03 Aug 2026
 TalkAndroid
TalkAndroid
Stop Using WhatsApp: Here’s the Smarter Way to Share Your Live Location via Google Maps
Sharing your current whereabouts is easier than ever, but if you find WhatsApp's options a bit clunky or…
03 Aug 2026 6:30am GMT
After 15 Years, Sweden Officially Abandons All-Digital Schools—Is This the End of Screens in the Classroom?
After 15 years of going all-digital in the classroom, Sweden has made a historic U-turn. The country has…
03 Aug 2026 6:00am GMT
02 Aug 2026
TalkAndroid
Shocking Google Maps error puts hikers’ lives at risk—rescue teams issue urgent warning
Think Google Maps is your trusty sidekick for hiking? Think again. A recent incident in Canada's forests put…
02 Aug 2026 3:00pm GMT
29 Jul 2026
Android Developers Blog
Delivering safer, age-appropriate experiences on Google Play


Providing a safe online experience and protecting users from harm is a top priority at Google Play. We take this responsibility seriously and have been investing continuously to offer baseline protections on our platform while also empowering parents with the tools they need to make decisions for their families. Importantly, we also want to empower Play developers with the capabilities to deliver age-appropriate experiences based on their app's content.
To support this, today, we are taking another big step in our ongoing partnership with parents and developers by announcing the expansion of the Google Play Age Signals API to all Play developers globally. Building on current availability in Brazil, we will expand this experience first to users in Australia and Canada by mid-August, with a full global rollout to all users later this year.
Empowering developers to create age-appropriate experiences
The Play Age Signals API is a privacy-preserving tool that puts parents in the driver's seat allowing them to share their child's age range (e.g. 16-17) directly with apps. It also enables adults to easily share their age when prompted by the app developer. In turn, developers receive the signals they need to tailor their own in-app safety experiences and content for users in an age-appropriate way.
We want to give developers the ability to choose the right protections for the nature of their app. A weather app, for example, shouldn't need the same safety settings as entertainment or media apps. Rather than enforcing one-size-fits-all rules, we give developers the flexibility to choose how they integrate safety signals. With this reliable signal, you retain complete agency to tailor your app's content, features, and settings to match your audience.
.png)
Simplifying controls for parents
Parents shouldn't have to manage complex safety settings across dozens of different apps to keep their children safe. The Play Age Signals API simplifies this by putting age-sharing controls in one place, directly inside the Google Family Link app. Parents have a choice to share their child's age range, and if they choose to share, all Play apps that use Play Age Signals API can receive age signals. This lets children jump straight into age-appropriate content without parents having to manually configure settings inside these apps. Age ranges are never shared by default, and parents can update or turn off these settings at any time.
.png)
Building on our broader safety tools
The Play Age Signals API builds upon a strong foundation of established safety features and strict policies we have long enforced on Google Play. Today, we already mandate that apps designed for families meet rigorous safety standards, and we continuously review and scan applications to ensure they are safe for children. For developers, we also offer built-in tools like Restrict Minor Access in the Play Console to help them manage who can discover their apps. For parents, Google Family Link remains a trusted, central dashboard where they can manage screen-time limits, PIN-based content filters, and app download approvals.
Expanding the Play Age Signals API globally adds a powerful new tool to our existing safety suite, helping parents and developers work together to make Google Play an even safer, more trustworthy place for families.
29 Jul 2026 1:00pm GMT
28 Jul 2026
Android Developers Blog
Celebrating 5 years of Jetpack Compose
 Posted by Rebecca Franks, Developer Relations Engineer, Nick Butcher, Product Manager, Loryn Hairston, Product Marketing Manager, Android
Posted by Rebecca Franks, Developer Relations Engineer, Nick Butcher, Product Manager, Loryn Hairston, Product Marketing Manager, Android

Today, we officially celebrate five years since the release of Jetpack Compose 1.0. From version 1.0, announced on July 28th, 2021, to our latest 1.11 release, we've seen the APIs evolve significantly over the years, and we're taking a moment to celebrate.
When we officially announced the 1.0 release, we promised a simpler, faster, and more intuitive way to build native interfaces on Android. Looking back, it's safe to say that Compose didn't just deliver on that promise, but also completely changed the Android ecosystem, with more than 68% of the top 1,000 apps using it in production today.
History
Over the last five years, Compose has grown steadily. In the early days, we explored showing you how to build layouts with the basic Box, Row, and Column. Today, we've expanded Compose to work not just on mobile devices, but to other form factors such as Compose for TV, WearOS, Glance for Widgets, and even display glasses with Jetpack Compose Glimmer.

We recorded an Android Developers Backstage episode with Clara Bayarri, Engineering Lead for Jetpack, and two former leads of the team, Romain Guy and Chet Haase, along with Tor Norbye, Senior Engineering Director. In this episode, they discuss the history of Compose and the early days of development.

Looking back
The beginnings of Compose were very different from what you know today. Two projects were happening in parallel inside the Android team.
At the time, the Views toolkit team was thinking of unbundling the UI Toolkit into a library to help with development speed, and make it easier for developers to adopt and control updates. Meanwhile, a team was working on a novel idea to build declarative layouts by embedding XML inside Kotlin, which looked something like this:

Those two efforts merged to produce what you know today - a fully declarative UI Toolkit that utilizes the power of a compiler plugin, runtime, and Kotlin:
@Composable
fun Newsfeed(stories: List<Story>) {
LazyColumn {
items(stories) { story ->
Card {
val author = story.author
Image(painterResource(author.profilePhoto),
contentDescription = author.name)
Text(author.name)
Text(story.content)
if (story.hasCommentsEnabled()) {
for(comment in story.comments) {
Text(comment.mainContent)
}
}
}
}
}
}And you, the community, helped us very early on! Before 2021, Compose had a pre-alpha phase, which helped ensure Compose was fit to solve the problems of our developers.
One of our favorite memories is the Android Dev Challenge. We challenged the community to build four different tasks with Compose, filling our feeds with Puppy apps, clocks, and weather apps, and giving us a ton of direct feedback that helped shape the 1.0 release.
Compose has continued to evolve, from launching with a set of Material 2 components to now supporting Material 3 Expressive.

 Material 3 Expressive in Compose
Material 3 Expressive in ComposeLooking ahead
As of today, Compose 1.11 is the latest version with 1.12 coming soon, offering so much more than 1.0, 5 years ago. This year, we introduced more adaptive APIs, such as FlexBox, Grid, MediaQuery, and Styles. These APIs let you advance to the next level of premium, adaptive UI development with Compose.
At Google I/O 2026, we announced that we are now Compose-first, meaning that all future UI development will happen only in Compose, while the Views toolkit enters maintenance mode. Material Design is also shifting focus entirely to Compose, signaling an end to the findViewById era.
Community is at the heart of Compose
Over the years, you've inspired us with creative examples of how you've used Compose, and we'd love to highlight a few more examples of where we've seen exciting work. JetBrains has been a great partner for Google with Compose, expanding Compose to work across platforms with Compose Multiplatform and enabling desktop, iOS, and web developers to also enjoy the benefits of Compose.
We've really enjoyed following our most beloved newsletters from JetpackCompose.app's Dispatch, AndroidWeekly, to jetc - helping Android Developers stay up-to-date with the latest in the world of Compose and Android.
Another standout contributor is sinasamaki. They've created many delightful experiences using Compose, such as this fun ribbon modifier and the glitchy effect:
.gif)

Saket Narayan has also always been an inspiration when it comes to creating useful tools for Compose, such as telephoto, a library featuring support for pan and zoom gestures and automatic sub-sampling of large images, or the latest library, Touch Robot, which allows you to easily test interaction animations:
|
 |
Jake Wharton, who has used Compose in innovative ways (like molecule, and even building UI with Compose for the terminal with mosaic). Chris Banes, who has built many Compose libraries over the years, with our most recent favourite - Haze for background blurring, and many of the Android Google Developer Experts like Akshay Chordiya, Huyen Tue Dao, and Katie Barnett, who've contributed to the success of Compose. But this is not about selecting individuals - there have been so many great contributors to the Compose codebase, and many of you continue to inspire us with your fun examples, libraries, and in-depth talks. Without the community, Jetpack Compose wouldn't be as successful as it is today.
Cheers to the next 5 years, and more!
Jetpack Compose has grown from an experimental idea into the standard for Android UI Development. Thank you to the entire Toolkit team at Google, and to the incredible global developer community that wrote libraries, filed bugs, and pushed the boundaries of what declarative UI can do.
This week, we'll be celebrating with some in-person birthday parties across the globe, and a live "Birthday party" on the Android Developers YouTube channel on July 30th at 13:00 UTC. During this time, we'll hang out and discuss Compose and answer your questions!
Cheers to the next 5 years, and happy composing!
28 Jul 2026 4:00pm GMT
27 Jul 2026
Android Developers Blog
How R8 made Kotlin Coroutines on Android 2x faster
 Posted by Andrei Shikov, Senior Software Engineer, Android Toolkit and Jonathan Starup, Software Engineer, R8 Team
Posted by Andrei Shikov, Senior Software Engineer, Android Toolkit and Jonathan Starup, Software Engineer, R8 Team

Starting from AGP 9.2.0, R8 optimizes most Atomic*FieldUpdater calls into Unsafe variants that perform 2x to 4x better on common operations. This has a particularly large impact on the kotlinx.atomicfu library that implements atomics for kotlinx.coroutines, making launching and cancelling coroutines up to 2x faster. In order to get the benefits, update your AGP to 9.2.0 or above.
With the majority of Android apps adopting Kotlin as their main language of choice, kotlinx.coroutines has become a de-facto standard for asynchronous programming. The library offers a well-designed and structured way of managing concurrent flows that is native to Kotlin. Jetpack Compose was no exception, adopting coroutines for managing pointer events, animations and other interactions. At the time of writing, most concurrent APIs in Compose call suspend functions under the hood and are launching and/or cancelling coroutines to handle updates.
As the Compose team started to investigate performance, coroutines were discovered to be a bottleneck for many operations that happen outside of composition. As an example, 80% of the time spent on creating and updating Modifier.clickable was consumed by launching and cancelling internal coroutines that handled InteractionSource updates. Based on those observations, much of early performance work was focused on removing coroutines from the default path and delaying initialization until necessary.
The cost of a coroutine
The easiest way to analyze a function's internal behavior on Android is to capture an Android Runtime (ART) method trace. An ART method trace is a tool that records the execution flow of an app, showing exactly which methods are called, their order, and how much time is spent in each, allowing developers to identify performance bottlenecks. For an empty LaunchedEffect { } call, it would look something like this:

LaunchedEffect method trace visualized in the Perfetto UI
The method trace above can be separated into three parts:
- Initializing a new coroutine
- Starting coroutine
- Completing coroutine (because it exits immediately)
Cancelling LaunchedEffect is similar to normal completion, except it also creates a CancellationException.
From the profile above, one thing that is immediately suspicious is frequent calls into java.util.concurrent.AtomicReferenceFieldUpdater (purple or green boxes with j… labels). While each call is relatively fast, the frequency is concerning; any non-negligible overhead that is spread out across multiple invocations might add up to a noticeable regression. Zooming in on a call reveals that most of the time is spent on... reflection checks?

An up-close look at the method trace of AtomicReferenceFieldUpdater.get during LaunchedEffect initialization
Coroutines implement a lock-free tree structure for parent-child relationships that makes structured concurrency possible. Turns out, the kotlinx.atomicfu library implements lock-free atomic operations using a well-known JVM primitive, AtomicReferenceFieldUpdater. The updater uses a class reference and a field name to perform atomic operations at runtime, and it has to run several reflective safety checks to make sure the field exists and is accessible. Each operation in coroutines (starting, suspending, cancelling, completing) calls at least one atomic operation, so if it is slow, coroutines will not perform well.
Investigating AtomicReferenceFieldUpdater
But let's not get ahead of ourselves. AtomicReferenceFieldUpdater is actually well-optimized on JVM for over 10 years now, and method traces might capture overhead that is completely removed by a VM level optimization: just-in-time (JIT) or ahead-of-time (AOT) compilations. To verify performance, let's write a few benchmarks to measure the difference between atomic references from kotlinx.atomicfu and java.util.concurrent.atomic.
@RunWith(AndroidJUnit4::class)
class AtomicReferenceBenchmark {
@get:Rule
val benchmarkRule = BenchmarkRule()
private val atomicReference = java.util.concurrent.atomic.AtomicReference(false)
private val atomicRef = kotlinx.atomicfu.atomic<Boolean>(false)
@Test
fun atomicReference_compareAndSet() {
benchmarkRule.measureRepeated {
atomicReference.compareAndSet(true, false)
atomicReference.compareAndSet(false, true)
}
}
@Test
fun atomicRef_compareAndSet() {
benchmarkRule.measureRepeated {
atomicRef.compareAndSet(true, false)
atomicRef.compareAndSet(false, true)
}
}
/* measuring other methods from the method traces above */
}Running this benchmark on a Pixel 5 (while ensuring AtomicReferenceFieldUpdater#compareAndSet is JIT compiled during warmup), yields the following results on Pixel 5 (API 33):
50.7 ns atomicReference_compareAndSet
135 ns atomicRef_compareAndSet
The measurements confirm the gap, with kotlinx.atomicfu version clearly being approximately 2.7x slower. This confirms that ART does not perform any hidden optimization and reflective access checks add real overhead during runtime.
Looking back at the original method trace, the only meaningful work performed by the AtomicReferenceFieldUpdater is the internal call into Unsafe.getObjectVolatile that actually executes the underlying atomic operation. In most cases, the updater initializer is static, and can be proved to be always correct based on the structure of the surrounding class. Thus, one could statically analyze most of the AtomicReferenceFieldUpdater usages and replace them with an internal Unsafe variant during compilation. It also just happens that Android build toolchain has its very own optimizing compiler that can do exactly that.
Optimization with R8
The Atomic*FieldUpdater classes support subtle, dynamic and reflection-based use, but are often used in statically obvious patterns. This both explains the slow baseline performance and the want for optimization. R8 is a full-program optimizing compiler and is well-suited to see through the simpler patterns to skim the overhead of the reflective safety checks. R8 receives JVM bytecode after the Java or the Kotlin compiler, but to ease readability these examples are presented in Java syntax. This is why there are no type arguments for AtomicReferenceFieldUpdater.
class Example {
volatile String data = "";
static final AtomicReferenceFieldUpdater updater =
AtomicReferenceFieldUpdater.newUpdater(Example.class, String.class, "data");
void example() {
// ...
updater.compareAndSet(this, "", "new");
// ...
}
}The base example creates a static final updater which accesses a volatile field with simple constant arguments for the holder, the type, and the name of the field. The reflection used is totally transparent. It is clear to see this updater references a valid field and that the site of the updater creation has valid access to the field.
In its essence, Atomic*FieldUpdater is a wrapper around a field offset and calls to Unsafe. The best case scenario for the optimization is to replace the updater field with an offset field and replace the updater calls with calls to Unsafe.
Optimizing Atomic*FieldUpdater
The optimization is implemented in three parts: Instrumentation, Replacement, and Clean-up.
Instrumentation
The first step is to introduce offset fields alongside the updater field in order to facilitate direct access via the Unsafe call.
static final long updater$offset =
SyntheticUnsafe.UNSAFE.objectFieldOffset(Example.class.getDeclaredField("data"))The field is accessed via reflection, and Unsafe is used to extract the field offset on the class. This code represents the internals of Atomic*FieldUpdater if you disregard reflection validation. Instead, the holder type of the updater and the field type of the volatile field are tracked statically in the compiler.
Note that the original field and its initialization are left as-is. The optimization process optimistically facilitates and optimizes uses and then later cleans up. This is a simple approach to the implementation but also allows partial optimization of updater fields, where some uses are left as they were while others are optimized.
Replacement
At this point in the compiler, after a suitable concurrency join point, we have a list of instrumented updater fields. This means that we can optimize each call site individually based on a few conditions. Consider an example call:
updater.compareAndSet(holder, expectedValue, newValue);The conditions that Atomic*FieldUpdater requires are these:
- Does
updatercome from an instrumented field? That is, can static analysis track the value of the object back to a field read of an instrumented updater? - Is
holderthe same class or a subclass of the originally defined holder type? - Is
newValuethe same class or a subclass of the originally defined field type?
If all conditions are met, then the call is replaced by a call to Unsafe without any of the reflection checks.
SyntheticUnsafe.UNSAFE.compareAndSwapObject(holder, Example.updater$offset, expectedValue, newValue)This new call is faster and simpler but it differs from the original call in regards to its handling of null values in updater and holder. Unless statically ruled out, null-checks are inserted for both.
Clean-up
At this point, the holding class has the original updater field and the new offset field along with call sites that might use either one of the two. If none of the call sites were optimized, then the offset field should be removed and if all of the call sites were optimized, then the updater field should be removed. In both cases the initializing call should also be deleted. The deletion of unused fields and removal of dead code is already done in the compiler, but removing the initializing code here requires a few more tricks.
Both the call to newUpdater and getDeclaredField might have side effects as they can throw exceptions (and their implementation is also unknown since it depends on the API version). This means that by generic optimization, they cannot safely be removed. So this clean-up required explicit consideration of the instrumented fields, since those are statically known to be free of exceptions.
In the end, the simple updater example shown above looks like this after optimization:
class Example {
volatile String data = "";
static final long updater$offset =
SyntheticUnsafe.UNSAFE.objectFieldOffset(Example.class.getDeclaredField("data"))
void example() {
// ...
SyntheticUnsafe.UNSAFE.compareAndSwapObject(this, Example.updater$offset, "", "new")
// ...
}
}Results
After these optimizations, kotlinx.atomicfu and most explicit uses of AtomicInt/Long/ReferenceFieldUpdater now match AtomicReference performance with R8 applied. In fact, it is even faster in some benchmarks; kotlinx.atomicfu has a compiler plugin that can inline atomic instances into fields, reducing allocations required to create an atomically updated field.
Jetpack Compose was the main beneficiary of this work. Compose runtime has a number of microbenchmarks that track coroutine performance very closely to catch performance regressions early. When the benchmarks were updated to a new version of R8, we noticed a 2x improvement when launching and cancelling coroutines in LaunchedEffect!

Aside from that, the ART team is implementing these optimizations natively at the VM level. If your app is targeting API 37 and is running on a recent version of Android, it is possible that your device is already optimizing coroutines in a similar way. The coroutine benchmarks above observed ~15% improvement in performance after JIT updates in the recent versions of ART.
Your app will receive this optimization by default when upgrading to AGP 9.2.0 or by using R8 9.2.0 directly. For more information, see D8 dexer and R8 shrinker.
27 Jul 2026 1:00pm GMT
04 Jul 2026
Planet Maemo
Reticulum is interesting
It all started innocently enough: sometime last summer, I ran into the blog post Start your own Internet Resiliency Club on Hacker News.
…communicate with each other across a few kilometers without any centralized infrastructure using cheap, low-power, unlicensed LoRa radios and open source Meshtastic text messaging software.
The idea of a local, infrastructure-free communications mesh sounded useful, especially as we were about to sail into the Pacific.
Meshtastic
While conflicts and natural disasters are hopefully far away, on the smaller atolls there is no cellular network. With Meshtastic we could communicate over LoRa.

Over the hurricane season, the Meshtastic setup became quite extensive. Our boat has a Meshtastic node, plus a mast-mounted solar repeater. We both have Meshtastic cards that we carry with us. With these we can communicate with text messages over quite a long distance. And we get telemetry and alerts from the boat.
In Cartagena, Colombia we could hear the boat pretty much across the city. And since some of our buddy boats also run Meshtastic, we've even had conversations while offshore.
While the existing Meshtastic setup is serving us well, there is always room for improvement and new ideas.
Reticulum
Reticulum is a project that seeks to take this to a whole new level. It is a whole decentralized networking stack that allows anything from instant messaging and voice calls to full-on SSH sessions to be carried over a multitude of different interfaces. You can transport Reticulum over LoRa, Bluetooth, and also over regular TCP/IP networks. And if authorities didn't take a dim view on encryption in ham radio, it would also work over our HF radio. With store-and-forward mechanisms it can deal with intermittent connectivity.
Because your identity is portable, your connectivity can be fluid. You can be sitting at a desk connected to a fiber backbone one moment, and walking through a field connected only to a long-range LoRa mesh the next. To the rest of the network, nothing has changed. Your friends do not need to update your contact info. The messages they send do not bounce back. The network senses the shift in the medium and reroutes the flow of data automatically.
You are no longer a stationary node in a fixed grid. You are a wanderer in a fluid medium.
- The Zen of Reticulum
As it stands now, Reticulum is still quite an early system with rudimentary and tech-heavy user interfaces. But that seems to be about to change: the Columba app for Android seems about as user-friendly as Meshtastic or something like Signal. There's a lot of potential in that once it reaches a stable version.
Distributed development over Reticulum
In the meanwhile, there is one aspect of Reticulum we developers can benefit from immediately: Distributed development. With it, any rngit node running on Reticulum can be your "GitHub". Git history, issue tracking, release distribution is already there.
I recently switched my various programming projects over. We have rngit running on the boat NAS, and VPS running a mirror behind more consistent connectivity. And for now I also mirror the work periodically to GitHub for backwards compatibility.
Reticulum for software
What I think is worthwhile to explore is having machines interface with Reticulum. Just like we can tell our boat to switch lights on via a Meshtastic message, we should be able to do the same with Reticulum. And maybe there should be a NomadNet "site" for the boat showing status of the various systems.
Going further, maybe boats could share chart data, depth soundings, weather information with each other over this. The promise of VDES, but built from the grassroots perspective.
And maybe things like NoFlo should be able to communicate over Reticulum? Reticulum implementations exist for multiple programming languages, but for this we'd need a JavaScript port.
There's still a lot to study and to think about. Watch this space. Last time I noted that something is interesting, it took me to a ten year rabbit hole.
0  0
0 
04 Jul 2026 12:00am GMT
26 Jan 2026
Planet Maemo
Igalia Multimedia contributions in 2025
Now that 2025 is over, it's time to look back and feel proud of the path we've walked. Last year has been really exciting in terms of contributions to GStreamer and WebKit for the Igalia Multimedia team.
With more than 459 contributions along the year, we've been one of the top contributors to the GStreamer project, in areas like Vulkan Video, GstValidate, VA, GStreamer Editing Services, WebRTC or H.266 support.
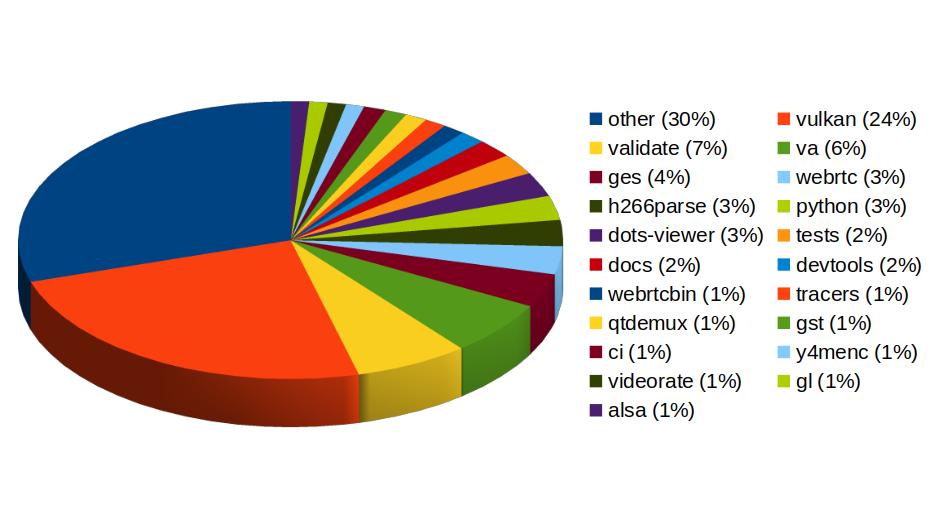
In Vulkan Video we've worked on the VP9 video decoder, and cooperated with other contributors to push the AV1 decoder as well. There's now an H.264 base class for video encoding that is designed to support general hardware-accelerated processing.
GStreaming Editing Services, the framework to build video editing applications, has gained time remapping support, which now allows to include fast/slow motion effects in the videos. Video transformations (scaling, cropping, rounded corners, etc) are now hardware-accelerated thanks to the addition of new Skia-based GStreamer elements and integration with OpenGL. Buffer pool tuning and pipeline improvements have helped to optimize memory usage and performance, enabling the edition of 4K video at 60 frames per second. Much of this work to improve and ensure quality in GStreamer Editing Services has also brought improvements in the GstValidate testing framework, which will be useful for other parts of GStreamer.
Regarding H.266 (VVC), full playback support (with decoders such as vvdec and avdec_h266, demuxers and muxers for Matroska, MP4 and TS, and parsers for the vvc1 and vvi1 formats) is now available in GStreamer 1.26 thanks to Igalia's work. This allows user applications such as the WebKitGTK web browser to leverage the hardware accelerated decoding provided by VAAPI to play H.266 video using GStreamer.
Igalia has also been one of the top contributors to GStreamer Rust, with 43 contributions. Most of the commits there have been related to Vulkan Video.
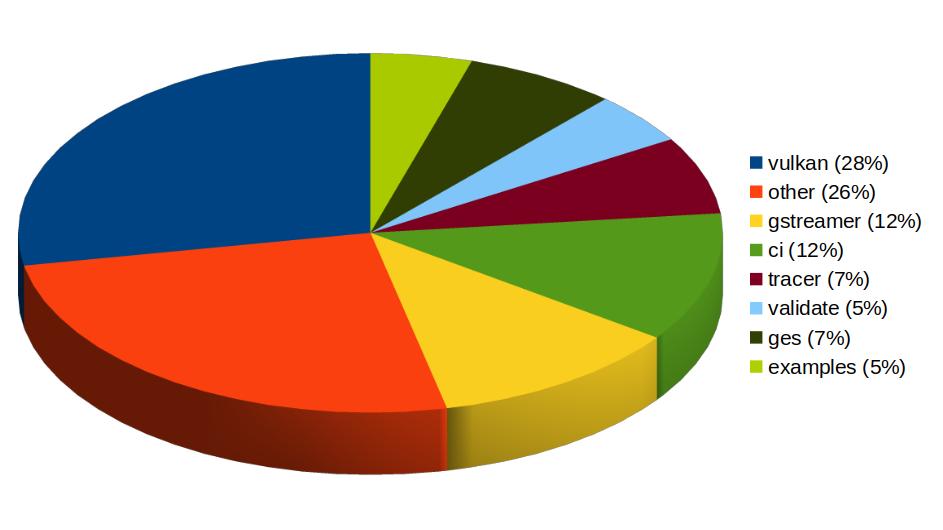
In addition to GStreamer, the team also has a strong presence in WebKit, where we leverage our GStreamer knowledge to implement many features of the web engine related to multimedia. From the 1739 contributions to the WebKit project done last year by Igalia, the Multimedia team has made 323 of them. Nearly one third of those have been related to generic multimedia playback, and the rest have been on areas such as WebRTC, MediaStream, MSE, WebAudio, a new Quirks system to provide adaptations for specific hardware multimedia platforms at runtime, WebCodecs or MediaRecorder.
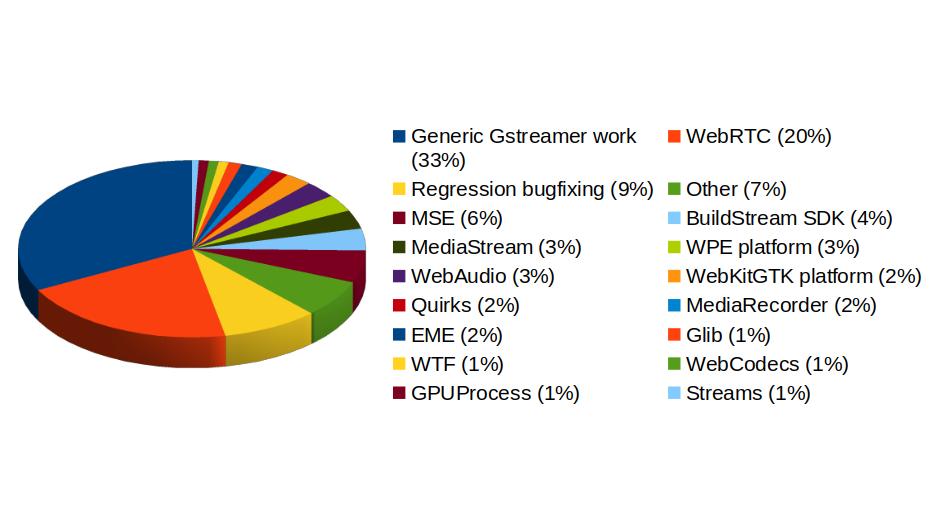
We're happy about what we've achieved along the year and look forward to maintaining this success and bringing even more exciting features and contributions in 2026.
0 0
26 Jan 2026 9:34am GMT
05 Dec 2025
Planet Maemo
Meow: Process log text files as if you could make cat speak
Some years ago I had mentioned some command line tools I used to analyze and find useful information on GStreamer logs. I've been using them consistently along all these years, but some weeks ago I thought about unifying them in a single tool that could provide more flexibility in the mid term, and also as an excuse to unrust my Rust knowledge a bit. That's how I wrote Meow, a tool to make cat speak (that is, to provide meaningful information).
The idea is that you can cat a file through meow and apply the filters, like this:
cat /tmp/log.txt | meow appsinknewsample n:V0 n:video ht: \
ft:-0:00:21.466607596 's:#([A-za-z][A-Za-z]*/)*#'
which means "select those lines that contain appsinknewsample (with case insensitive matching), but don't contain V0 nor video (that is, by exclusion, only that contain audio, probably because we've analyzed both and realized that we should focus on audio for our specific problem), highlight the different thread ids, only show those lines with timestamp lower than 21.46 sec, and change strings like Source/WebCore/platform/graphics/gstreamer/mse/AppendPipeline.cpp to become just AppendPipeline.cpp", to get an output as shown in this terminal screenshot:
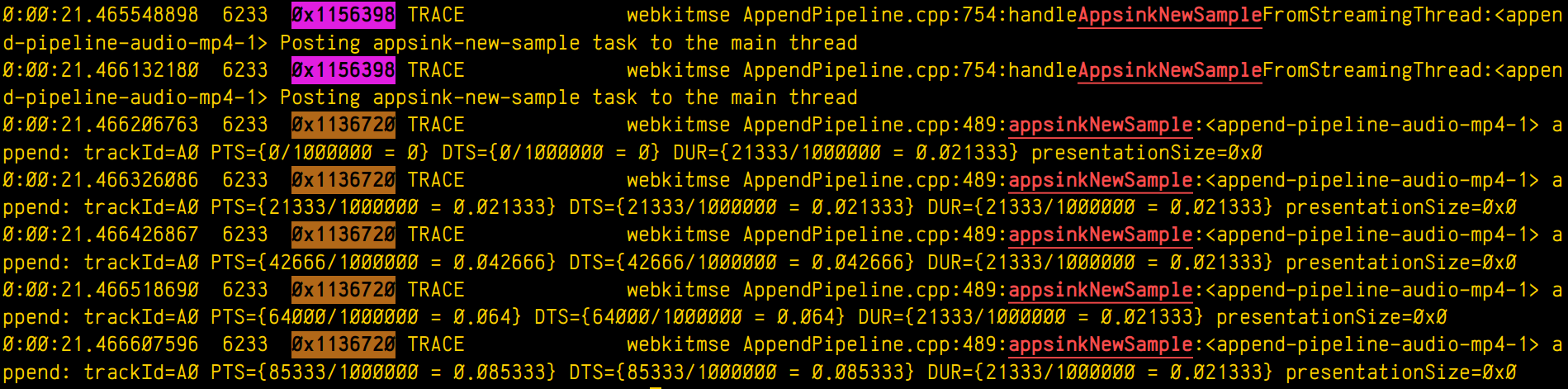
Cool, isn't it? After all, I'm convinced that the answer to any GStreamer bug is always hidden in the logs (or will be, as soon as I add "just a couple of log lines more, bro"  0 0
0 0
05 Dec 2025 11:16am GMT
18 Sep 2022
Planet Openmoko
Harald "LaF0rge" Welte: Deployment of future community TDMoIP hub
I've mentioned some of my various retronetworking projects in some past blog posts. One of those projects is Osmocom Community TDM over IP (OCTOI). During the past 5 or so months, we have been using a number of GPS-synchronized open source icE1usb interconnected by a new, efficient but strill transparent TDMoIP protocol in order to run a distributed TDM/PDH network. This network is currently only used to provide ISDN services to retronetworking enthusiasts, but other uses like frame relay have also been validated.
So far, the central hub of this OCTOI network has been operating in the basement of my home, behind a consumer-grade DOCSIS cable modem connection. Given that TDMoIP is relatively sensitive to packet loss, this has been sub-optimal.
Luckily some of my old friends at noris.net have agreed to host a new OCTOI hub free of charge in one of their ultra-reliable co-location data centres. I'm already hosting some other machines there for 20+ years, and noris.net is a good fit given that they were - in their early days as an ISP - the driving force in the early 90s behind one of the Linux kernel ISDN stracks called u-isdn. So after many decades, ISDN returns to them in a very different way.
Side note: In case you're curious, a reconstructed partial release history of the u-isdn code can be found on gitea.osmocom.org
But I digress. So today, there was the installation of this new OCTOI hub setup. It has been prepared for several weeks in advance, and the hub contains two circuit boards designed entirely only for this use case. The most difficult challenge was the fact that this data centre has no existing GPS RF distribution, and the roof is ~ 100m of CAT5 cable (no fiber!) away from the roof. So we faced the challenge of passing the 1PPS (1 pulse per second) signal reliably through several steps of lightning/over-voltage protection into the icE1usb whose internal GPS-DO serves as a grandmaster clock for the TDM network.
The equipment deployed in this installation currently contains:
-
a rather beefy Supermicro 2U server with EPYC 7113P CPU and 4x PCIe, two of which are populated with Digium TE820 cards resulting in a total of 16 E1 ports
-
an icE1usb with RS422 interface board connected via 100m RS422 to an Ericsson GPS03 receiver. There's two layers of of over-voltage protection on the RS422 (each with gas discharge tubes and TVS) and two stages of over-voltage protection in the coaxial cable between antenna and GPS receiver.
-
a Livingston Portmaster3 RAS server
-
a Cisco AS5400 RAS server
For more details, see this wiki page and this ticket
Now that the physical deployment has been made, the next steps will be to migrate all the TDMoIP links from the existing user base over to the new hub. We hope the reliability and performance will be much better than behind DOCSIS.
In any case, this new setup for sure has a lot of capacity to connect many more more users to this network. At this point we can still only offer E1 PRI interfaces. I expect that at some point during the coming winter the project for remote TDMoIP BRI (S/T, S0-Bus) connectivity will become available.
Acknowledgements
I'd like to thank anyone helping this effort, specifically * Sylvain "tnt" Munaut for his work on the RS422 interface board (+ gateware/firmware) * noris.net for sponsoring the co-location * sysmocom for sponsoring the EPYC server hardware
18 Sep 2022 10:00pm GMT
08 Sep 2022
Planet Openmoko
Harald "LaF0rge" Welte: Progress on the ITU-T V5 access network front
Almost one year after my post regarding first steps towards a V5 implementation, some friends and I were finally able to visit Wobcom, a small German city carrier and pick up a lot of decommissioned POTS/ISDN/PDH/SDH equipment, primarily V5 access networks.
This means that a number of retronetworking enthusiasts now have a chance to play with Siemens Fastlink, Nokia EKSOS and DeTeWe ALIAN access networks/multiplexers.
My primary interest is in Nokia EKSOS, which looks like an rather easy, low-complexity target. As one of the first steps, I took PCB photographs of the various modules/cards in the shelf, take note of the main chip designations and started to search for the related data sheets.
The results can be found in the Osmocom retronetworking wiki, with https://osmocom.org/projects/retronetworking/wiki/Nokia_EKSOS being the main entry page, and sub-pages about
In short: Unsurprisingly, a lot of Infineon analog and digital ICs for the POTS and ISDN ports, as well as a number of Motorola M68k based QUICC32 microprocessors and several unknown ASICs.
So with V5 hardware at my disposal, I've slowly re-started my efforts to implement the LE (local exchange) side of the V5 protocol stack, with the goal of eventually being able to interface those V5 AN with the Osmocom Community TDM over IP network. Once that is in place, we should also be able to offer real ISDN Uk0 (BRI) and POTS lines at retrocomputing events or hacker camps in the coming years.
08 Sep 2022 10:00pm GMT
Harald "LaF0rge" Welte: Clock sync trouble with Digium cards and timing cables
If you have ever worked with Digium (now part of Sangoma) digital telephony interface cards such as the TE110/410/420/820 (single to octal E1/T1/J1 PRI cards), you will probably have seen that they always have a timing connector, where the timing information can be passed from one card to another.
In PDH/ISDN (or even SDH) networks, it is very important to have a synchronized clock across the network. If the clocks are drifting, there will be underruns or overruns, with associated phase jumps that are particularly dangerous when analog modem calls are transported.
In traditional ISDN use cases, the clock is always provided by the network operator, and any customer/user side equipment is expected to synchronize to that clock.
So this Digium timing cable is needed in applications where you have more PRI lines than possible with one card, but only a subset of your lines (spans) are connected to the public operator. The timing cable should make sure that the clock received on one port from the public operator should be used as transmit bit-clock on all of the other ports, no matter on which card.
Unfortunately this decades-old Digium timing cable approach seems to suffer from some problems.
bursty bit clock changes until link is up
The first problem is that downstream port transmit bit clock was jumping around in bursts every two or so seconds. You can see an oscillogram of the E1 master signal (yellow) received by one TE820 card and the transmit of the slave ports on the other card at https://people.osmocom.org/laforge/photos/te820_timingcable_problem.mp4
As you can see, for some seconds the two clocks seem to be in perfect lock/sync, but in between there are periods of immense clock drift.
What I'd have expected is the behavior that can be seen at https://people.osmocom.org/laforge/photos/te820_notimingcable_loopback.mp4 - which shows a similar setup but without the use of a timing cable: Both the master clock input and the clock output were connected on the same TE820 card.
As I found out much later, this problem only occurs until any of the downstream/slave ports is fully OK/GREEN.
This is surprising, as any other E1 equipment I've seen always transmits at a constant bit clock irrespective whether there's any signal in the opposite direction, and irrespective of whether any other ports are up/aligned or not.
But ok, once you adjust your expectations to this Digium peculiarity, you can actually proceed.
clock drift between master and slave cards
Once any of the spans of a slave card on the timing bus are fully aligned, the transmit bit clocks of all of its ports appear to be in sync/lock - yay - but unfortunately only at the very first glance.
When looking at it for more than a few seconds, one can see a slow, continuous drift of the slave bit clocks compared to the master :(
Some initial measurements show that the clock of the slave card of the timing cable is drifting at about 12.5 ppb (parts per billion) when compared against the master clock reference.
This is rather disappointing, given that the whole point of a timing cable is to ensure you have one reference clock with all signals locked to it.
The work-around
If you are willing to sacrifice one port (span) of each card, you can work around that slow-clock-drift issue by connecting an external loopback cable. So the master card is configured to use the clock provided by the upstream provider. Its other ports (spans) will transmit at the exact recovered clock rate with no drift. You can use any of those ports to provide the clock reference to a port on the slave card using an external loopback cable.
In this setup, your slave card[s] will have perfect bit clock sync/lock.
Its just rather sad that you need to sacrifice ports just for achieving proper clock sync - something that the timing connectors and cables claim to do, but in reality don't achieve, at least not in my setup with the most modern and high-end octal-port PCIe cards (TE820).
08 Sep 2022 10:00pm GMT