02 Aug 2026
 Planet KDE | English
Planet KDE | English
Implementing Rich Text in Drawy
for the past few months i have been working on implementing rich text in drawy as part of google summer of code 2026.
Overview on the old implementation:
The old text logic depended on a manual implementation, almost everything was built from scratch using a string. Placing the cursor, caret movement, selection operations, line and word boundary detection, editing operations were all implemented from scratch.
I found implementing all of this impressive, but while it worked for plain text editing, this code was hard to maintain / extend, and it would have been nearly impossible to add the features that were added.
Phase 1: Refactoring
Goal: Rewrite without breaking anything
I replaced the string with QTextDocument , all the things that were written manually before was gone and now editing operations are handled by QTextCursor.
| Operation | How it was done | How it is done now |
|---|---|---|
| Placing cursor | Binary search over the line, measuring substring widths with QFontMetrics to find which character the click landed on. |
documentLayout()->hitTest() |
| Caret movement | Manual index calculation increment/decrement; up/down walked to the previous/next \n |
cursor.movePosition(Left/Right/Up/Down/WordLeft/WordRight) |
| Selection | Two indices, with selection rectangles rebuilt line-by-line using QFontMetrics |
QTextCursor anchor/position, drawn via QAbstractTextDocumentLayout::Selection |
| Word/line boundary detection | Manual scan for separator characters or \n |
cursor.select(WordUnderCursor / LineUnderCursor) |
Phase 2: Rich Text
1. adding IME support
An Input Method Editor (IME) is how the OS handles input for languages that can't be typed with a single key press per character without it user can't type with Arabic, Japanese, Chinese, dead keys, etc The OS sends this as a QInputMethodEvent, which Drawy previously didn't handle. IME now works correctly here is demonstration of how it works with CJK input:
https://youtu.be/2W2R9udyKKU?si=BLwUmLpcg_E9XE9T
2. Properties:
user now have much more control over properties i added support for choosing font family, font style, text alignment, list format.
per range formatting is also now implemented meaning user can set different colors, size, font, style to different parts of the text.


3. Word Wrapping:
When the text box is resized, text now wraps to fit within its bounds.
https://www.youtube.com/watch?v=AqGJd5Bf6sw
4. undo / redo:
text history is managed by two stacks: drawy global stack, and QTextDocument's internal one. Only one is active at a time. While the user is editing text, the global stack is disabled and QTextDocument's internal stack takes over, handling text edits and property changes, etc. Once the user exits edit mode, the internal stack is disabled again, any changes go through Drawy's global stack instead, stored as HTML.
5. Spell checking
In my proposal, I didn't plan much time for spell checking, I thought that I'd just wire Sonnet in and be done with it. I later found out that Sonnet's ready-made integrations are built for QTextEdit and QML, so I had to write my own spell-checking pipeline instead.
-
Each block (paragraph) is passed to
Sonnet::gusserto guess its language and determine which dictionary to use. -
Text is split into words using
QTextBoundaryFinder. -
Sonnet::Spellerchecks whether each word is misspelled. -
Misspelled words are highlighted using
QSyntaxHighlighter.
added new menu to settings using Sonnet::ConfigWidget to allow customizing spell checking:

Note: Everything mentioned in this blog is on the
gsoc2026branch currently and will be merged once GSoC is completed.
Gratitude:
I am very grateful to my mentor Laurent Montel for his time and effort guiding me throughout this project.
02 Aug 2026 1:56pm GMT
01 Aug 2026
Planet KDE | English
June/July in KDE Itinerary
Time for another bi-monthly update on what happened around Itinerary! Since the previous report there's a new combined journey view, support for ride sharing services and new Apple Wallet pass formats, among many other things.
New Features
New combined journey view
With more and more journeys being backed by online realtime and schedule data, access to the journey details (intermediate stops, journey map view, etc) via nested actions has become increasingly cumbersome. Therefore Jonah redesigned the details pages for all transport entries (trains, buses, ferries, flights) to have a new bottom toolbar to easily access that information.
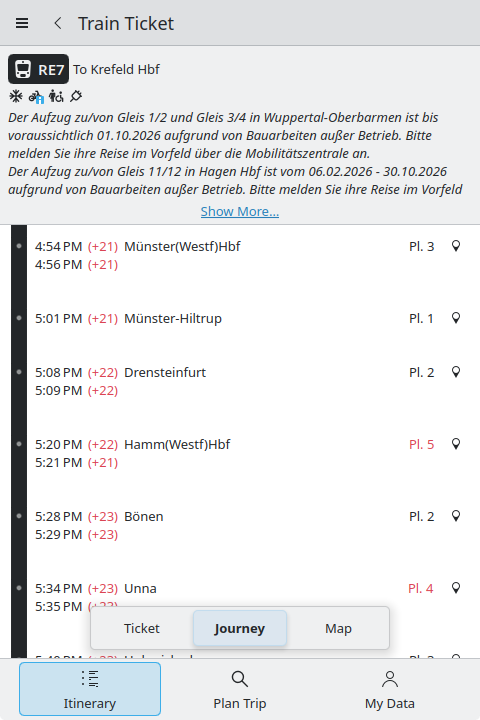
The journey details view now also allows to query public transport departures at any intermediate stop, which is useful e.g. when doing manual rerouting in case of more complex disruptions.
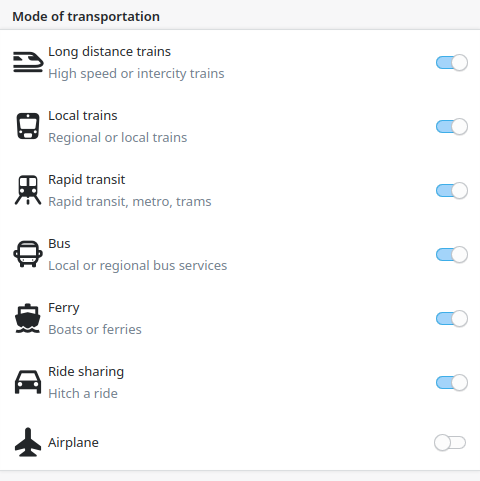
Ride sharing
After Transitous got support for ride sharing earlier this year, this has now also reached out client applications. Both Itinerary and KTrip have a mode filter for this now, and Itinerary can add ride sharing trips to the timeline.
New Apple Wallet pass formats
Itinerary can now display a new variant of the Apple Wallet pass format, so-called "poster event tickets". Conceptually those are similar to the existing event tickets but have very different layout and content, which wouldn't render at all so far.
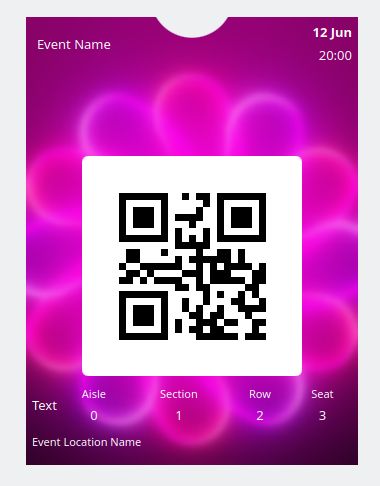
The background blur effect and some of the font sizes are still off, but at least the relevant content is now displayed correctly.
There's also a few format additions affecting all pass types that are now supported:
- Four additional barcode types (EAN13, Code 39, Codabar and ITF).
- Multi-row auxiliary fields.
- RGBA color values.
A few gaps in the existing format support were also fixed while at it:
- Correctly displaying date-only and time-only fields.
- Finding image assets only existing in a higher pixel ratio variant.
- Fixed organization and description fields not being translated.
Besides the visual representation Apple Wallet passes can in newer versions also contain machine-readable semantic information about their content, something that is now used in the travel document extractor as well.
Infrastructure Work
Booking links in Transitous
Thanks to Jonah's work, MOTIS, the routing engine behind Transitous got support for the GTFS Transit Ticketing Extension. This makes booking links available for more operators, which are then shown by Itinerary or KTrip.
Android and Linux platform integration
There has been generic work on platform integration for all of KDE's (mobile) apps, which of course also benefits Itinerary.
For Android there's a dedicated blog post. Since then locale-aware comparisons have been fixed in Qt (for 6.13), and Itinerary got built-in crash reporting that is already helping during development. Some necessary changes to finally fix not being able to open files from cloud shares is still stuck in review though.
For Linux the focus has been on permission checks and GPS access in a Flatpak sandbox (blog post). The foundation for the Qt permission API to support the Flatpak persmission system has been integrated meanwhile, for Qt 6.13.
Indoor OSM standardization
There also have been efforts on evolving and standardizing modelling and mapping of indoor spaces in OpenStreetMap. While that is of course done with the entire OSM ecosystem in mind, it also benefits Itinerary, Transitous and Kongress. There it helps with improving routing through buildings and with visualizing building interiors.
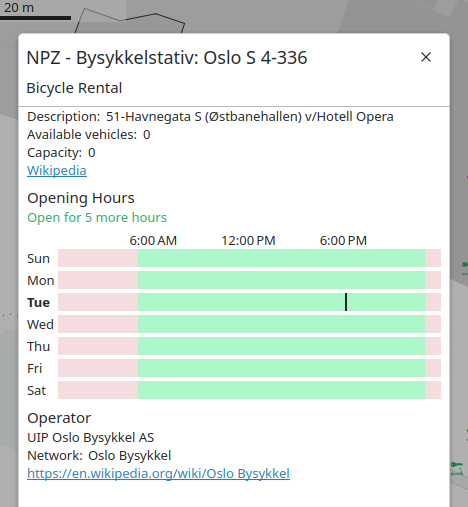
GBFS v3 support continued
The previous report had mentioned work on improving the support for GBFS v3 sharing vehicle data. This continued and now also has some more visibile results:
- The GBFS feed database has been updated to contain about 1.500 feeds from all over the world, and can now be online updated independent of the application itself.
- Rider capacity for vehicles is shown when available (mainly relevant for cars).
- Opening hours of rental vehicle stations or rental vehicle networks can now be displayed.
Events
A few members of the Transitous community will be at State of the Map 2026 in Paris end of August, and I'll be speaking about Transitous there.
In September there's KDE Akademy 2026 in Graz, which is probably one of the largest gatherings of the Itinerary community. I'll be presenting how continuous delivery helps Itinerary with QA.

Beginning of October we have the second Open Transport Community Conference in Bern, both the Transitous and the Itinerary community will be present there. A few tickets are still available.
Fixes & Improvements
Travel document extractor
- New or improved extractors for 12go, Accor, BDŽ, Collegeboard, Doodle, DRK, Flixbus, HVV, IRCTC, KTMB, PKP, Polferries, Sportio, SRT, Ticketspot and VR.
- Fixed extracting return descriptions from standard UIC FCB NRT ticket barcodes (bug 520826).
This has been made possible thanks to your travel document donations!
Public transport data
- Allow location searches without explicitly selecting a country.
- Improved aggregation and sorting of stop search results.
- Added support for Amtrak onboard API.
- Added support for resolving locations from coordinates and booking URLs for LTG Link.
- Fixed sorting of countries on the backend configuration page.
- Fixed DB booking URLs for connections where they don't actually sell tickets.
- Fixed displaying text on light line colors with light color schemes.
All of this also directly benefits KTrip.
Itinerary app
- Allow to add transfers between multi-day events.
- Fixed activating booking links on details pages.
- Fixed too narrow global drawer.
- Fixed timer overflow on timeline updates for trips too far in the future.
- Fixed notification configuration when running in a Flatpak sandbox.
- The time picker on Linux now has a button to easily select "now".
- Fixed France accidentally not being considered part of the EU roaming area.
- Show all reserved seat numbers on the vehicle layout page.
How you can help
Feedback and travel document samples are very much welcome, as are all other forms of contributions. Feel free to join us in the KDE Itinerary Matrix channel.
01 Aug 2026 6:15am GMT
This Week in Plasma: Emoji Resizing
Welcome to a new issue of This Week in Plasma!
…but before we start, here's a quick reminder that we've entered the last week to submit your proposal for the next KDE Goals cycle! If you're not ready to champion a goal, you can still get involved by joining one of the existing proposals as a contributor or supporter.
And now, without further ado…
In addition to the headliner feature and expected UI improvements and bug fixes, this week features some promising technical and performance improvements. Have a look:
Notable new features
Plasma 6.8
You can now make the emojis in the Emoji Selector window bigger or smaller. (Jason Uithol, plasma-desktop MR #3878)
On System Settings' Display Configuration page, you can now move screens pixel-by-pixel using the arrow keys while in layout editing mode. (Antti Savolainen, kscreen MR #476)
Notable UI improvements
Plasma 6.7.4
The Emoji Selector window is now always tall enough to accommodate its sidebar without scrolling. (Christoph Wolk, KDE Bugzilla #523090)
Spectacle now detects QR codes in screenshots that you take in such a manner that the main UI is never shown; if you click "Annotate" from the notification about it, the QR code will be detected there. (Kai Uwe Broulik, KDE Bugzilla #521097)
Plasma 6.8
In Spectacle's settings window, image quality controls are now only available for image types whose quality level is adjustable. (Zhora Zmeykin, spectacle MR #568)
Clarified the instructions on System Settings's Remote Desktop page a little bit. (Nate Graham, krdp MR #224 and krdp MR #225)
Kup 0.11.0
Modernized the UI for the Kup backup system's System Tray widget, so now it matches other Plasma widgets that can similarly show multiple items, each with their own actions. (Bharadwaj Raju and Tomáš Hnyk, kup MR #53 and kup MR #54)
 New
New Old
OldNotable bug fixes
Plasma 6.6.7
Fixed a case where the ksystemstats background service could crash seemingly randomly. (Méven Car, KDE Bugzilla #523562)
Fixed a recent regression that made blank document icons appear in the notification history view. (Kai Uwe Broulik, KDE Bugzilla #522846)
Fixed a bug that could make extremely long words in Plasma tooltips overflow rather than wrapping. (Nate Graham, KDE Bugzilla #523614)
Fixed a bug that made third-party widgets fail to inhibit power management more than once. (Vincent de Robert, KDE Bugzilla #523605)
Plasma 6.7.4
Fixed a visual glitch where the highlight area for expanded list items in various System Tray widgets would sometimes be too small to fit its contents. (Bharadwaj Raju, KDE Bugzilla #506295)
Plasma 6.8
Fixed an issue that could sometimes corrupt very large screenshots taken in Spectacle when they were pasted elsewhere. (Cezar Craciunoiu, spectacle MR #566)
Frameworks 6.29
Opening various windows and dialogs using Kirigami components no longer makes the content scroll into view for no particularly good reason. (Manuel Alcaraz Zambrano, KDE Bugzilla #515811)
ddcutil 2.2.8
Fixed multiple issues that could make the powerdevil background process freeze or crash. (Sanford Rockowitz, ddcutil issue #581 and ddcutil issue #587)
Notable in performance & technical
Plasma 6.8
Significantly improved performance with external GPUs. Read more about this on Xaver's blog! (Xaver Hugl, kwin MR #7101)
You can now change the size (and effective resolution) of virtual screens created for screencasting, rather than them being fixed to a resolution of 1920 × 1080 pixels. (David Edmundson, KDE Bugzilla #512620)
Panel floating-ness can now be changed using Plasma desktop scripting. (Ramil Nurmanov, KDE Bugzilla #521549)
KWin now recognizes the "Pick up phone" and "Hang up phone" keys on some keyboards, allowing them to be used in keyboard shortcuts to trigger actions. (Méven Car, kwin MR #7892)
Frameworks 6.29
Fixed a performance issue that could make Plasma freeze when it sent a notification with a lot of emojis in it. (Devin Lin, KDE Bugzilla #508070)
How you can help
KDE has become important in the world, and your time and contributions have helped us get there. As we grow, we need your support to keep KDE sustainable.
Would you like to help put together this weekly report? Introduce yourself in the Matrix room and join the team!
Beyond that, you can help KDE by directly getting involved in any other projects. Donating time is actually more impactful than donating money. Each contributor makes a huge difference in KDE - you are not a number or a cog in a machine! You don't have to be a programmer, either; many other opportunities exist.
You can also help out by making a donation! This helps cover operational costs, salaries, travel expenses for contributors, and in general just keeps KDE bringing Free Software to the world.
To get a new Plasma feature or a bug fix mentioned here
Push a commit to the relevant merge request on invent.kde.org.
01 Aug 2026 12:00am GMT
31 Jul 2026
Planet KDE | English
Web Review, Week 2026-31
Let's go for my web review for the week 2026-31.
Sovereignty is a substrate
Tags: tech, hardware, supply-chain, complexity
Interesting piece which shows very well the complexity of the hardware supply chain. The parts which matter the most are largely ignored by everyone.
https://negroniventurestudios.com/2026/07/28/sovereignty-is-a-substrate/
Do LLMs know how to make software? (No.)
Tags: tech, ai, machine-learning, gpt, copilot
Funny, I was using that exact same term recently: "brute-force driven development". It describes fairly well how the harnesses work.
https://mir.aculo.us/do-llms-know-how-to-make-software-no/
Getting access to the /tmp of a systemd service with PrivateTmp=yes
Tags: tech, systemd
Don't forget, it's all namespaces!
https://utcc.utoronto.ca/~cks/space/blog/linux/SystemdPrivateTmpWhere
The Hamburger Database Design Pattern
Tags: tech, databases, design, pattern
Interesting pattern for managing materialized views over a long time.
Memory-level parallelism: AMD is the king
Tags: tech, cpu, amd, performance
They're definitely handling this part right, they seem well ahead everyone else.
https://lemire.me/blog/2026/07/25/memory-level-parallelism-amd-is-the-king/
C++26: Reducing undefined behaviour
Tags: tech, c++, standard, safety, reliability
More signs of C++26 being an important new standard for reliability and safety.
https://www.sandordargo.com/blog/2026/07/29/cpp26-reduces-undefined-behaviour
C++ float-to-int conversion can be undefined behavior
Tags: tech, c++, safety
This is a bigger trap than it sounds. It is very easy to fall into it.
https://kttnr.net/blog/cpp-float-to-int-conversion-undefined-behavior/
Learn WebGPU for C++ documentation
Tags: tech, web, webgpu, graphics
Curious about WebGPU? This looks like it'll become a very good resource for that.
https://eliemichel.github.io/LearnWebGPU/
The Website Specification
Tags: tech, web, standard
This is very comprehensive! It is also overwhelming… So many things to think about when making a website nowadays.
https://specification.website/
What even are microservices?
Tags: tech, architecture, microservices
Since I still hear about "microservices" more often than I'd like to. Here is another piece which points the trade-offs and that really there's no one size fits all.
https://var0.xyz/posts/what-even-are-microservices.html
Code Review Responses: Add Context When It Counts
Tags: tech, codereview
There are indeed cases where it's important to provide more context on the code which changed following up a comment by the reviewer.
https://testing.googleblog.com/2026/05/code-review-responses-add-context-when.html?m=1
How I Find Problems to Solve as a Staff Engineer
Tags: tech, engineering, leadership, problem-solving
Good approach, you indeed need to immerse yourself in the context and see the recurring patterns. That's the best way to figure out impactful solutions to recurring issues.
https://lalitm.com/post/find-problems-staff-engineer/
Your harddrive is probably full
Tags: tech, storage, resources, procrastination
Interesting take, it's more than just about hard drives being full. Indeed, there are many things on which we tend to procrastinate. But on the other hand… so many budgets to track otherwise!
https://www.marginalia.nu/log/a_139_hdd/
The Crossover Project
Tags: tech, software, engineering, agile, craftsmanship
Very interesting series I previously missed. It explores if software engineering is really engineering, and the differences with other engineering fields. Quite a few nice lessons to draw from it.
https://www.hillelwayne.com/tags/crossover-project/
Kaizen Board: A Reply on Every Sheet
Tags: tech, quality, kaizen, japan
Wondering how that works when it runs properly? Here is an example of a Kaizen board in a japanese factory.
https://www.leanblog.org/2026/07/kaizen-board-manager-comments/
Bye for now!
31 Jul 2026 4:17pm GMT
Fixing Multi-GPU performance, part 1
Performance on "secondary" GPUs has historically been suboptimal on Linux, especially with external GPUs. Let's take a look at why it's slow, and how we're finally fixing it.
How Multi-GPU even works
To know how things work with multiple GPUs, we first need to look at how applications present images in single GPU systems.
With Wayland, the linux-dmabuf protocol is used for sharing images from applications to the compositor. The compositor advertises which GPU it's using, and a list of drm formats1 and format modifiers2 it can make use of.
The application then allocates a dma-buf (direct memory access buffer) for each image with one of the supported formats + modifiers on the GPU of the compositor, and sends the compositor file descriptors for these buffers to share them.
This works quite well, but only for single GPU systems. In linux-dmabuf version 5, the compositor can only advertise one GPU as being usable! The app could still attempt to pass the buffer of any GPU to the compositor, but that can fail, requiring fallbacks, and it can cause really big performance issues.
Why it's slow
When you import a dma-buf to a GPU, the kernel tries to be helpful and automatically ensures for you that the GPU you're using can access the buffer. This sounds nice, and can be useful, but it's also the source of all our performance problems.
Let's say you have a laptop with an integrated GPU, and a dedicated GPU. When you start a game on the dedicated GPU, what would happen is
- the game allocates a buffer on the dedicated GPU
- it passes that buffer to the compositor
- the compositor imports the buffer into the integrated GPU
To make step 3 work, the kernel would move3 the buffer to system memory. This can be really terrible for performance, since system memory is terribly slow in comparison to video memory, and the dedicated GPU has to go through the PCIe bus to access it, which has high latency.
To solve that problem, Vulkan and OpenGL drivers compare the GPU the application is using with the one the compositor advertises. If they're not the same, then the driver will not share the buffers on the GPU with the compositor, but actually create a copy in system memory and share that copy with the compositor instead. So this would be
- the game allocates a buffer on the dedicated GPU
- the driver copies the buffer to another buffer in system memory
- it passes that other buffer to the compositor
- the compositor imports the buffer into the integrated GPU
Now imagine you're not playing the game on your laptop display, but you have an external display connected to the dedicated GPU. The HDMI port on a lot of laptops is wired to the dedicated GPU, so this is a really common scenario. What happens in that case is
- the game allocates a buffer on the dedicated GPU
- the driver copies the buffer to another buffer in system memory
- it passes that other buffer to the compositor
- the compositor imports that other buffer into the integrated GPU
- the compositor composites with the integrated GPU
- the compositor copies the composited result to the dedicated GPU
So your game gets copied to system memory and back to video memory, for no real reason. The performance hit caused by that isn't great in general, but it gets so much worse with external GPUs.
When all you have is one USB C cable to transfer data from and to the GPU, with high resolution monitors the bandwidth of that cable can be too small even for copying in one direction! Going in both directions completely kills performance. For example, I have a setup with
- a Framework laptop 13
- a rx 5700 XT in an external GPU enclosure
- a 5120x1440 monitor at 120Hz connected to the external GPU
If I start vkcube (a super simple test app) on the external GPU, move it to the monitor and make it fullscreen, it only reaches 55fps!
How to fix it
In principle, we "just" need to stop the driver from copying the buffer around, and instead have it pass the original buffer from the dedicated GPU to the compositor. That's exactly what I proposed version 6 of the linux-dmabuf protocol for: The compositor can support a list of GPUs instead of just one, and the application can tell the compositor which GPU it should import a given buffer into.
This all sounds nice and simple in theory, but as always, it wasn't quite that simple in practice. There are basically three problems that needed to be solved for this change to be useful:
- the driver needs to not do the copies unless actually necessary
- the compositor needs to do the copies when required
- to actually get any performance gains, the compositor needs to skip the copies whenever possible
Thankfully, I didn't need to do this alone. Victoria Brekenfeld from System76 implemented support for the protocol in Mesa and Smithay, the library used by the cosmic compositor.
Unfortunately, it took a long time to support the protocol in a useful way in KWin. I needed to make it
- aware of multiple GPUs beyond just displaying on them
- properly handle GPU hotplug with that new infrastructure
- deal with all the weird GPU setups in embedded systems
- track which GPU each buffer is on
- have generic multi GPU copy infrastructure
- make those multi GPU copies actually as fast as the copies Mesa does internally
- deal with GPU resets correctly while doing multi GPU copies
- actually implement the Wayland protocol bits
Some of this was just moving code from out drm backend to more generic places, but a lot of it required doing things from scratch. Especially GPU reset handling was challenging because KWin's effects APIs make a lot of assumptions about OpenGL contexts and didn't support just stopping rendering a frame once it started.
While working on this, I also added Vulkan support to KWin specifically to make the multi GPU copies as fast as possible, which also took some time. As a positive side-effect though, we now have basic Vulkan infrastructure in KWin that can be used for a future Vulkan renderer.
Finally, just over 2 years after I first proposed the protocol, we had complete enough implementations to prove it works as expected and the protocol was merged. Since then, the KWin implementation was merged, the Mesa implementation should be merged soon and Nvidia has an (as of time of writing, unreleased) implementation of the protocol in their driver as well.
The actual performance gains
So, how much does this actually help? With vkcube, we go from 55 fps to the full 120 fps of the monitor, but that's hardly a practically relevant test.
So I fired up Cyberpunk 2077 with the "low" graphics preset and it went from 27 fps with Mesa main to 50 fps with linux-dmabuf v6. That's more than 80% better performance!
| Mesa main | Mesa with dmabuf v6 |
|---|---|
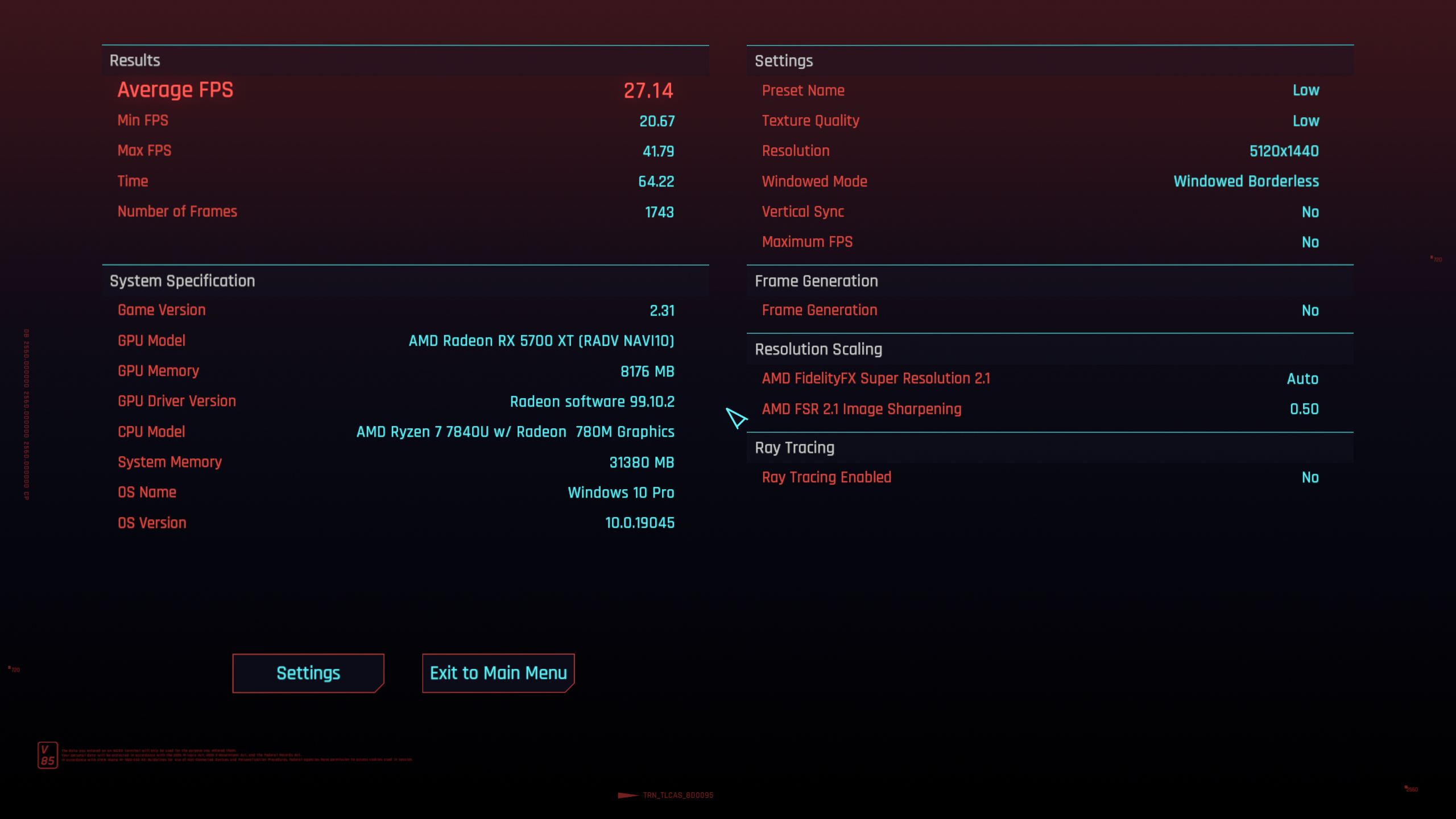 |
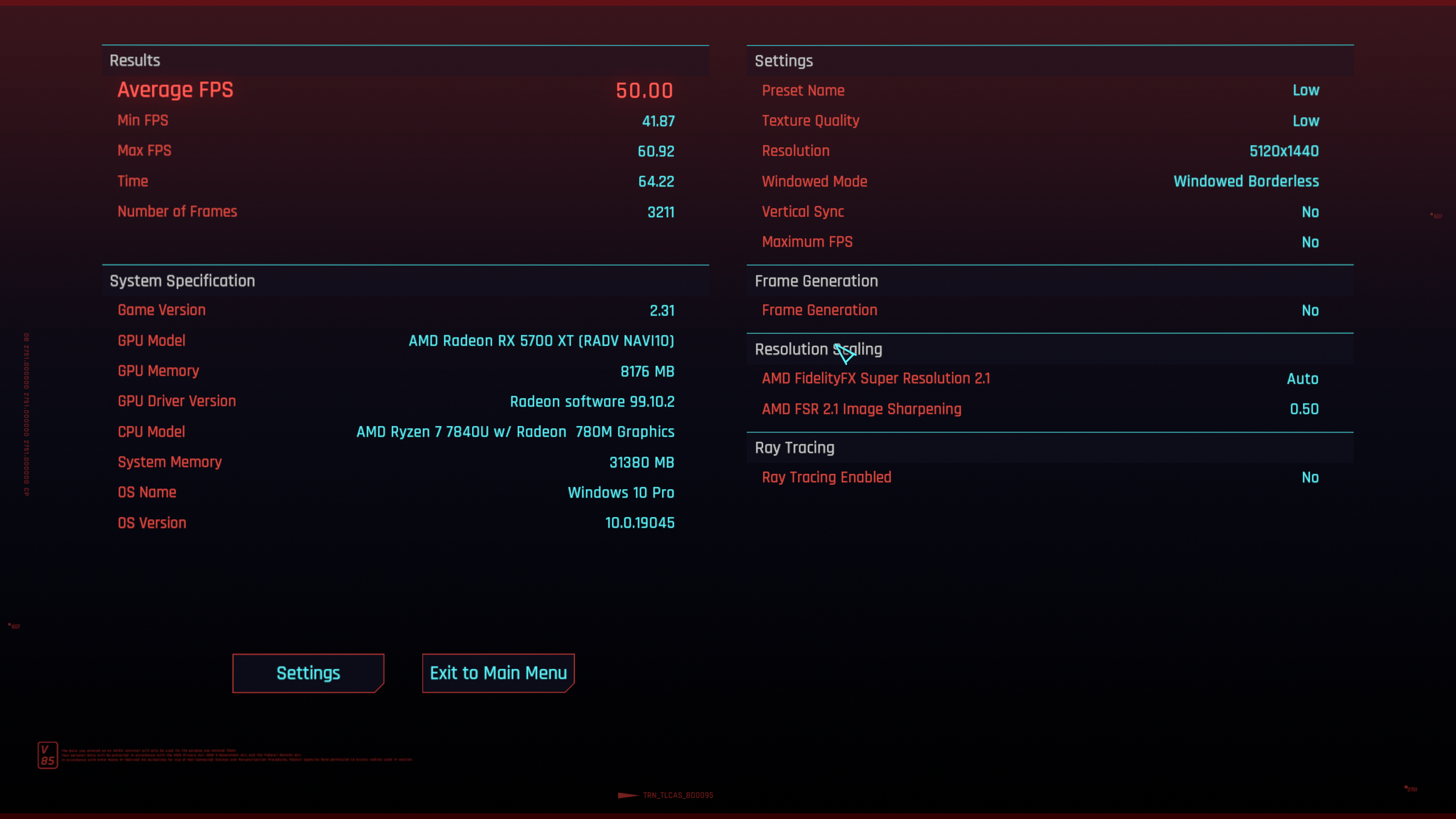 |
From playing around a bit with the graphics settings, it seems likely that the game is bottlenecked by the USB C bandwidth, so the performance uplift could be even better with additional driver optimizations.
I haven't been able to benchmark the impact of dmabuf v6 on "normal" laptop setups, because I don't yet have access to a Nvidia Vulkan driver version implementing the protocol, and I don't have a laptop with a dedicated AMD GPU. If I had to guess though, I'd expect improvements there to be much more moderate, probably something in the 5-10% range. I'll update this post once I know more.
However, this performance uplift comes with two big caveats…
When does this work?
With the current KWin implementation, compositing always happens on the "primary" GPU. On laptops, by default that's whatever GPU the internal display was connected to when KWin started. This means you can only get those large benefits if the game gets direct scanout.
My rx 5700 XT doesn't have support for color pipelines, so I only get the performance benefit if HDR is disabled, night light is disabled and no color profile is used. I already have a merge request to lift that restriction though, stay tuned for part 2 to find out more about that!
There is another caveat though, and that's a far bigger challenge: Most games still run on X11, and implementing the protocol (in a useful way) in Xwayland is incredibly challenging because of some assumptions X11 makes. I don't know how that could be fixed, or even if it's feasible at all, so for now, you can only get these benefits with games using Wayland directly.
For a lot of native games, using SDL_VIDEODRIVER=wayland does the trick, and for most Windows games, you can use Proton forks with the Wine Wayland driver. In my experience, Wine Wayland works really well and even HDR just works™ with it nowadays.
31 Jul 2026 2:50pm GMT
30 Jul 2026
Planet KDE | English
Qt Creator 20.0.1 released
We are happy to announce the release of Qt Creator 20.0.1!
The release improves tool detection and the default session directory for chats in the AI Agent Client Protocol integration, fixes various issues with CMake Presets as well as some crashes, and contains various other improvements.
![]()
30 Jul 2026 9:31am GMT
29 Jul 2026
Planet KDE | English
Krita 5.3.3 Released!
Today we're releasing Krita 5.3.3 and 6.0.3, containing many bugfixes and improvements across the board.
Android Donations and Supporter benefits
On Android, version 5.3.3 lets you support Krita's development directly through the application. This goes through the Play Store, so if you have a device without Google services or are using a debug or nightly version of Krita, it won't be available and instead will show you donation links.
In return for supporting Krita, you'll be able to download resource bundles directly in the application, including the paid Digital Atelier bundle. The splash screen and welcome page will also tell you about the supporter packs or donation links. You are not required to make any purchases, no features are locked behind a paywall and you won't get nagged about it while you're actually working. You can also of course still manually import resource bundles, the downloads are just a convenience feature.
For a longer explanation and a way to give feedback or ideas, take a look at this forum post.
Changelog
Special thanks to Freya Lupen and Elena Sagalaeva, for multiple bug fixes, as well as the many newcomers who contributed to this release (named in the changelog).
- Don't free hold frame undo command at scope exit (Bug 520732)
- Added get started, community, website and source code icons (Thanks to Arkady Flury)
- Try removing shell=True from the python calls on Windows
- Get rid of division by zero in the KisMplTest.( Thanks to Elena Sagalaeva)
- [android] All animation export and import functionality has been removed for now. Mostly because these functions didn't do anything. We're working on a properly working replacement for Android specifically.
- Delete QuaZipFile before deleting the archive (Bug 520362)
- Fix layers getting deselected when starting transform (Bug 517590)
- Ensure a layer is activated for new views (Bug 518465 , Thanks to Gregg Jansen van Vuren)
- Fix FFmpeg 7.0+ to render HDR animations (Bug 520669)
- Fix Out-of-Bounds-Selection-Inversion (Bug 518235, Thanks to Ricky Ringler)
- Fix Display Selection action check stats
- Fix crash on null event pointer in Abstract Input Action (Bug 520581)
- Fix crash when deleting a text shape (Bug 520939)
- Fix not loading some xmp exif metadata correctly (Bug 520981)
- Omit invalid values for xmp metadata when saving (Bug 520982)
- Fix crash with combined shapes (Bug 521106)
- [android] Implement supporter benefits
- Make welcome page not show missing shortcuts as X
- Allow welcome page to shrink properly
- [android] Handle full-screen mode directly
- [android] Let the user set the UI scale at runtime
- UI/Animation: Fixed some animation actions breaking when switching playback engines. (Bug 518711)
- UI/Settings: Fix bad animation settings layout.
- [win][qt6] Fix transparent canvas widget issue (Bug 517102)
- Force non-var vertical metrics to use default vertical caret. (Bug 517717)
- Fix font-family sorting for fonts with wwsWithoutName set mixed.(Bug 518874)
- Try to deduplicate font family names better, so we don't get sql errors. (Bug 517361)
- Fix bug 522430. Switching between frames should always complete. (Bug 522430)
- Fix deadlock when doing perspective transform (Bug 520602)
- Expose tool and brush change signals to PyKrita (Thanks, Moritz Staudinger)
- Various fixes to the selection action panel, including the ability to stick it to the sides of the canvas by pressing the "pin" icon.
- Various fixes to the comic panel editing tool functionality.
- Allow higher resolution of thumbnails on Welcome Screen.
⚠️ Warning
We consider Krita 5.3.3 suitable for productive work; 6.0.3 is, because of the many changes from Qt5 to Qt6 more experimental.
Download 5.3.3
Windows
If you're using the portable zip files, just open the zip file in Explorer and drag the folder somewhere convenient, then double-click on the Krita icon in the folder. This will not impact an installed version of Krita, though it will share your settings and custom resources with your regular installed version of Krita. For reporting crashes, also get the debug symbols folder.
ⓘ Note
We are no longer making 32-bit Windows builds.
-
64 bits Windows Installer: krita-x64-5.3.3-setup.exe
-
Portable 64 bits Windows: krita-x64-5.3.3.zip
Linux
Note: starting with recent releases, the minimum supported distro versions may change.
⚠️ Warning
Starting with recent AppImage runtime updates, some AppImageLauncher versions may be incompatible. See AppImage runtime docs for troubleshooting.
- 64 bits Linux: krita-5.3.3-x86_64.AppImage
MacOS
⚠️ Warning
With Krita 5.3.3 release minimum supported MacOS version has increased from 10.14 (Mojave) to 10.15 (Catalina)
- MacOS disk image: krita-5.3.3-signed.dmg
Android
Krita on Android is still beta; tablets only.
Source code
Source code is the same as 6.0.3. See the 6.0.3 section.
md5sum
For all downloads, visit https://download.kde.org/stable/krita/5.3.3/ and click on "Details" to get the hashes.
Key
The Linux AppImage and the source tarballs are signed. You can retrieve the public key here. The signatures are here (filenames ending in .sig).
Download 6.0.3
Windows
If you're using the portable zip files, just open the zip file in Explorer and drag the folder somewhere convenient, then double-click on the Krita icon in the folder. This will not impact an installed version of Krita, though it will share your settings and custom resources with your regular installed version of Krita. For reporting crashes, also get the debug symbols folder.
ⓘ Note
We are no longer making 32-bit Windows builds.
-
64 bits Windows Installer: krita-x64-6.0.3-setup.exe
-
Portable 64 bits Windows: krita-x64-6.0.3.zip
Linux
Note: starting with recent releases, the minimum supported distro versions may change.
⚠️ Warning
Starting with recent AppImage runtime updates, some AppImageLauncher versions may be incompatible. See AppImage runtime docs for troubleshooting.
- 64 bits Linux: krita-6.0.3-x86_64.AppImage
MacOS
Note: minimum supported MacOS may change between releases.
- MacOS disk image: krita-6.0.3-signed.dmg
Android
Krita 6.0.3 is not yet functional on Android, so we are not making APK's available for sideloading.
Source code
md5sum
For all downloads, visit https://download.kde.org/stable/krita/6.0.3/ and click on "Details" to get the hashes.
Key
The Linux AppImage and the source tarballs are signed. You can retrieve the public key here. The signatures are here (filenames ending in .sig).
29 Jul 2026 12:00am GMT
GSoC Alumni Camp Delhi 2026
GSoC Alumni Camp Delhi 2026 - My Experience
I attended the GSoC Alumni Camp in Delhi, it was an amazing opportunity to make people who are already familiar with open source aware of KDE Community and I was actually able to do that. The event itself was from 8:00 A.M. to 10:30 P.M. at night. The event started off with a formal opening session. Soon after was the scavenger hunt (we were hunting people!) it was a 5x5 grid where you needed to get signatures of people who fit the question in the box. A few of them were :
- I was born in July (I signed a lot of them )
- I have held a koala
- I know 3+ languages
- I can juggle
- I prefer go/Rust and so on. In all honesty it was an amazing ice breaker and something to get to know people. After that there were a few unconferences followed by lunch and then more unconferences till 6:00 P.M. after that lightning talk sessions started and fortunately I got to represent KDE.
Unconference Session - From GSoC Student to Maintainer/Mentor
I also hosted one of the first unconference sessions titled:
From GSoC Student to Maintainer/Mentor
I wasn't expecting a large audience, but at one point the room was at its capacity around 40 attendees.
The audience included:
- GSoC Organization Administrators
- Mentors
- Open source employees
- Existing contributors
- Google code-in students
The discussion focused on contributor retention after GSoC and how organizations can better support contributors beyond the program. It led to some interesting discussions where we found out what some organisations are doing.
Discussion Points (Noted by an org admin)
Leverage Contributors as Subject Matter Experts
GSoC contributors naturally become subject matter experts for the components they build. When new issues, bug reports, or pull requests relate to their work, proactively invite them to participate in the discussion or review. This helps contributors feel that their expertise is valued and keeps them engaged with the project beyond GSoC.
Improve Communication Around Pull Request Reviews
Complex pull requests often require focused reviews and may take longer than isolated bug fixes. While taking the necessary time for a thorough review is important, mentors should acknowledge review requests and, where possible, communicate an expected timeline. Even a brief acknowledgment improves the contributor experience.
Using Organization Stipends for Contributor Retention
Explore using the GSoC organization stipend to support promising contributors after the program ends. This could fund continued maintenance or feature development through a transparent platform such as Open Collective, allowing contributors to invoice for their work and remain actively involved with the project.
Recognizing Mentor Contributions
Mentoring requires a significant investment of time in reviewing code, guiding contributors, and providing technical support. Consider allocating a portion of the organization stipend to compensate mentors, recognizing their efforts and encouraging long-term participation.
KDE's Community Support
Another topic that generated considerable interest was KDE's support for its contributors.
I talked about how KDE sponsors some students to attend Akademy, and how I was also sponsored to attend the event, which a lot of people agreed organizations should've done (some did, a lot didn't) but a lot of people agreed that when an organization consider these things contributors stay.
After all the unconferences ended a lot of people came up to me saying mine was the best and I managed and engaged everyone in the best way possible ( I was on cloud 9).
Lightning Talk
One of the highlights was being selected to give a lightning talk. Only 18 participants were chosen, and I was one of them.
My GSoC project Join KDE is an advertisement for KDE itself, so the project itself became an easy conversation starter. It was a great opportunity to introduce KDE and make more people aware of the organization.
Although I did fumble the last part of my presentation it was more of me being confused where my slide went (some slides were misplaced) aside from that it went as any other informative talk but hey I was funny on the stage (refer to the pics) so people remember me! You win some you lose some, oh well.
Conversations Throughout the Event
Outside the sessions, I had some interesting discussions with contributors from different organizations. Some contributors showed interest in working wwith us while some showed interest in our eduction/science side but honestly it's hard to bring contributors over as they're in different domains, org admins/mentors or they're busy with their careers.
SU2 Foundation
I had a conversation with a maintainer from the SU2 Foundation, whose work focuses on computational fluid dynamics.
We discussed KDE's scientific and educational initiatives, including KDE for Scientists and several education-related projects. I also shared the KDE For You website as an introduction to the wider KDE ecosystem.
After Party
The conversations continued during the after-party on the following day.
I met a group of students who had become interested in open source after interacting with contributors throughout the event. They had originally attended as friends of another contributor.
One of them is now actively looking for a project to begin contributing to within KDE. YAYYY!
New Contributors
Several first-time contributors approached me asking about projects suitable for beginners.
I introduced them to a number of KDE projects and explained possible contribution paths.
But the same issue they're busy with the beginning of their careers.
Overall Thoughts
The Alumni Camp was one of the best ways to make people aware of KDE and I tried my best while i had fun ( we played uno there! Will bill the cards to the organization jkjk), a lot of people seemed intrigued and asked me to share some stuff about KDE to them or they'll try it on their own. Met someone from GNOME (they didn't get any lightning talk HA! I know, I know no inter project fighting that's bad) had some good conversations, teased the person from GNOME, had breakfast with them, and tried to make the most of the unconference session and the lightning talks to at least get people to know the name KDE!
Event Gallery







29 Jul 2026 12:00am GMT
28 Jul 2026
Planet KDE | English
Making KIO copy many files fast
There is a bug in KDE's bug tracker that is almost as old as some of our contributors: bug 342056, "Ridiculously slow file copy (multiple small files)", reported by Alexander Nestorov back in 2014. The report is blunt: copying a 15 GB folder of roughly 3 million small files took 5 to 10 hours in KDE, versus about 20 minutes with rsync. One commenter summed up the mood:
I generally use cp and rsync instead of dolphin for anything more than a few files.
That bug has been stuck in my head for a while, so this post is about finally fixing it. I have been working on KIO's copy path, and I want to walk through where the time was going, some history that explains why, and show numbers across KIO versions including a plain cp for reference.
At with any optimization, let's measure first:

Where a KIO 6.28 copy of 5000 small files spends its blocking time, and there is no single hotspot. Each file blocks in a burst of short syscalls: reading the mount table (/proc/self/mountinfo), opening the source and destination, and round-tripping a command to the worker over an internal socket. The socket round-trips, the send and receive plus the waits for each reply, are the frames highlighted in red, about 15% of the blocking here, spread as thin slivers across both threads because every one of the thousands of files pays them. The frames in green are the real filesystem work the copy cannot avoid: the statx and openat calls, copy_file_range moving the bytes, and the ext4 metadata updates beneath them. That per-file storm, not any single call, is what the rest of this post discusses. (Off-CPU flame graph from sched:sched_switch, weighted by number of blocking switches; click to open the full SVG.)
A little history
KIO is the layer behind almost every file operation in KDE software, from Dolphin's copy and paste to the network transparency that lets you open sftp:// or smb:// URLs as if they were local. Its design goes back to the KDE 2 days, around the year 2000. Back then the answer to "how do I do I/O without freezing the UI" was not a thread but a separate process: a worker (we used to call them kioslaves) is launched for a protocol and talks to the application over a socket. This predates usable threading on Linux (Native POSIX Thread Library only landed in Linux 2.6 in 2003), so processes plus socket IPC was the portable, robust choice, and it still is for network protocols today: if an smb:// worker crashes, your file manager does not go down with it.
The flip side is cost. Every request and its reply are serialized and sent over that socket, with an event-loop hop on each side. For file:// that overhead buys you nothing, because there is no untrusted network on the other end, just the local disk.
In 2022 David Faure changed that: Implement running KIO workers in-process using a thread landed in Frameworks 5.95. Since then the file worker runs on a thread inside the application instead of as a separate process (other protocols stay out-of-process for robustness). That removed process launch and context-switch cost.
No socket between the thread and the app (6.29)
There was still a catch that had been hiding in plain sight: even in-process, the worker thread and the application talked to each other over a socketpair, serializing every command as if they were separate processes. Once the thread was used, that socket was pure overhead.
That's the red highlight in the first flamegraph.
So in-process workers now use a real in-memory transport instead of a loopback socket. A new ThreadConnectionBackend handles commands, and for reads the actual data buffer, straight to the peer thread, with no serialization and no syscall, which makes in-process file reads zero-copy. This is the biggest single jump in the numbers below, and it has landed on master for 6.29 (kio!2279).
Next: batching the copy and the stat (under review)
The changes above make each command cheap. The remaining cost is that there are still so many of them: copying N files is N separate file_copy jobs, each one going through the job scheduler and taking its own round-trip to the worker. For many small files that fixed per-file cost, not the data, is what dominates.
CopyJob can dispatch a whole batch of plain local-to-local files to the worker in one command, and the worker copies them (using copy_file_range, and reflink on filesystems like Btrfs or XFS that support it). Each file still gets its progress signal, its byte accounting, its undo entry, and anything the worker cannot do blindly - an existing destination, an unreadable source, a rename or skip decision - is handed back to the normal per-file path. The gate is conservative on purpose so a hung mount can never freeze the batch (kio!2282).

The same copy on 6.29 with batch-copy: the red socket round-trips are gone. Two things removed them: the in-memory transport from the previous section (no socketpair at all) and batch-copy folding a whole run of files into one command instead of one round-trip each. What is left is real filesystem work: the green frames are the copy itself, copy_file_range moving the bytes, the openat and statx calls, and the ext4 metadata beneath them. The wide plateau that is not green is the benchmark loop deleting each pass's files before the next run (unlink), which is teardown rather than part of the copy.
Before copying, CopyJob stats every source, which is another per-file round-trip. The follow-up batches the stat phase over the same in-process lane. This is the batch-copy-stat column below.
Both of these are under review and targeted at a release after 6.29, so treat their columns in the table as a preview of what is coming rather than something you can install today.
Numbers
Methodology: a 13th-gen Intel Core i7-1365U laptop, everything built RelWithDebInfo without any sanitizer, copying onto a real ext4 volume (so no reflink shortcut, copy_file_range moves real bytes). Each KIO version supplies both its own libKIOCore and its own kio_file worker. Times are the median of 5 runs (3 for the large set) after a discarded warm-up, so caches are warm and equal for every version. cp -r --preserve=mode,timestamps is included as the floor, since that is what the bug reporter reached for instead of Dolphin.
5000 files of 4 KB each (the many-small-files case from the bug):
| Version | Median time |
|---|---|
cp -r (coreutils) |
81 ms |
| KIO 6.28.0 | 1616 ms |
| KIO 6.29-dev (master) | 396 ms |
| KIO 6.29-dev + batch-copy | 88 ms |
| KIO 6.29-dev + batch-copy-stat | 93 ms |
1000 files of 5 MB each (bulk data, where the copy is I/O-bound):
| Version | Median time |
|---|---|
cp -r (coreutils) |
1312 ms |
| KIO 6.28.0 | 1997 ms |
| KIO 6.29-dev (master) | 1687 ms |
| KIO 6.29-dev + batch-copy | 1506 ms |
| KIO 6.29-dev + batch-copy-stat | 1454 ms |
The small-files case is the story. KIO 6.28 was about 20x slower than cp, which is exactly the ratio the 2014 report complained about. Removing the socket for in-process workers, together with no longer probing the destination filesystem once per file, takes it from about 1.6 s to 0.4 s (roughly 4x). Batching the copy takes it to 88 ms, essentially cp speed and about 18x faster than 6.28. That "I use cp instead of dolphin" line finally has an answer.
The large-file case was already well covered before any of this work, and the table shows it: the copy is bound by moving the bytes, so even KIO 6.28 stayed close to cp there, and the per-file optimizations barely move the number (batch-copy lands within about 15% of cp). That is the whole reason this effort targets many small files instead, where the fixed per-file cost, not the data, is what dominates.
batch-copy and batch-copy-stat come out tied here: the benchmark copies a single directory, so its entries arrive in one listing and batch-stat has nothing to batch. It helps the other case, copying a large selection of individual files that would otherwise be one stat round-trip each. Since it removes the round-trip and not the stat call, the win is largest when stats are cheap, not when the disk is slow. Read the two as equal on this test.
And cp will almost certainly stay a little ahead, by design: KIO does more than copy the bytes. It reports per-file progress, can be paused and cancelled, keeps an undo record, preserves permissions and timestamps, resolves conflicts, and tells any open file manager what changed so its view refreshes. That work is not free, and the goal was never to beat cp, only to make the local case fast enough that reaching for cp instead of Dolphin stops being the obvious choice.
Caveats and what is next
These are laptop numbers on one ext4 disk with warm caches, meant to compare versions, not to be absolute. On Btrfs or XFS the batch path reflinks instead of copying, which changes the large-file picture entirely. The batch fast path only engages for plain local-to-local copies on a responsive filesystem; anything else (network, FAT/NTFS, conflicts needing a dialog) falls back to the existing per-file path, unchanged.
Thanks to David Faure for the in-process worker threads that made all of this possible, to Frank Reininghaus for the earlier listing fixes, and to Alexander Nestorov for a bug report that aged well enough to still be worth closing.
That's all, folks.
28 Jul 2026 12:00am GMT
Plasma Vault Advisory: You should probably switch to gocryptfs
Months ago, some distributions accidentally removed cryfs and encfs from Vaults dependencies (temporarily). And some distributions are removing them intentionally from their package repositories (at least, for the time being).
It might be a good idea to switch your vaults to gocrtyptfs.
There is no automatic process for this, just create a new vault (it will be gocryptfs-based - other backends have been removed from the UI in the latest versions) and copy the data from the old one there.
Some context
To avoid users thinking there is something serious going on, this is some background on changes:
- Plasma Vault creation wizard supports only gocryptfs since plasma-vault/-/merge_requests/62 as it is the most maintained upstream project, and to avoid "confusing the users".
- Some distro packagers thought this means Vault no longer supports cryfs and encfs and they removed them from the package dependencies. This change was quickly reverted as there are existing users that already have cryfs and encfs-based Vaults.
- Some distros are cleaning up FUSE2-based file systems and going FUSE3-only. Some of them ship a FUSE3-based CryFS, and some seem to be waiting for an official FUSE3-supporting release (see github.com/cryfs/cryfs/issues/419).
So, nothing important has happened. Your vaults are as safe as they always were.
It is just that it might bring you a headache if the backend you use for your vaults disappeared after you update your system.
And headaches for me when I get bug reports that Vaults no longer support encfs or cryfs :)

28 Jul 2026 12:00am GMT
26 Jul 2026
Planet KDE | English
Week 8: Gradient Widget Merged, Speed Ramp Begins
This is a weekly update from my Google Summer of Code 2026 project with KDE, improving effect widgets in Kdenlive, a free and open source video editor.
Gradient widget merged
MR !911 went through one more round of review, Jean-Baptiste caught a small inconsistency in how the 32-stop limit was applied and fixed it directly (c2d7a3d2, "Use limit everywhere"). After that, the Gradient widget merged. Two of the three widgets from the proposal are now in master.
One known issue flagged during review: MLT's gradientmap filter doesn't currently support alpha in its gradients, that's a bug on MLT's side, not the widget. Jean-Baptiste merged anyway to make the 26.08 window, with a plan to either disable alpha or fix it upstream before the final 26.08.0 release.
Speed Ramp: starting the third widget
With Gradient shipped, moved on to Speed Ramp. My original proposal described free-draggable bezier handles on the remap timeline's connector lines. Investigation before writing any code turned up a real problem with that: MLT has no bezier keyframe type to serialize a time map into, only preset easing types (linear, smooth, cubic, exponential, and more, as suffix characters on keyframe positions).
Checked with Jean-Baptiste. Turns out free bezier handles in MLT had already been investigated a few years ago and found difficult to integrate. His suggestion: use the same keyframe type system Kdenlive already uses for effects like volume and brightness, letting users pick a type from MLT's existing list rather than dragging custom handles.
Finding the right pattern to reuse
Kdenlive already has a widget that draws real keyframe curves in a plain QWidget, KeyframeCurveEditor, used in the effect stack for other parameters. It samples MLT's interpolated value per pixel and draws the result, no QML involved. That became the reference pattern for adding a curve to the remap dialog (RemapView).
Before building on it, tested MLT directly to confirm non-linear keyframe types are actually honored during playback, not just valid syntax. They are, sampled values matched the exact easing formulas. One gotcha found along the way: the keyframe type suffix has to go on the segment's starting keyframe, not the ending one, otherwise it's silently treated as linear.
Implementation
Four commits, each built clean before the next:
- Added per-keyframe type storage (
m_keyframeTypes) alongside the existing keyframe position map, synced across all 30+ places the position map gets mutated - Switched keyframe serialization and parsing to use MLT's own animation API instead of hand-formatted strings, so type suffixes are always placed correctly
- Added a per-pixel sampled curve, drawn additively in the existing dual-ruler layout, nothing existing removed or changed
- Added a keyframe type selector, starting with a curated list (Linear, Smooth, Cubic In, Cubic Out); the full MLT list includes bounce and elastic types, which cause the source time to briefly go backward on a time map, that's a product decision still pending, so it's left out for now
Manually verified: linear playback is unchanged, curve shape follows the selected type, old projects load correctly as all-linear, undo/redo works through type changes, and types survive keyframe drags and clip resizes.


What's next
Speed Ramp branch is local, not yet pushed. Bringing results to Jean-Baptiste before pushing and opening an MR.
26 Jul 2026 9:57pm GMT
Weeks 7 & 8: User Guide, Find Action, and Bug Fixes
With the main proposal items completed, I spent the last 2-3 weeks working on open issues in the KeepSecret tracker, fixing bugs and improving the overall experience.
User Guide (!37)
Added a minimal user handbook for KeepSecret in DocBook format - the standard format used by KDE applications. The guide covers the main features: wallets, managing entries, generating passwords, importing and exporting, and locking. It's accessible via the Help menu. Writing it also involved adding the CC-BY-SA-4.0 license to the repo, which triggered a kirigami-app-components 1.0.1 release (more on that below).
Find Action (!39)
Added the Find Action entry Ctrl+Alt+I to the global drawer. This opens the Actions Explorer dialog - a standard KDE dialog that lets users search through all available actions in the app by name. During testing, I discovered that kirigami-app-components 1.0.0 had a bug where FindAction wasn't working. Marco Martin fixed it and released 1.0.1.
Close entry panel when switching wallets (!41)
Fixed a UX bug in 3-column mode: when switching wallets, the entry panel from the previous wallet stayed open. The fix was a single line - calling App.secretItem.close() when a wallet is clicked in the sidebar.
Delete key shortcut (!43)
Added the Delete key as the default keyboard shortcut for deleting secrets. Since there's already a confirmation dialog, binding Delete directly is safe.
26 Jul 2026 3:04pm GMT
25 Jul 2026
Planet KDE | English
My GSoC Journey: Hacking on KDE's Network Manager
If anybody had told me I'd end up working on the very Linux desktop environment I've been daily-driving for the past three years, I probably wouldn't have believed them.
This summer, I got to learn and work on the main Network Manager component used by default in KDE, the desktop environment relied on by millions of users worldwide (source). Looking back, this has been the most challenging, and by far the most rewarding, journey of my open-source career so far.
How It All Started
I started looking for open-source projects to contribute to way before GSoC even announced its list of participating organizations. Back in October, I began contributing to major projects like OpenTelemetry, Lima-VM, and WasmEdge, repos I'm still active in today.
Somewhere along the way, I decided to explore the KDE ecosystem and give it a shot. That decision changed the trajectory of my year. From that point on, my co-mentors and I were actively working through a number of open-source issues together, including bugs in KClock, the native clock application used across KDE, long before the official GSoC coding period even began. That early groundwork ended up being exactly what prepared me to take on Network Manager as my actual project.
The Project
My GSoC project is titled "Make network related KCMs feature complete with desktop equivalent," under Plasma Mobile, mentored by Carl Schwan and the rest of the Plasma Mobile team.
Here's the core problem: Plasma Desktop and Plasma Mobile each ship their own, completely separate networking settings modules. The desktop KCM (kcm_connections) is mature and feature-complete, with full Wi-Fi security support (WPA/WPA2/WPA3, 802.1x Enterprise, various EAP methods), VPN configuration, and more. Plasma Mobile's networking KCMs, on the other hand, are QML/Kirigami-based and touch-friendly, but only support the basics (WPA/WPA2 Personal, essentially). Because the desktop editor lives in libs/editor/ as Qt Widgets, it can't be dropped into the mobile UI as-is, Widgets and Kirigami don't mix, so mobile has ended up stuck maintaining its own thinner reimplementation instead of reusing the desktop's mature backend logic.
My project is to close that gap: pull the shared backend logic in libs/ out from underneath the Qt Widgets layer, rebuild the connection editor in QML (in a new libs/editorqml/) using Kirigami, and get both the desktop and mobile KCMs consuming the same backend through QML property/signal bindings. This way, a feature added once (say, WPA3 Enterprise or a new VPN protocol) works identically on both form factors instead of being implemented twice. The work is broken into phases: project setup, the Wi-Fi/security connection-editor foundation, additional connection types (wired, hotspot, VPN, bonds/bridges/teams/VLANs), refactoring the KDED popup dialogs (like the Wi-Fi password and PIN prompts) from Widgets to QML, and finally integration testing plus writing proper architecture documentation for plasma-nm, which currently has very little of either.
The Challenge
The biggest hurdle, by far, was getting a real grip on QML and the architecture of the broader codebase.
Coming in, I understood C++ reasonably well, but plasma-nm's UI layer is written almost entirely in QML, a declarative language that describes what the interface should look like rather than how to build it step by step. On top of that, plasma-nm isn't a single self-contained app, it's a plugin-based system that sits on top of NetworkManager (the system daemon), talks to it over D-Bus, and exposes that state through a KDED module and a Plasmoid applet that the QML frontend binds to. Understanding which layer owned a given piece of logic, the daemon, the backend plugin, or the QML view, took real time.
Some of the specific things I had to work through:
- Signal/property bindings in QML: tracing how a change in connection state on the backend actually propagates up through C++ signals into a QML property binding, and where things could silently break if a binding wasn't wired correctly.
- The plugin architecture: plasma-nm supports different connection types (Wi-Fi, VPN, mobile broadband, etc.) via separate plugins, each with its own QML + C++ pairing, so I had to learn to navigate a fairly large, distributed codebase rather than one monolithic file.
Key Contributions
Here is the list of MRs that are merged in upstream as of this date:
What I Learned
Beyond the technical skills, QML, Network Manager core concepts, and plugin architectures, this project taught me a lot about contributing to a codebase that real people depend on every day. KDE isn't a toy project, it's a software that is used by millions of people to connect Wi-Fi and manage their networks without thinking twice about it. That changes how carefully you write and review code.
Thanks
A huge thank you to my mentors, Devin Lin and Carl Schwan, for the patience and guidance through the pre-GSoC Phase. And thanks to the broader KDE community and Plasma Mobile for being as welcoming as it is to newcomers navigating a genuinely large codebase for the first time.
25 Jul 2026 3:46pm GMT
This Week in Plasma: Auto-Lock and Unlock for Remote Desktop Sessions
Welcome to a new issue of This Week in Plasma!
This week saw a bunch of work on some core infrastructure components, like the RDP server, login greeter, and screen configuration tooling. That's in addition to lots of other good work, too:
Notable new features
Plasma 6.8
You can now configure Plasma's built-in remote desktop server to automatically lock the session after the last connected RDP client disconnects. (Nick Haghiri, krdp MR #211)

Plasma Login Manager now remembers the last-used session for each user. (Jin Liu and Oliver Beard, plasma-login-manager MR #176 and libplasma MR #1557)
Notable UI improvements
Plasma 6.8
Discover's transaction progress view now shows items in groups, with the ones currently in progress in a group at the top. (Aleix Pol Gonzalez, discover MR #1219)

On multi-screen setups, the existing Meta + 1-9 shortcuts for jumping straight to a task now target the panel on the screen you're actively using, rather than always going to the primary monitor's panel. This matches the behavior added to last week's new task-switching shortcuts. (Salman Farooq, plasma-desktop MR #3884 and plasma-workspace MR #6848)
You can now find languages in Plasma Setup by searching for their locale code, localized name, or English name. (Tiziano Gaia, plasma-setup MR #109)
Frameworks 6.29
Further improved the visual fidelity of small icons drawn with the Kirigami.Icon component. (Méven Car, kirigami MR #2127)
Notable bug fixes
Plasma 6.6.7
Fixed an issue that made KWin crash on login for newer NVIDIA GPUs using the latest NVIDIA drivers in conjunction with various color management features. (Xaver Hugl, KDE Bugzilla #523287)
Restored the ability to play full-screen video in Chromium-based browsers on a virtual screen, such as those used when screen recording. (Xaver Hugl, Bugzilla #523353)
Fixed an issue that could make Plasma freeze and then take down apps as well after you switched activities with unusual values in your Plasma config file. (Shouvik Kar, KDE Bugzilla #522039)
Fixed two visual glitches affecting the Digital Clock widget: one that made the layout overflow on a panel right after turning on the "always show seconds" setting, and another one that made the time zone label fail to use the systemwide font family. (Hunter White and Nate Graham, KDE Bugzilla #523010 and KDE Bugzilla #523164)
When an image used in a slideshow in the Media Frame widget is changed on disk, the widget now notices it properly, rather than replacing it with a blank frame. (David Wild, KDE Bugzila #521538)
Plasma 6.7.4
Fixed a weird bug that could break Plasma Login Manager after you unplugged a screen and plugged it back in while on the login screen. (Oliver Beard, KDE Bugzilla #523313)
Fixed a bug that could make KWin crash on login on various laptops. (Xaver Hugl, kwin MR #9632)
Fixed a case where System Settings could crash when Fanatec racing pedals were plugged in. (Sebastian Sauer, KDE Bugzilla #522886)
Restored the ability to change the wallpaper and apply Plasma settings to Plasma Login Manager for users who upgraded from Plasma 6.6. (David Edmundson, KDE Bugzilla #517081)
Frameworks 6.29
Fixed a surprisingly common yet random-seeming way that Plasma could crash. (Shouvik Kar, KDE Bugzilla #519614)
QML-based KDE apps once again remember whether they were maximized or not across launches. (Nate Graham, KDE Bugzilla #522205)
Worked around a Qt bug that made some keyboard shortcuts in Kirigami-based apps not get assigned when using the app in certain languages other than English. (Manuel Alcaraz Zambrano, kirigami MR #2124)
Icons drawn by the Kirigami.Icon component now use the correct aspect ratio for portrait-orientation images when they're being rounded to standard icon sizes. (Méven Car, kirigami MR #2126)
Notable in performance & technical
Plasma 6.8
We have created a new kscreenctl tool, intended as a future replacement for the old kscreen-doctor tool. It includes more features, more robustness, and a more conventional usage method. (Vlad Zahorodnii, kscreen MR #487)

Discover is now faster to load icons for Flatpak apps. (Aleix Pol Gonzalez, discover MR #1366)
How you can help
KDE has become important in the world, and your time and contributions have helped us get there. As we grow, we need your support to keep KDE sustainable.
Would you like to help put together this weekly report? Introduce yourself in the Matrix room and join the team!
Beyond that, you can help KDE by directly getting involved in any other projects. Donating time is actually more impactful than donating money. Each contributor makes a huge difference in KDE - you are not a number or a cog in a machine! You don't have to be a programmer, either; many other opportunities exist.
You can also help out by making a donation! This helps cover operational costs, salaries, travel expenses for contributors, and in general just keeps KDE bringing Free Software to the world.
To get a new Plasma feature or a bug fix mentioned here
Push a commit to the relevant merge request on invent.kde.org.
25 Jul 2026 12:00am GMT
24 Jul 2026
Planet KDE | English
Creating a player bot to automate Mankala
Hello everyone! Once again, I am here to share my fun experiences incorporating new features for Mankala.
Problem
This time I have built a bot server for Mankala where you can automate the entire game process of playing the game moves by using the server endpoints present in the bot. This Mankala bot can be run in various ways, and for the easiest to understand, can be an example in Python, which I have used in our process.
Approach
To build this bot, I built a minimal HTTP server using Qt's own QTcpServer. The BotApiServer class listens on port 8080 and handles raw HTTP requests by parsing the method and path manually, and when these requests are synced from the terminal, the changes can be observed in the GUI, showing a change in the number of shells.
The API exposes two endpoints:
GET /api/status- Returns the full game state as JSON: whose turn it is, the seeds in every pit, each player's store, whether the game is over, and who won.POST /api/move- Accepts a JSON body with player ("player1" or "player2") and pit_index (0-indexed), validates the move, executes it, and returns the updated state.
A list of documentation with all the endpoints present has also been added as part of the Help section present in the game, which also contains predefined scripts to run 1 bot or even 2 bots simultaneously, automating the entire game.
OpenAPI documentation:
openapi: 3.1.0
info:
title: Mankala Bot API
description: API to programmatically control and play Mankala.
version: 1.0.0
paths:
/api/status:
get:
summary: Get the current game status
description: Retrieves the full state of the board, scores, and turn information.
responses:
"200":
description: OK
content:
application/json:
schema:
type: object
required: [in_progress, game_over, winner, turn, variant, pit_count, player1_pits, player2_pits, player1_store, player2_store, board]
properties:
in_progress: { type: boolean }
game_over: { type: boolean }
winner: { type: string, enum: ["", "player1", "player2"] }
turn: { type: string, enum: ["player1", "player2"] }
variant: { type: string, enum: ["Bohnenspiel", "Oware", "Pallanguli"] }
pit_count: { type: integer, minimum: 1 }
player1_pits: { type: array, items: { type: integer, minimum: 0 } }
player2_pits: { type: array, items: { type: integer, minimum: 0 } }
player1_store: { type: integer, minimum: 0 }
player2_store: { type: integer, minimum: 0 }
board: { type: array, items: { type: integer, minimum: 0 } }
/api/move:
post:
summary: Make a move
description: Executes a move for the specified player at the given pit index.
requestBody:
required: true
content:
application/json:
schema:
type: object
required: [player, pit_index]
properties:
player: { type: string, enum: ["player1", "player2"] }
pit_index: { type: integer, minimum: 0 }
responses:
"200":
description: OK
content:
application/json:
schema:
type: object
required: [status, turn, game_over]
properties:
status: { type: string, enum: ["ok"] }
turn: { type: string, enum: ["player1", "player2"] }
game_over: { type: boolean }
winner: { type: string, enum: ["", "player1", "player2"] }
"400":
description: Bad Request (Invalid Move, Not Your Turn, Invalid JSON)
content:
application/json:
schema:
type: object
properties:
error: { type: string }
Here we can observe a Python script for a player vs bot game:
import urllib.request, json, time
API = "http://localhost:8080/api"
def status():
return json.loads(urllib.request.urlopen(f"{API}/status").read())
def move(player, pit):
req = urllib.request.Request(f"{API}/move",
data=json.dumps({"player": player, "pit_index": pit}).encode(), method="POST")
req.add_header("Content-Type", "application/json")
return json.loads(urllib.request.urlopen(req).read())
# Bot plays as player2, waits for human player1
while True:
st = status()
if st["game_over"] or not st["in_progress"]:
print(f"Game Over! Winner: {st['winner']}")
break
if st["turn"] != "player2":
time.sleep(0.5) # wait for human
continue
pits = st["player2_pits"]
# pick first non-empty pit
pit = next((i for i, v in enumerate(pits) if v > 0), -1)
if pit == -1:
break
print(f"Bot moves pit {pit}")
move("player2", pit)
time.sleep(1.5) # animation delay
For the above code, we can adjust the localhost port and the animation speed based on our needs and save it.
Challenges I faced:
I would say the synchronization of the GUI with the server was hard. So to make the GUI animations correctly incorporated, I made the apiMoveMade signal using which the change in game state was listened in GameWindowLandscape.qml and GameWindowPortrait.qml files. This was something really new that I have done till now and was a fun experience for me.
Thanks for reading 🚀....
24 Jul 2026 1:59pm GMT
Web Review, Week 2026-30
Let's go for my web review for the week 2026-30.
Online Friends Are Real Friends
Tags: tech, internet, culture, life, friendship
Indeed, friends we make online are no less real than the ones we see in the flesh first. I would know… guess how I made friends with KDE people?
https://blog.absurdpirate.com/online-friends-are-real-friends/
Europe's digital sovereignty needs challenges
Tags: tech, europe, politics, foss, commons
Excellent piece. I'm feeling unease at this widespread confusion between european ownership and digital freedom. What we collectively need is the latter. There's no sovereignty to be had in a proprietary ecosystem, be it owned by an European company or not.
https://hamishcampbell.com/europes-digital-sovereignty-needs-challenges/
Mullvad and Daniel Berntsson's Failed Cleanup
Tags: tech, ethics, politics, vpn
No the technology we use isn't neutral… In this case it directly funds fascists. Whatever the technical merits from the Mullvad VPN, such ties disqualify them to be used.
https://markwrites.io/mullvad-and-daniel-berntssons-failed-cleanup/
Leiden Declaration on Artificial Intelligence and Mathematics
Tags: tech, mathematics, science, research, ai, machine-learning, gpt
This is a very good declaration and call to actions from the mathematics field. I wish we'd have something well thought out like this for computer science and software engineering as well.
AI advice suppresses people's willingness to say "I don't know"
Tags: tech, ai, machine-learning, gpt, linguistics, cognition, bias
Interesting study which measures our propensity to be more confident while being more wrong when using LLMs to answer questions. Those models really tap into our cognitive bias to mistake linguistic fluency for competence.
https://osf.io/preprints/psyarxiv/5y6m4_v1
Not enough water for UK's datacentre plans, trade body says
Tags: tech, ai, machine-learning, gpt, water, ecology, politics
If you still don't think data centres have a water consumption problem, especially since the LLM weapon race… Think again.
The Week of Sandbox Escapes
Tags: tech, ai, machine-learning, gpt, copilot, security
In other words: the security boundaries of coding agents are very porous and not where you expect. Handle with extreme care until they have a proper security model.
https://www.pillar.security/blog/the-week-of-sandbox-escapes
email encryption
Tags: tech, email, cryptography, history
Wondering about the landscape of email encryption? This gives a good historical tour.
https://computer.rip/2026-07-19-email-encryption.html
Minimal Git CI using hooks
Tags: tech, git, tools, ci, complexity
Little reminder that a got forge doesn't and shouldn't need much. Sprinkle gitolite if you need to manage rights, maybe gitweb and then you're all set.
https://mccd.space/posts/26-06-29/simple-git-ci
The startup's Postgres survival guide
Tags: tech, databases, postgresql
Quite a few nice Postgres tips. The first ones are rather basics the less common tips are toward the end. Could have a few more details at times, but that's a good starting point.
https://hatchet.run/blog/postgres-survival-guide
When 'if' slows you down, avoid it
Tags: tech, programming, performance
This is too often forgotten. If you can avoid the "if" and your CPU will thank you for it.
https://easylang.online/blog/branchless
Everyone Should Know SIMD
Tags: tech, simd, cpu, performance, zig
Nice post on how to approach problems suitable for SIMD.
https://mitchellh.com/writing/everyone-should-know-simd
Static search trees: 40x faster than binary search
Tags: tech, cpu, simd, performance, optimisation
Excellent piece diving deep into the opportunities to optimise an algorithm. The final speed up is impressive.
https://curiouscoding.nl/posts/static-search-tree/
Rust service hardening and production checklist
Tags: tech, rust, containers, security
Good checklist to reduce your attack surface as much as possible when deploying your service.
https://kerkour.com/rust-service-hardening-and-production-checklist
Hardening Rust Code For Production
Tags: tech, rust, containers, security
More ideas of things to check to harden a service, goes beyond just what's deployed. Many good points on how to handle errors and such.
https://corrode.dev/blog/hardening-rust/
The PImpl idiom and the C++26 std::indirect type
Tags: tech, c++, memory
Looks like a nice improvement over std::unique_ptr for managing pimpl indeed. Really interesting stuff coming in C++26.
https://mariusbancila.ro/blog/2026/07/23/the-pimpl-idiom-and-the-cpp26-stdindirect-type/
Software rendering in 500 lines of bare C++
Tags: tech, graphics, 3d, shader
Wondering how the graphics pipeline works for 3D rendering? This is a nice lecture on how to implement a purely software one. If gives a good idea of what needs to happen.
Prefactoring: Clear the Way for Your New Feature
Tags: tech, refactoring
Short and to the point to illustrate the use of refactoring at the beginning of the work on a feature.
https://testing.googleblog.com/2026/07/prefactoring-clear-way-for-your-new.html
The Value of Domain Knowledge in Software
Tags: tech, knowledge, craftsmanship
This is too often forgotten by developers. Our job isn't only about the technical side of things, we must also understand the domain the users are working in. It's a part of the craft.
https://www.gustavwengel.dk/value-of-domain-knowledge
The Most Ridiculous War Humans Ever Fought
Tags: history, funny
OK, didn't know about this one. It was indeed ridiculous… we're really a weird species.
https://www.youtube.com/watch?v=Qv5qQu0yMaU
The Deadliest Thing in Your Kitchen
Tags: biology, science, funny
You won't look at your kitchen the same way after this.
https://www.youtube.com/watch?v=2cK8l5Yg5w8
Bye for now!
24 Jul 2026 11:38am GMT