned POTS/ISDN/PDH/SDH equipment, primarily V5 access networks.
This means that a number of retronetworking enthusiasts now have a chance to play with Siemens Fastlink, Nokia EKSOS and DeTeWe ALIAN access networks/multiplexers.
My primary interest is in Nokia EKSOS, which looks like an rather easy, low-complexity target. As one of the first steps, I took PCB photographs of the various modules/cards in the shelf, take note of the main chip designations and started to search for the related data sheets.
The results can be found in the Osmocom retronetworking wiki, with https://osmocom.org/projects/retronetworking/wiki/Nokia_EKSOS being the main entry page, and sub-pages about
In short: Unsurprisingly, a lot of Infineon analog and digital ICs for the POTS and ISDN ports, as well as a number of Motorola M68k based QUICC32 microprocessors and several unknown ASICs.
So with V5 hardware at my disposal, I've slowly re-started my efforts to implement the LE (local exchange) side of the V5 protocol stack, with the goal of eventually being able to interface those V5 AN with the Osmocom Community TDM over IP network. Once that is in place, we should also be able to offer real ISDN Uk0 (BRI) and POTS lines at retrocomputing events or hacker camps in the coming years.
08 Sep 2022 10:00pm GMT
Harald "LaF0rge" Welte: Clock sync trouble with Digium cards and timing cables
If you have ever worked with Digium (now part of Sangoma) digital telephony interface cards such as the TE110/410/420/820 (single to octal E1/T1/J1 PRI cards), you will probably have seen that they always have a timing connector, where the timing information can be passed from one card to another.
In PDH/ISDN (or even SDH) networks, it is very important to have a synchronized clock across the network. If the clocks are drifting, there will be underruns or overruns, with associated phase jumps that are particularly dangerous when analog modem calls are transported.
In traditional ISDN use cases, the clock is always provided by the network operator, and any customer/user side equipment is expected to synchronize to that clock.
So this Digium timing cable is needed in applications where you have more PRI lines than possible with one card, but only a subset of your lines (spans) are connected to the public operator. The timing cable should make sure that the clock received on one port from the public operator should be used as transmit bit-clock on all of the other ports, no matter on which card.
Unfortunately this decades-old Digium timing cable approach seems to suffer from some problems.
bursty bit clock changes until link is up
The first problem is that downstream port transmit bit clock was jumping around in bursts every two or so seconds. You can see an oscillogram of the E1 master signal (yellow) received by one TE820 card and the transmit of the slave ports on the other card at https://people.osmocom.org/laforge/photos/te820_timingcable_problem.mp4
As you can see, for some seconds the two clocks seem to be in perfect lock/sync, but in between there are periods of immense clock drift.
What I'd have expected is the behavior that can be seen at https://people.osmocom.org/laforge/photos/te820_notimingcable_loopback.mp4 - which shows a similar setup but without the use of a timing cable: Both the master clock input and the clock output were connected on the same TE820 card.
As I found out much later, this problem only occurs until any of the downstream/slave ports is fully OK/GREEN.
This is surprising, as any other E1 equipment I've seen always transmits at a constant bit clock irrespective whether there's any signal in the opposite direction, and irrespective of whether any other ports are up/aligned or not.
But ok, once you adjust your expectations to this Digium peculiarity, you can actually proceed.
clock drift between master and slave cards
Once any of the spans of a slave card on the timing bus are fully aligned, the transmit bit clocks of all of its ports appear to be in sync/lock - yay - but unfortunately only at the very first glance.
When looking at it for more than a few seconds, one can see a slow, continuous drift of the slave bit clocks compared to the master :(
Some initial measurements show that the clock of the slave card of the timing cable is drifting at about 12.5 ppb (parts per billion) when compared against the master clock reference.
This is rather disappointing, given that the whole point of a timing cable is to ensure you have one reference clock with all signals locked to it.
The work-around
If you are willing to sacrifice one port (span) of each card, you can work around that slow-clock-drift issue by connecting an external loopback cable. So the master card is configured to use the clock provided by the upstream provider. Its other ports (spans) will transmit at the exact recovered clock rate with no drift. You can use any of those ports to provide the clock reference to a port on the slave card using an external loopback cable.
In this setup, your slave card[s] will have perfect bit clock sync/lock.
Its just rather sad that you need to sacrifice ports just for achieving proper clock sync - something that the timing connectors and cables claim to do, but in reality don't achieve, at least not in my setup with the most modern and high-end octal-port PCIe cards (TE820).
08 Sep 2022 10:00pm GMT