15 Jun 2026
 Hacker News
Hacker News
Anthropic's Safety Superpower
15 Jun 2026 10:06am GMT
Linuxiac
ZeroFS Turns S3 Buckets Into Linux Filesystems and Block Devices

ZeroFS is a new open-source project that exposes S3-compatible storage over NFS, 9P, and NBD for Linux systems.
15 Jun 2026 9:48am GMT
Hacker News
Show HN: I wrote a C++ ray tracer from scratch without AI
15 Jun 2026 9:34am GMT
What the Fuck Happened to Nerds
15 Jun 2026 8:23am GMT
Kubernetes Blog
Spotlight on SIG Storage
In our ongoing SIG Spotlight series, we shine a light on the groups that keep the Kubernetes project moving forward. This time, we catch up with SIG Storage, the group responsible for persistent data, volume management, and the interfaces that connect Kubernetes workloads to the storage systems beneath them.
We spoke with Xing Yang, Co-Chair of SIG Storage and Software Engineer at VMware by Broadcom, about the SIG's history, the features shipping in recent Kubernetes releases, and where storage in Kubernetes is headed as AI workloads become the norm.
Introductions
Could you introduce yourself and share your role(s) within SIG Storage?
My name is Xing Yang, a software engineer at VMware by Broadcom. I'm a co-chair in SIG Storage, alongside another co-chair Saad Ali from Google. There are also two Tech Leads in SIG Storage: Michelle Au from Google and Jan Šafránek from Red Hat.
What first drew you to storage in Kubernetes, and how did you start contributing?
I have always been working in the storage domain, so SIG Storage was a natural place for me to get started when I began to learn Kubernetes. I started attending SIG Storage meetings, trying to figure out what I could do to help. This was before the first Container Storage Interface (CSI) release - lots of things were still evolving. It was a very exciting time.
What subprojects or areas do you actively maintain or review today?
I'm a maintainer in Kubernetes CSI. There are multiple CSI sidecars - such as csi-provisioner, csi-attacher, csi-resizer, and csi-snapshotter - that we need to release following every Kubernetes release. I'm also a co-chair for a Data Protection Working Group co-sponsored by SIG Storage and SIG Apps. Several features have come out of that WG aimed at filling gaps in data protection support within Kubernetes. One is Volume Group Snapshot, which provides crash-consistent group snapshots for multiple volumes used by an application. Changed Block Tracking (CBT) is another critical feature from the DP WG designed to support efficient backups.
About SIG Storage
For folks who are new: what is SIG Storage, in your own words? What problems in Kubernetes are you trying to solve?
SIG Storage is a Special Interest Group focused on how to provide storage to containers running in your Kubernetes cluster. We define standard interfaces so that a storage vendor can write a driver and have its underlying storage system consumed by containers in Kubernetes.
Why does Kubernetes need a dedicated storage SIG? What makes storage hard in a distributed system?
When Kubernetes was first introduced, it was meant for stateless workloads only. Container applications were regarded as ephemeral and therefore did not need to persist data. However, that changed drastically. Stateful workloads started running in Kubernetes, and we needed a dedicated SIG to tackle the associated storage challenges. PersistentVolumeClaims, PersistentVolumes, and StorageClasses were all introduced to provision data volumes for applications running in Kubernetes.
How did SIG Storage originally form, and how has its mission changed over time?
SIG Storage was formed to address the challenges of handling persistent data within Kubernetes. Initially, PersistentVolumes were implemented as in-tree plugins, and the SIG managed those plugins while developing core storage primitives like PersistentVolumes and PersistentVolumeClaims.
Container Storage Interface (CSI) was introduced later and played a crucial role in simplifying storage integration, enabling third-party storage providers to develop and maintain their own out-of-tree plugins without modifying Kubernetes core code.
With basic integration addressed by CSI, the SIG's mission expanded to include advanced storage features that leverage the new interface. The SIG has also expanded its scope to support object storage through the Container Object Storage Interface (COSI).
Current work and roadmap
What are the top features SIG Storage is actively working on right now?
The Data Protection WG has been working on a couple of exciting features:
-
VolumeGroupSnapshot is a Kubernetes feature enabling a crash-consistent, point-in-time snapshot of multiple PersistentVolumes simultaneously. This ensures data integrity for applications - like databases - that rely on multiple volumes by capturing all volumes in the group atomically, at the exact same point in time. It just moved to GA in Kubernetes v1.36.
-
CSI Changed Block Tracking (CBT) enables efficient, incremental backups. By allowing storage systems to report only the blocks that have changed since the last snapshot, it significantly reduces the amount of data that needs to be transferred. It just moved to Beta in Kubernetes v1.36.
Another feature worth highlighting is Container Object Storage Interface (COSI). COSI provides a standard interface for provisioning and consuming object storage buckets in Kubernetes - standardizing object storage for containerized applications much like CSI did for block and file storage. COSI is now transitioning to v1alpha2, with plans for promotion to Beta in a future release.
What recent work from SIG Storage do you consider a "win" for users?
The graduation of VolumeAttributesClass to GA in Kubernetes v1.34 is a major win for users managing stateful workloads. Previously, changing volume attributes like IOPS or throughput required out-of-band actions or disruptive operations. Now, users can dynamically tune storage properties such as IOPS or throughput directly through the Kubernetes API - scaling up for peak loads or down to optimize costs - without external processes or downtime.
VolumeAttributesClass enables dynamic modification of storage characteristics without recreating the volume. This completes the picture by allowing users to tune both capacity and other storage properties dynamically, just as they can now tune both CPU and memory for compute.
Looking ahead one or two releases, what's on the roadmap that people should watch for?
I'd like to draw attention to the Volume Health feature. This feature is designed to offer critical visibility into the operational status and integrity of persistent volumes. By enabling storage drivers and the Kubernetes control plane to report issues, it allows for proactive monitoring and identification of volume-related problems.
Currently, volume health information is reported via non-persistent events. We are actively investigating enhancements to this feature with the goal of supporting automated remediation capabilities in the future.
Are there areas where you'd really like more discussion or help from the community?
We always need help from the community to fix bugs, add tests, and help with reviews.
We'd also like to get feedback on the Alpha feature Mutable PV Affinity, which was introduced in Kubernetes v1.35. Use cases include migrating volumes from zonal to regional storage or migrating from one disk type to another.
Another topic is volume replication. It was raised at KubeCon Atlanta and has been discussed in the Data Protection WG. Community members interested in this topic are encouraged to join the DP WG meetings.
What are the biggest challenges users face today when running stateful workloads on Kubernetes?
While Kubernetes has moved stateful workloads - like databases and AI pipelines - into the mainstream, managing "state" in a system designed for ephemerality remains difficult:
-
Data Gravity and Storage Locality: Pods move in seconds, but data has gravity. If a node fails, a pod using local storage is stuck. Operators must decide whether the failure is transient or permanent - a high-stakes call. This is why we are enhancing the Volume Health feature to provide the visibility needed to automate recovery choices.
-
Day 2 Complexity: Setting up a database is easy; maintaining its health over time is the real challenge. Standard Kubernetes objects like StatefulSets offer a baseline, but they lack the operational logic needed for tasks such as schema upgrades, engine patching, or cluster-wide Kubernetes upgrades.
-
Data Mobility: Moving persistent data remains a significant hurdle - whether migrating between storage tiers, shifting workloads across availability zones, or moving to a different cluster. This challenge includes ongoing synchronization and replication for high availability and disaster recovery across a distributed system.
Storage and AI
How do you see storage evolving in Kubernetes over the next few years, especially as AI/ML workloads grow?
I see several trends shaping storage in Kubernetes as it evolves from a container orchestrator into the "Operating System" for AI:
-
More Intelligent Data Management: We'll see a shift toward smarter CSI drivers and data management tools offering advanced features like automatic tiering, snapshots, migration, and replication - optimized specifically for high-performance AI/ML workflows and large data platforms.
-
Object Storage as a First-Class Citizen: AI datasets now frequently reach exabyte scale, making object storage the preferred choice for AI workloads. COSI is standardizing bucket management just as CSI did for disks, allowing data scientists to use a BucketClaim to provision S3-compatible storage natively and unifying object, file, and block storage into a single workflow.
-
Performance and Low Latency: For AI/ML, storage needs to keep up with GPU processing speeds. This will accelerate adoption of high-performance parallel file systems and NVMe-over-Fabrics (NVMe-oF) technologies managed natively via Kubernetes. The line between traditional block/file and memory-speed storage will continue to blur.
-
Data-Aware Scheduling: Instead of just considering CPU and RAM, the Kubernetes scheduler will increasingly prioritize placing Pods based on data locality - calculating the cost of moving data versus moving compute to keep massive data platforms performant.
SIG Storage continues to tackle some of the hardest problems in Kubernetes: keeping stateful applications running reliably, making storage operations transparent and composable, and now scaling up to meet the demands of AI-era workloads. Whether you're a user managing databases in production or a developer curious about storage internals, there's a place for you in SIG Storage.
If you'd like to get involved, check out the SIG Storage community page and join the bi-weekly meetings. You can also find the SIG on Slack at #sig-storage.
15 Jun 2026 12:00am GMT
14 Jun 2026
Linuxiac
Linuxiac Weekly Wrap-Up: Week 24, 2026 (June 8 – 14)

Catch up on the latest Linux news: Alpine 3.24, Linux kernel 7.1, COSMIC Desktop 1.0.16, Wine 11.11, Yserver is a new X11 server for Linux, and more.
14 Jun 2026 11:51pm GMT
DietPi 10.5 Enables KMS/DRM by Default on Raspberry Pi

DietPi 10.5 switches Raspberry Pi GUI installs to KMS/DRM by default, updates camera handling, and reworks display configuration.
14 Jun 2026 10:59pm GMT
OMG! Ubuntu
Linux 7.1 brings new NTFS driver, Steam Deck OLED audio fix + more
 Linux 7.1 arrives with a rewritten NTFS driver, Apple Silicon battery reporting, and Steam Deck OLED audio fixes alongside massive legacy code removals.
Linux 7.1 arrives with a rewritten NTFS driver, Apple Silicon battery reporting, and Steam Deck OLED audio fixes alongside massive legacy code removals.
You're reading Linux 7.1 brings new NTFS driver, Steam Deck OLED audio fix + more, a blog post from OMG! Ubuntu. Do not reproduce elsewhere without permission.
14 Jun 2026 8:21pm GMT
12 Jun 2026
Ubuntu blog
A decade of Ubuntu on IBM Z and IBM LinuxONE
This year we celebrate a decade of Ubuntu Server support on the s390x architecture: marking a long-standing collaboration between Canonical and IBM that began at LinuxCon 2015. The first release happened on April 21, 2016, bringing Ubuntu 16.04 LTS (Xenial Xerus) to IBM Z and IBM LinuxONE platforms. A first for Ubuntu on IBM That […]
12 Jun 2026 6:13pm GMT
11 Jun 2026
Ubuntu blog
AI at the edge: simplifying infrastructure with Cisco and Canonical
Legacy infrastructure was not designed for the requirements of the AI era. While large-scale model training remains centralized in data centers, test-time inference is rapidly shifting to the edge to reduce latency and bandwidth consumption. This shift creates a new frontier for enterprise AI, but deploying at the edge introduces significant manual complexity, interoperability issues, […]
11 Jun 2026 7:25pm GMT
OMG! Ubuntu
LibreOffice gives its Ribbon-style UI a pop of colour
 You'll be able to customise the look of LibreOffice's Tabbed UI in the free office suite's next major release, which his due out in August 2026. LibreOffice 26.8's Tabbed UI (also known as the Notebookbar and modelled after the Ribbon in Microsoft Office) can show a colourful background when application theming is enabled under Tools > Options > Appearance. A blue shade is used by default but you can pick or set any colour you like. In the 'Customisations' section, first selected the Writer, Calc, Impress or Data Notebookbar value, then use the dropdown to chance the colour. Click apply […]
You'll be able to customise the look of LibreOffice's Tabbed UI in the free office suite's next major release, which his due out in August 2026. LibreOffice 26.8's Tabbed UI (also known as the Notebookbar and modelled after the Ribbon in Microsoft Office) can show a colourful background when application theming is enabled under Tools > Options > Appearance. A blue shade is used by default but you can pick or set any colour you like. In the 'Customisations' section, first selected the Writer, Calc, Impress or Data Notebookbar value, then use the dropdown to chance the colour. Click apply […]
You're reading LibreOffice gives its Ribbon-style UI a pop of colour, a blog post from OMG! Ubuntu. Do not reproduce elsewhere without permission.
11 Jun 2026 6:48pm GMT
Ubuntu blog
The next era of telco clouds: get open infrastructure choice with Sylva and Canonical Kubernetes
Achieving vendor neutrality in telco clouds requires an infrastructure layer that respects open standards, without wrapping them in rigid platform layers. By combining upstream alignment with up to 15 years of support longevity, Canonical's approach to Sylva is built around a requirement that matters deeply to telcos: follow upstream cloud-native innovation when developing and evolving platforms, then rely on long-term support to keep production environments stable, trusted, and operationally predictable.
11 Jun 2026 10:34am GMT
10 Jun 2026
OMG! Ubuntu
Microsoft brings Rust Coreutils to Windows – natively
 Microsoft has released Coreutils for Windows, allowing a stack of familiar "Linux-like" command-line utilities to run natively on Windows. The project is based on uutils, the Rust-based reimplementation of GNU coreutils that Ubuntu (mostly) has adopted in recent releases. Microsoft's package bundles uutils' coreutils and findutils as well as a GNU-compatible grep in a single binary. It offers tools like cat, cp, ls, mv and uptime. Commands that use POSIX-only features are excluded, meaning chmod, chown, kill and others aren't included. What's notable - *nix tools working their way into the Windows ecosystem is notable - is that this isn't […]
Microsoft has released Coreutils for Windows, allowing a stack of familiar "Linux-like" command-line utilities to run natively on Windows. The project is based on uutils, the Rust-based reimplementation of GNU coreutils that Ubuntu (mostly) has adopted in recent releases. Microsoft's package bundles uutils' coreutils and findutils as well as a GNU-compatible grep in a single binary. It offers tools like cat, cp, ls, mv and uptime. Commands that use POSIX-only features are excluded, meaning chmod, chown, kill and others aren't included. What's notable - *nix tools working their way into the Windows ecosystem is notable - is that this isn't […]
You're reading Microsoft brings Rust Coreutils to Windows - natively, a blog post from OMG! Ubuntu. Do not reproduce elsewhere without permission.
10 Jun 2026 4:21pm GMT
09 Jun 2026
JavaScript Weekly
VoidZero → Cloudflare, and Angular 22 lands
|

09 Jun 2026 12:00am GMT
02 Jun 2026
JavaScript Weekly
How to vet an npm package in 2026
|


02 Jun 2026 12:00am GMT
01 Jun 2026
Kubernetes Blog
From Kubernetes Dashboard to Headlamp: Understanding the Transition
For many people, Kubernetes Dashboard was their first window into Kubernetes. It offered a simple visual way to see what was running in a cluster, inspect resources, and build confidence without relying on the command line. For years, it helped developers, students, and operators make sense of Kubernetes, and it served as an important onramp into the ecosystem.
The Kubernetes Dashboard project has now been archived. We deeply respect the work the team did and the role Dashboard played in making Kubernetes more approachable for so many users.
Headlamp builds on that foundation and carries it forward. It keeps the clarity of a visual interface while adding capabilities that match how Kubernetes is used today. This includes multi-cluster visibility, application-centric views, extensibility through plugins, and flexible deployment options that work both in-cluster and on the desktop.
This guide is meant to help you navigate that transition with confidence. Before diving into the mechanics of migration, we start with familiar ground by looking at how common Kubernetes Dashboard workflows map to Headlamp. We also cover what stays the same and what improves after the switch. The goal is not just to replace a tool, but to honor a user-centered legacy and help you land in a UI that can grow with you as your Kubernetes usage evolves.
Mapping Kubernetes Dashboard workloads to Headlamp
If you have used Kubernetes Dashboard before, many workflows in Headlamp will feel familiar. Headlamp does not introduce a new way of thinking. Instead, it builds on workloads users already know and extends them in practical ways. The focus is continuity. What worked before still works, with more room to grow.
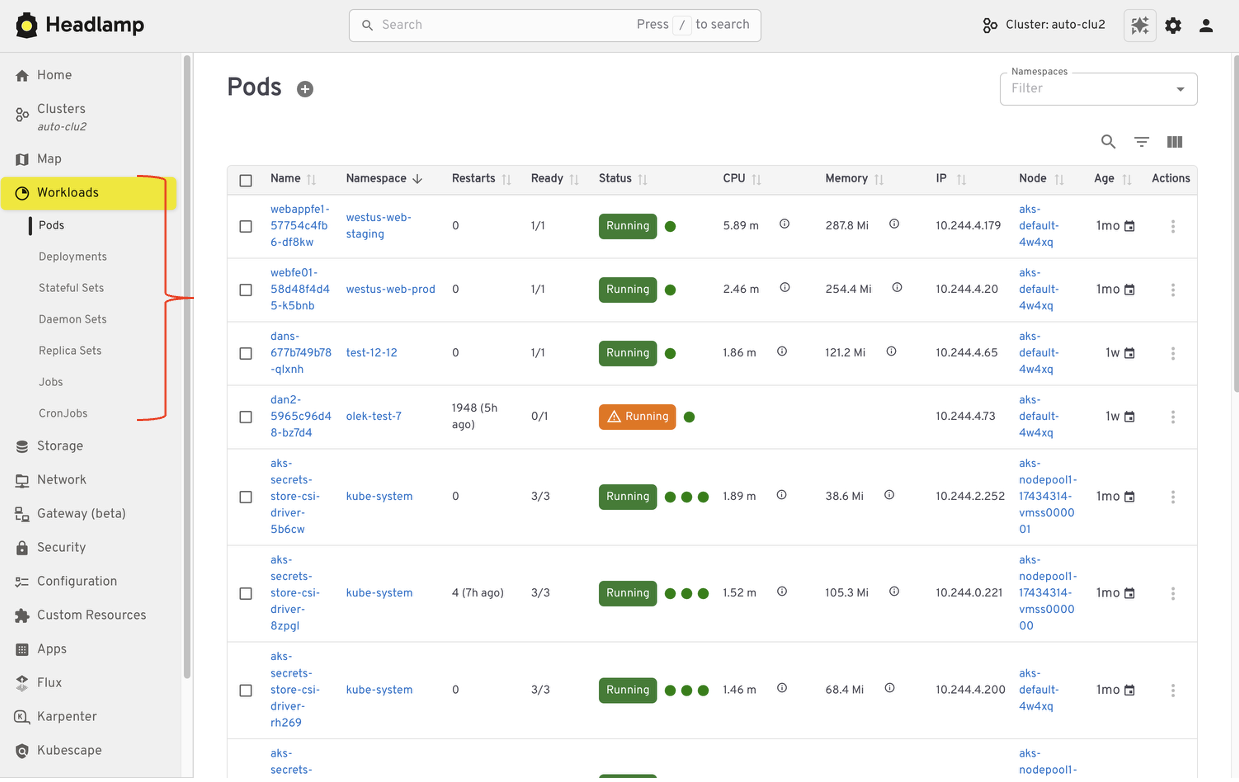
Viewing workloads and resources
In Kubernetes Dashboard, most users started by browsing workloads like pods, deployments, services, and namespaces. Headlamp keeps this same starting point. Workloads are easy to find and inspect, and moving between namespaces and clusters is simpler. Resources are still organized in familiar ways, and navigation feels smoother, especially when you work across multiple environments.
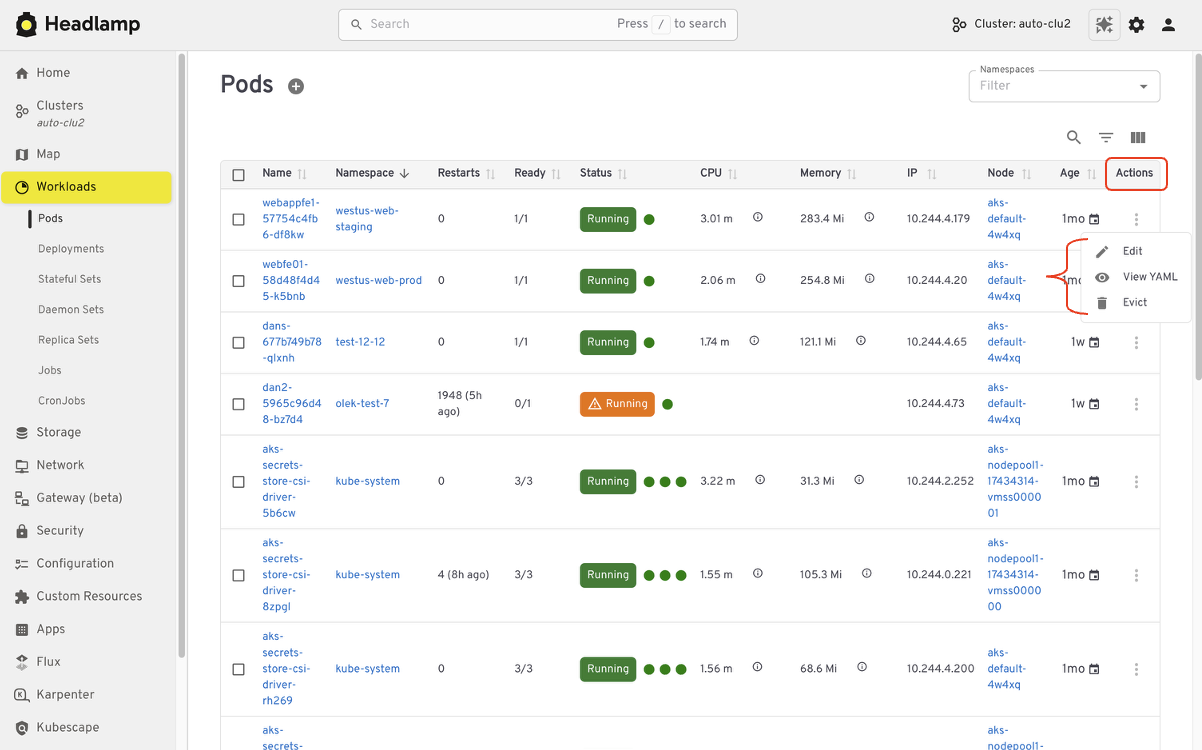
Editing and interacting with resources
Like Kubernetes Dashboard, Headlamp lets you view and edit manifests directly in the UI based on your permissions. You can delete resources, scale workloads, or update configurations from the interface. All actions follow standard Kubernetes RBAC. If you could perform an action in Dashboard, you will find the same capability in Headlamp, with the same respect for access controls.
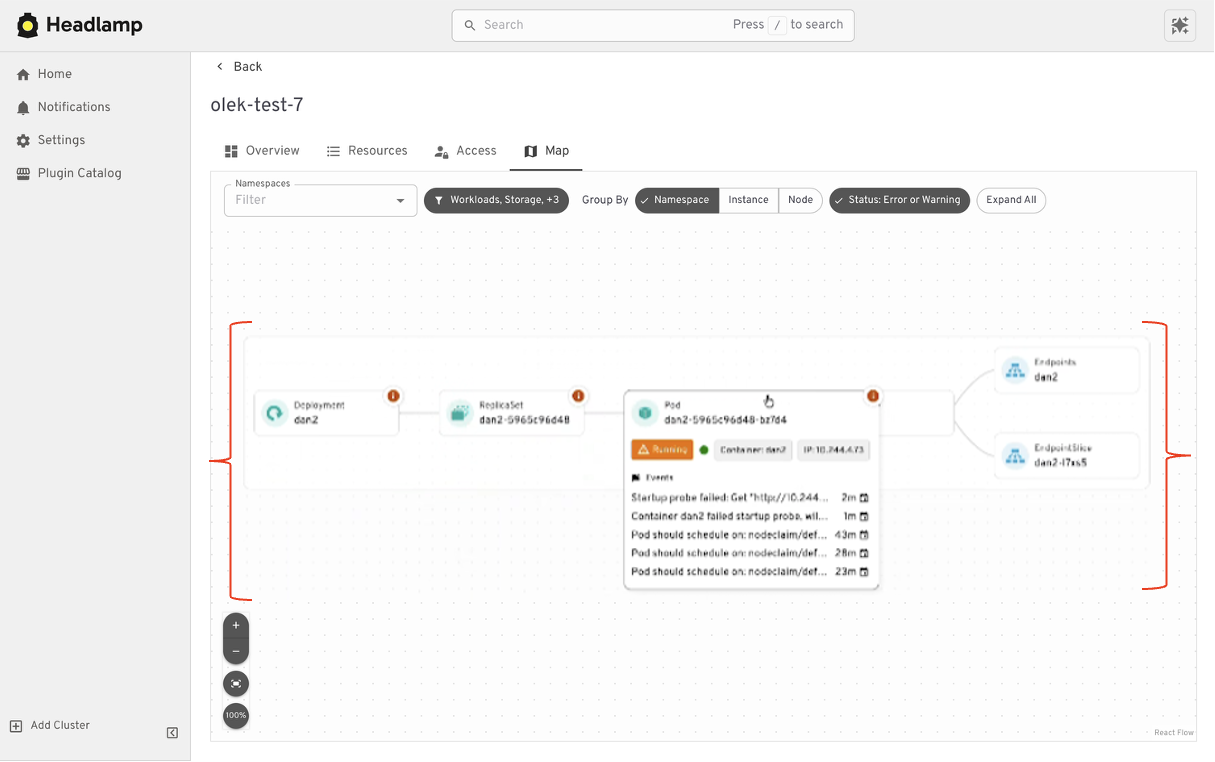
Understanding relationships
Where Headlamp begins to expand the experience is in how it presents relationships between resources. In addition to list views, Headlamp offers visual ways to see how workloads, services, and configurations connect. This helps provide context without changing the underlying workloads users already rely on.
At a high level, the tasks you performed in Kubernetes Dashboard are still there. Headlamp keeps familiar workflows while making it easier to scale as clusters, teams, and applications grow.
Where Headlamp goes beyond Kubernetes Dashboard
Expanding from single cluster to multi-cluster workflows
Kubernetes Dashboard was designed to work with one cluster at a time. That model worked well for simple setups, but it became limiting as teams adopted multiple environments. Headlamp expands this view by letting you work with multiple clusters from a single interface without switching tools or losing context. This makes it easier to manage development, staging, and production environments side by side.
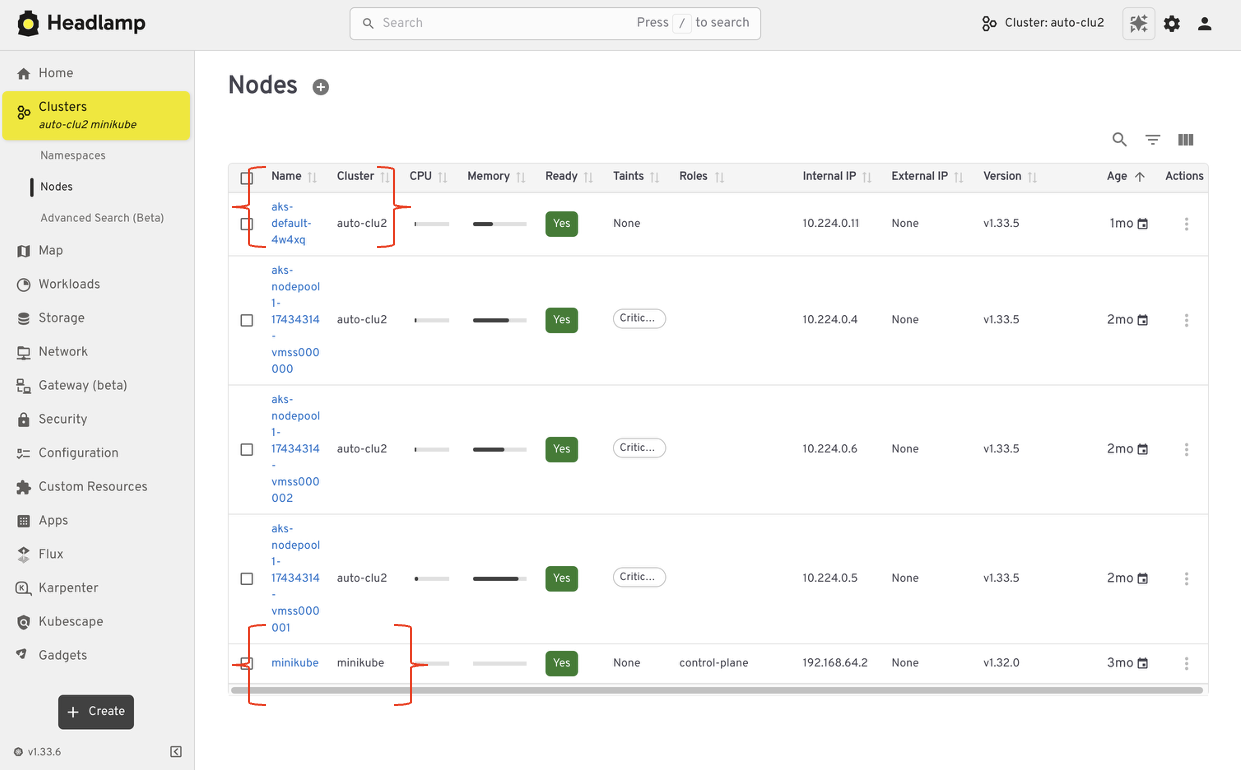
For teams running Kubernetes in more than one place, this shift reduces friction. You can stay oriented and move between clusters with confidence.
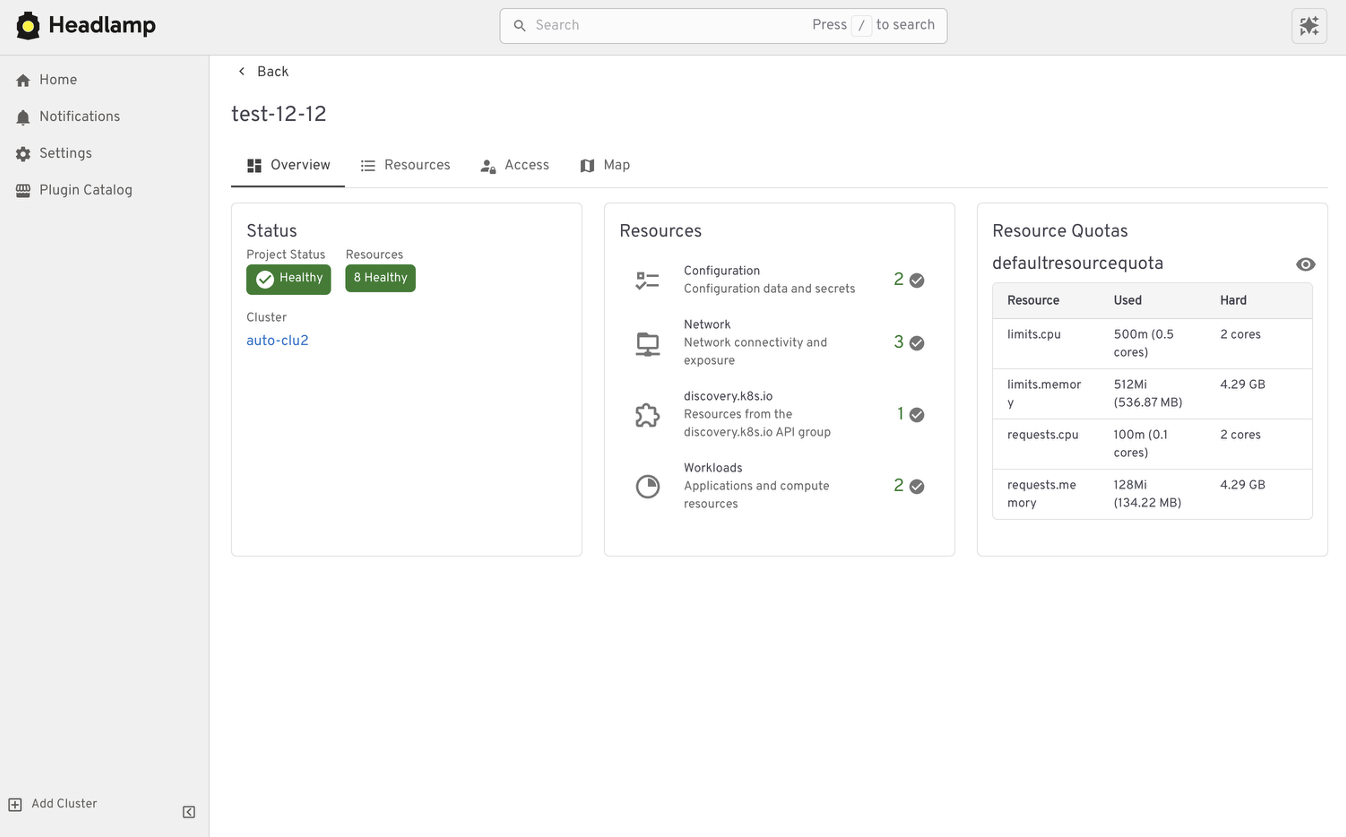
From resource lists to application context with Projects
Projects give you an application-centered way to view Kubernetes. Instead of jumping between lists, you can group related workloads, services, and supporting resources in one place. This makes applications easier to understand. You can see what belongs together, track changes in context, and troubleshoot without scanning the cluster piece by piece.
Projects are built on native Kubernetes concepts. Namespaces, labels, and RBAC continue to work the same way they always have. Headlamp adds a visual layer that brings related resources together.
Projects are optional. You can still work at the individual resource level when that fits your task. When you need more context, Projects help you step back and see the bigger picture.
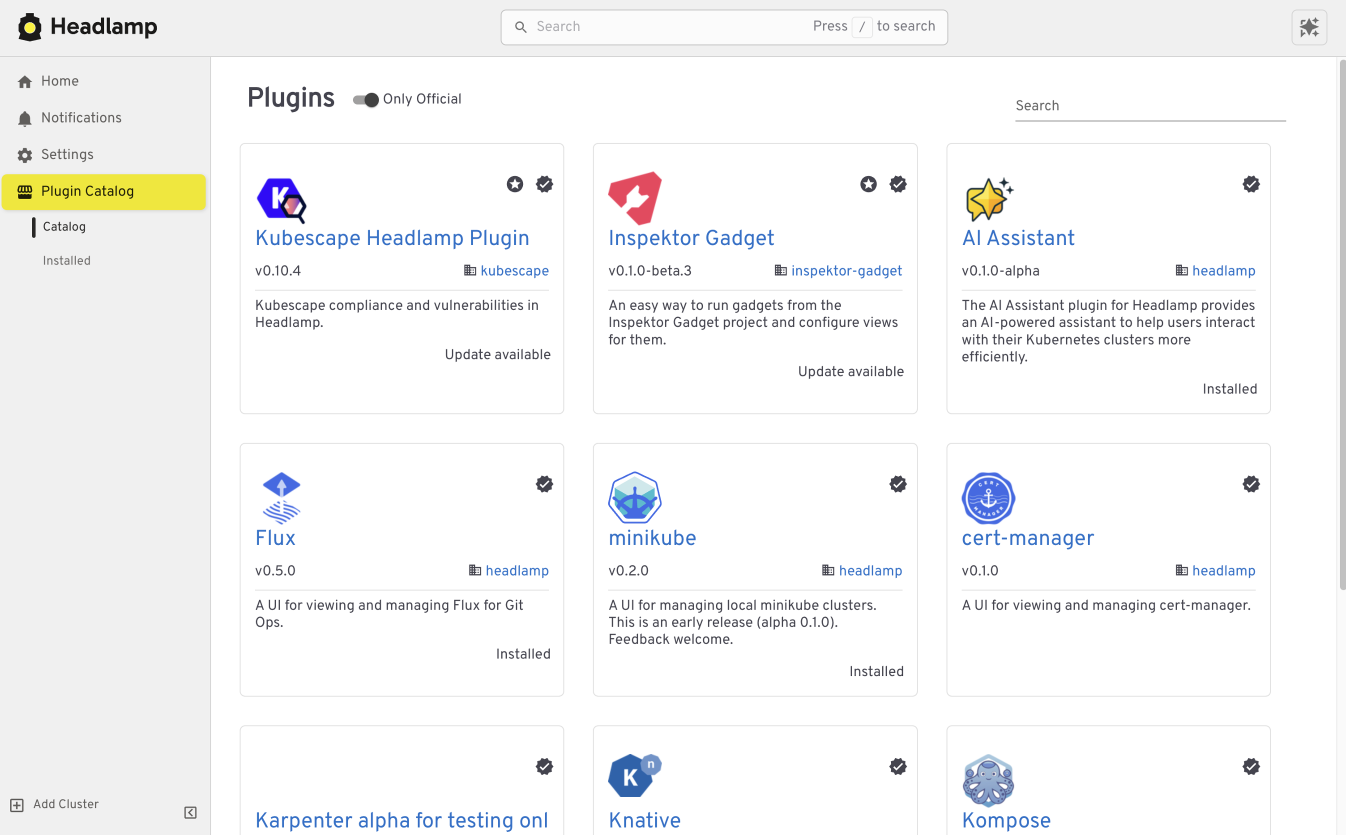
Extend the Headlamp UI with plugins
Headlamp can be extended through plugins that bring common workflows directly into the UI. Instead of switching tools, you work in one place with the same context.
For example, the Flux plugin brings GitOps workflows into Headlamp. It allows teams to view application state alongside the Kubernetes resources that Flux manages, making it easier to understand how changes in Git relate to what is running in the cluster.
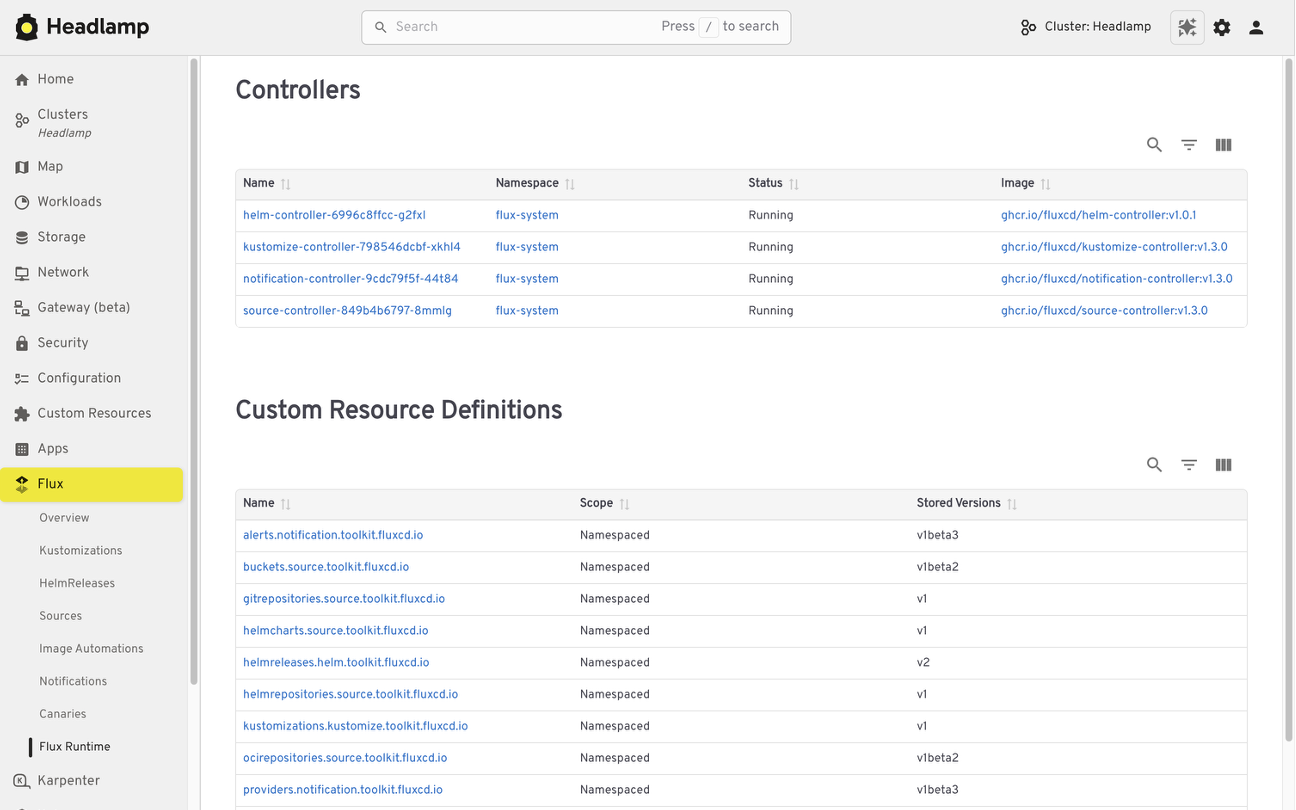
The AI Assistant follows a similar pattern. It adds a conversational layer to the UI that helps users understand what they are seeing, troubleshoot issues, or take action. All of this happens in the same screen where the problem appears.
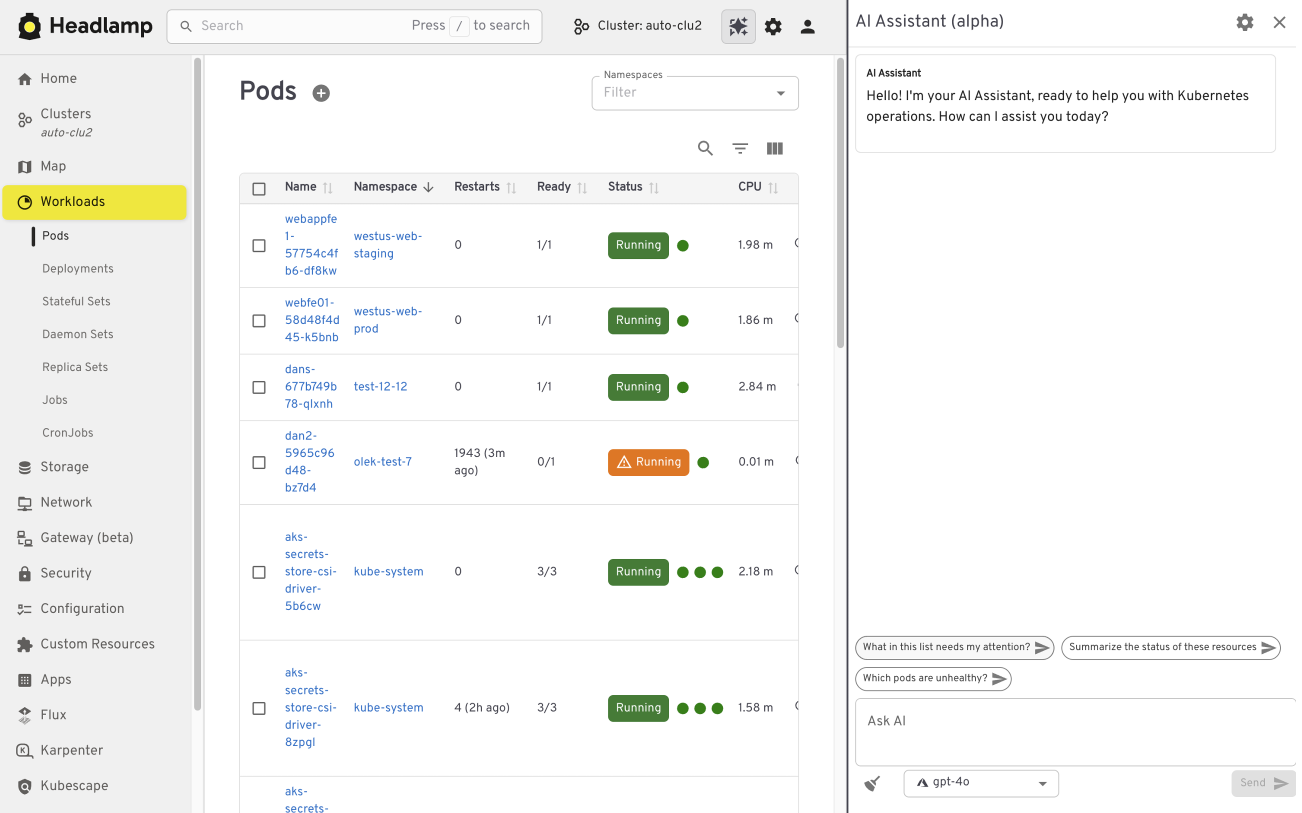
Building your own plugins
Plugins are optional and not limited to community-built extensions. Platform and project teams can also create their own plugins. This allows organizations to add custom integrations that match their specific workflows and internal tooling, while keeping the user experience consistent.
Choosing how and where Headlamp runs
Headlamp gives teams flexibility in how they use a Kubernetes UI. You can run it directly in a cluster, use it as a desktop application, or combine both approaches based on your needs.
Running Headlamp in-cluster works well for shared environments. It provides a centrally managed UI with controlled access and fits naturally into Kubernetes setups, following the same authentication and RBAC rules as other in-cluster components.
The desktop application is often a better fit for local development and onboarding. It also works well when you need to manage multiple clusters from one place. Users can connect using their existing kubeconfig without deploying anything into the cluster.
These options are not mutually exclusive. Many teams use the desktop app for day-to-day work, while relying on an in-cluster deployment for shared or production environments.
Preparing for the Migration
Before moving from Kubernetes Dashboard to Headlamp, it can be helpful to pause and take stock of how you use the Dashboard today. A little reflection up front can go a long way toward making the transition feel smooth and familiar.
Start by noting which clusters and namespaces you access and how authentication works. Headlamp relies on standard Kubernetes authentication and RBAC. In most cases, existing access models carry over without change. If users already connect using kubeconfig files or service accounts, they will be able to access the same resources in Headlamp.
It is also useful to think about the workflows that matter most to your team. Some users rely on Dashboard for quick inspection or troubleshooting, while others use it for lightweight edits or validation. Headlamp supports these same workflows and adds optional capabilities on top. Knowing what you rely on today helps the transition feel predictable and confidence building.
If you would like to explore Headlamp or try it out before migrating, you can learn more at headlamp.dev.
This blog focused on understanding the transition and what to expect. A step by step migration guide is coming soon and will walk through installation and migration in detail.
01 Jun 2026 6:00pm GMT
26 May 2026
Kubernetes Blog
Reconciling the Past: Correcting Records for Unfixed Kubernetes CVEs
The Kubernetes project relies on transparency to empower cluster administrators and security researchers. One important way we do that is by publishing CVE records into the Common Vulnerabilities and Exposures database. As part of our ongoing effort to mature the official Kubernetes CVE Feed, we have identified some discrepancies. CVE records for a few older, unfixed issues incorrectly include a fixed version field.
The Kubernetes Security Response Committee (SRC) will correct the affected CVE records on June 1, 2026. This may result in vulnerability scanners identifying these vulnerabilities in places where they were previously not detected.
To help reduce confusion, this post provides a technical update on three vulnerabilities that were disclosed in previous years but remain unfixed: CVE-2020-8561, CVE-2020-8562, and CVE-2021-25740.
Why we are updating these records now
While these vulnerabilities have been public for several years, the recent work to generate official Open Source Vulnerabilities (OSV) files revealed that their corresponding CVE records did not accurately reflect their status. Specifically, some records suggested a fixed version existed, when in reality, these issues are architectural design trade-offs that cannot be fully remediated through code without breaking fundamental Kubernetes functionality.
Correcting these records is vital for the community for:
- Automation Fidelity: Modern vulnerability scanners depend on precise version ranges. Inaccurate fixed tags lead to false negatives, giving users a false sense of security.
- Risk Documentation: By formalizing these as unfixed, we ensure that platform providers and administrators are aware of the persistent need for administrative mitigations.
For completeness, we should also mention that CVE-2020-8554 is an unfixed CVE with a correct CVE record stating that it affects all versions. That record will also be updated to use a more-standardized version number format.
Technical analysis of unfixed architectural risks
The following vulnerabilities will not be fixed by the Kubernetes project. GitHub issues remain the best reference for the technical mechanics of these flaws.
CVE-2020-8561: Webhook redirect in kube-apiserver
- Severity: Medium (4.1).
- The Issue: The kube-apiserver follows HTTP redirects when communicating with admission webhooks. An actor capable of configuring an AdmissionWebhookConfiguration can redirect API server requests to internal, private networks.
- Why it remains unfixed: Restricting this behavior would require breaking the standard HTTP client behavior that many legitimate integrations rely on.
- Mitigation: Set the API server log level to less than 10 (to prevent logging response bodies) and disable dynamic profiling (
--profiling=false) to prevent unauthorized log-level changes.
CVE-2020-8562: Proxy bypass via DNS TOCTOU
- Severity: Low (3.1).
- The Issue: A Time-of-Check to Time-of-Use (TOCTOU) race condition in the API server proxy allows users to bypass IP restrictions. The system performs a DNS check to validate an IP, but then performs a second resolution for the actual connection, which an attacker can manipulate.
- Why it remains unfixed: Fixing this requires pinning resolved IPs in a way that breaks complex split-horizon DNS or dynamic IP environments.
- Mitigation: Use a local DNS caching server like dnsmasq for the API server and configure
min-cache-ttlto enforce consistent responses between the check and the connection.
CVE-2021-25740: Cross-namespace forwarding via Endpoints
- Severity: Low (3.1).
- The Issue: A design flaw in the Endpoints and EndpointSlice API objects allows users to manually specify IP addresses, which can be used to point a LoadBalancer or Ingress toward backends in other namespaces.
- Why it remains unfixed: This is a fundamental feature of the Endpoints API used by many networking tools and operators.
- Mitigation: Restrict write access to Endpoints (legacy) and EndpointSlices. Since Kubernetes 1.22, Kubernetes RBAC authorization mode no longer includes those permissions in the default edit and admin ClusterRoles. That removal applies to clusters created using Kubernetes v1.22; for clusters upgraded from older versions, administrators should manually audit and reconcile the
system:aggregate-to-editClusterRole.
Note:
On June 1, 2026, these CVE records will be updated to correctly reflect the fact that all versions are affected. You may see them begin to appear in vulnerability scanner results.Required actions for administrators
The Kubernetes project recommends a secure by configuration approach to manage these persistent risks:
| Vulnerability | Action item | Severity score (Rating) | Command / configuration |
|---|---|---|---|
| CVE-2020-8561 | Restrict Log Verbosity | 4.1 (Medium) | Ensure --v is set to < 10 and --profiling=false. |
| CVE-2020-8562 | Enforce DNS Consistency | 3.1 (Low) | Deploy dnsmasq or a similar caching resolver on control plane nodes. |
| CVE-2021-25740 | Hardened RBAC | 3.1 (Low) | kubectl auth reconcile to remove Endpoints write access from broad roles. |
The RBAC action for CVE-2021-25740 applies when your cluster uses RBAC authorization mode, which is the default for clusters created with standard Kubernetes tooling. Administrators should independently test and validate these configurations in a non-production environment, assessing the architectural risks against their specific threat model and risk tolerance.
Conclusion: maturity through transparency
The effort to reconcile these records is a sign of a maturing security ecosystem. By moving away from the "patch-only" mindset and accurately documenting architectural debt, the Kubernetes project provides the community with the high-fidelity data needed to secure modern cloud native infrastructure.
We would like to thank the security researchers-QiQi Xu, Javier Provecho, and others-who identified these risks, and the SIG Security Tooling contributors who continue to refine our official feeds. Special shoutout to Rory McCune for sharing information around these CVEs through his blog posts.
Update 2026/06/01: Today, the Kubernetes SRC has updated the CVE records for CVE-2020-8554, CVE-2020-8561, CVE-2020-8562, and CVE-2021-25740.
26 May 2026 5:30pm GMT
JavaScript Weekly
npm and pnpm introduce staged publishing
|


26 May 2026 12:00am GMT