31 Jul 2026
 Planet Mozilla
Planet Mozilla
The Servo Blog: June in Servo: real world compat, media queries, SharedWorker, and more!
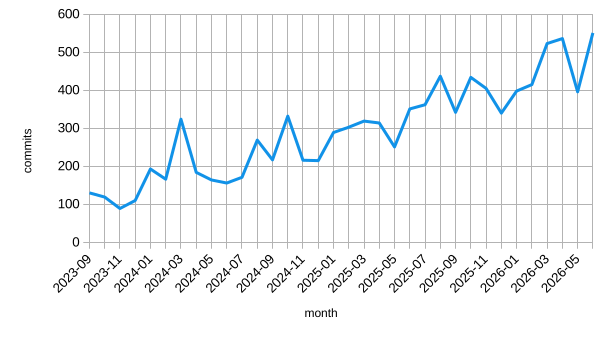
Servo 0.4.0 contains all of the changes we landed in June, which came out to yet another record 558 commits (April: 534, May: 391). For security fixes, see § Security.
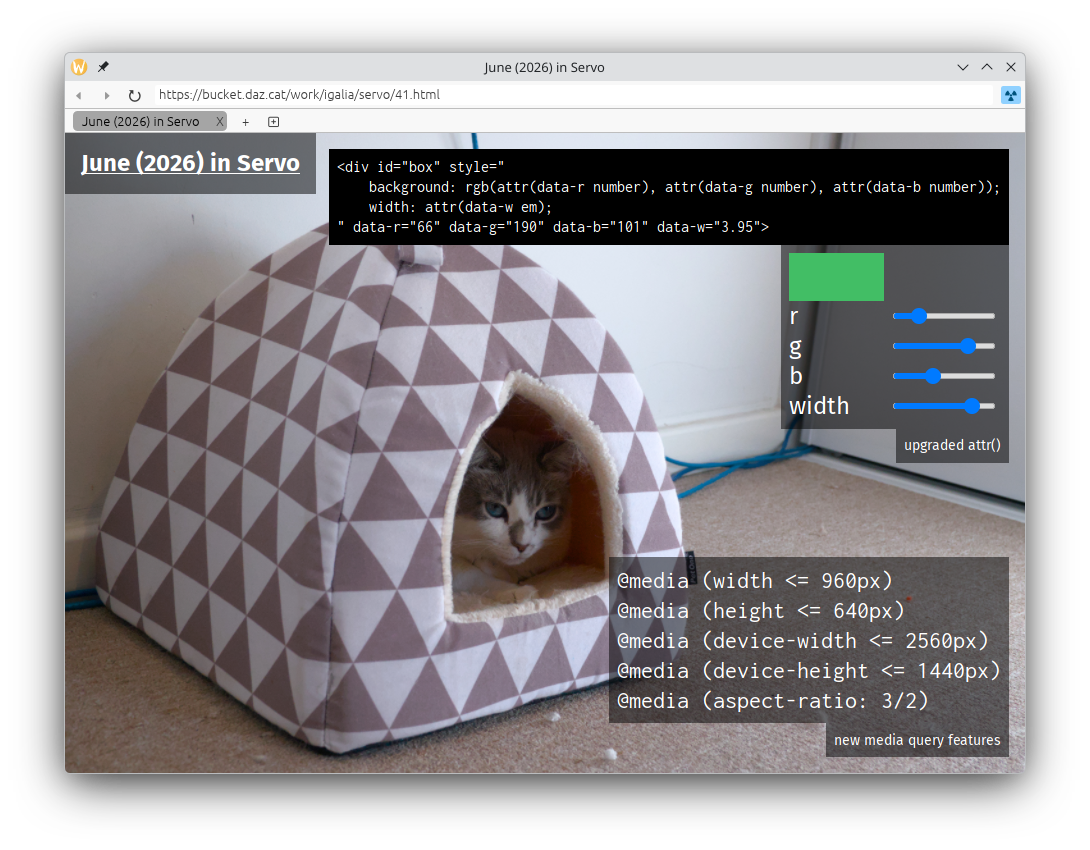
We've shipped several new web platform features:
- 'attr()', in experimental mode (@Loirooriol, #45041)
- 'image(<color>)', 'closest-corner', and 'farthest-corner' in 'ellipse()' and 'circle()' (@Loirooriol, #45421)
- 'calc()' and other mathematical expressions can now be resolved later than parse time, e.g.
sign(1em - 32px)(@Loirooriol, #45421) - 'font-feature-settings' in '@font-face' (@simonwuelker, #45393)
- '@media (device-width)', '@media (device-height)', '@media (height)', '@media (aspect-ratio)', and their min- and max- variants (@jdm, @mrobinson, @nicoburns, @jschwe, #44978, #45707, #45490)
- '@media (orientation)' (@nicoburns, #45707)
- '@media (pointer)' and '@media (any-pointer)' (@nicoburns, #45681)
- '@media (hover)' and '@media (any-hover)' (@nicoburns, #45681)
Plus a bunch of new DOM APIs:
- SharedWorker (@Taym95, #45786)
- console.dir() (@Taym95, #45109)
- customElementRegistry on Document and ShadowRoot (@shubhamg13, #45872)
- initialize() on CustomElementRegistry (@shubhamg13, @yezhizhen, #45903)
- new CustomElementRegistry() (@shubhamg13, #45791, #45550)
- textStream() on Request, Response, and Blob (@yezhizhen, #45864, #45861)
- setPointerCapture(), releasePointerCapture(), hasPointerCapture() on Element (@webbeef, #45048)
- ontouchstart, ontouchend, ontouchmove, ontouchcancel on Element (@stevennovaryo, #45049)
- crypto.subtle.digest() for KT128 and KT256 (@kkoyung, #45699)
- crypto.subtle.getPublicKey() for ML-KEM and ML-DSA (@kkoyung, #45252)
This is another big update, so here's an outline:
You can help!
Servo is steadily becoming a bigger and busier project every month, and by June 2026, we've been reading through over four times the commits as we did when we started in September 2023.
This is hard work, particularly since there are things we need to know that are often difficult to answer just by reading the changes:
-
Who does the change affect, if anyone? Does it affect users, Servo developers, embedders, or some other group?
-
What observable difference does the change make, if any?
-
Does the feature require any preferences to be enabled, or is it enabled for everyone by default?
-
Are any real-world websites affected by the change?
-
What issue or broader project is the change related to? This question is answered by
Fixes: #xxxxxorPart of: #xxxxxin the PR description.
Thanks to an initiative by @jdm, it's now easier than ever for you to help us answer those questions, using the Servo Highfive bot! If you're working on a pull request that you think might be interesting for the next monthly update, even if you're not 100% sure, tell us about it by following the steps below:
-
You add the monthly update label to your pull request, or comment
@servo-highfive monthly update -
Highfive posts a comment asking you some questions
-
You answer those questions in a comment containing
@servo-highfive monthly update answer
Security
Servo's JS runtime, SpiderMonkey 140.10.1, had several security bugs that have been fixed in Servo 0.4.0 with the update to SpiderMonkey 140.11.0 (@jschwe, #45584). For more details, see CVE-2026-8388, CVE-2026-8391, CVE-2026-8974, CVE-2026-8975, and MFSA 2026-48.
Several more security bugs in Servo's JS runtime have been fixed in Servo 0.4.0 with the update to SpiderMonkey 140.12.0 (@jschwe, #45766). The exact CVEs that apply to us are not yet known, but for more details, see MFSA 2026-58.
RSA operations in SubtleCrypto now do modular exponentiation in constant time (@kkoyung, #45631). Please note that our RSA implementation is currently vulnerable to the Marvin Attack - for more details, see RUSTSEC-2023-0071.
ML-DSA operations in SubtleCrypto now do the Decompose step in constant time, fixing RUSTSEC-2025-0144 (@kkoyung, #45294).
We've fixed an HTML injection bug (XSS) in file:/// directory listings, which affected file names containing </script> (@sahvx655-wq, #45510).
Real world compat
Layout correctness has significantly improved on lichess.org, and many websites have become a lot more readable thanks to our improved handling of variable fonts (@simonwuelker, #45768), including Zulip (servo.zulipchat.com) and Speedtest (speedtest.net).
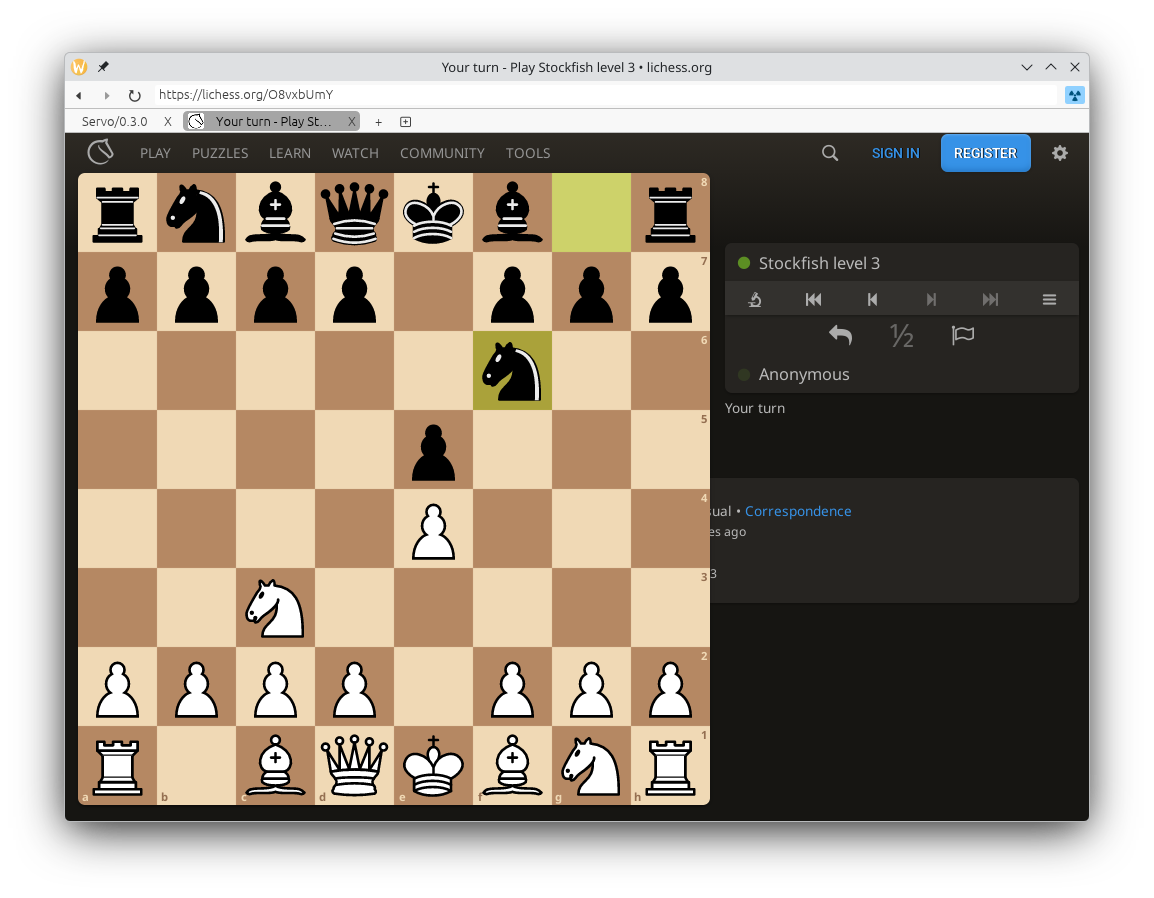
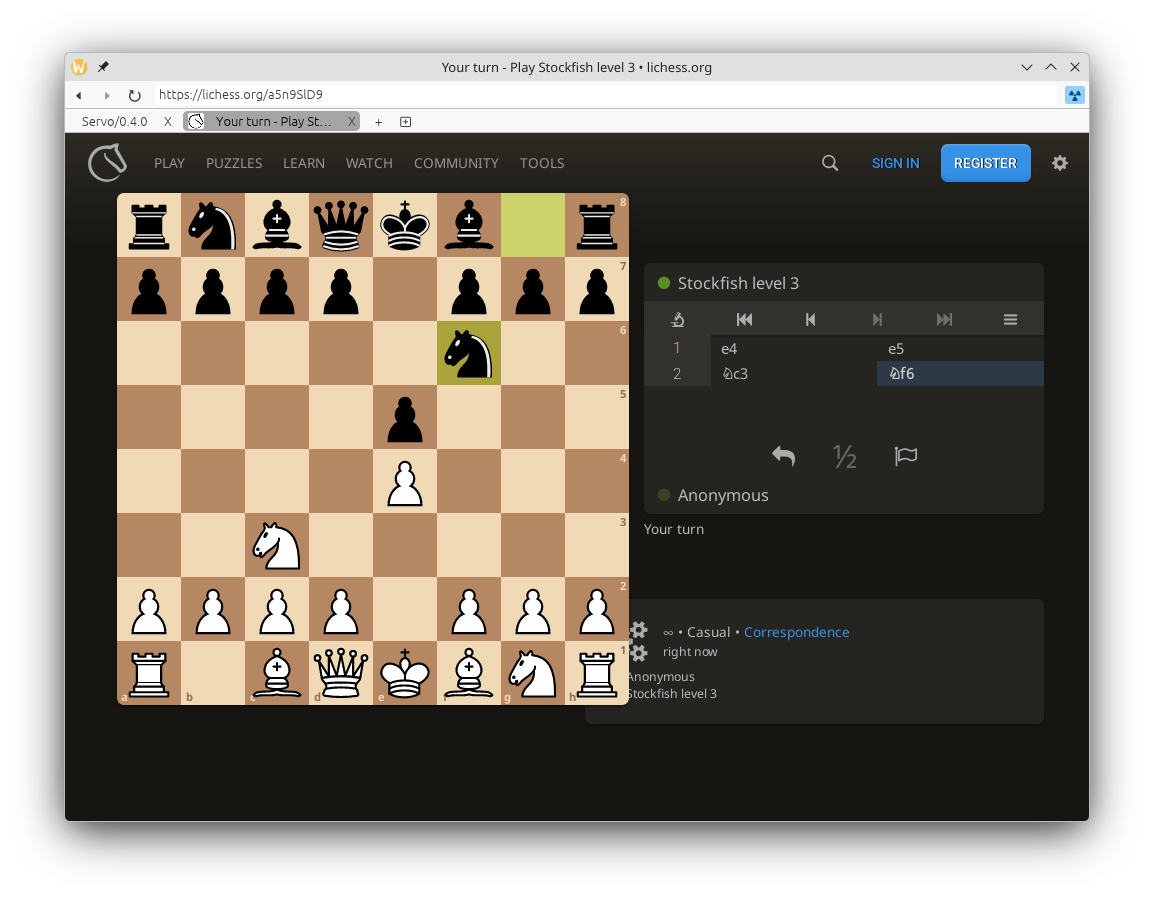
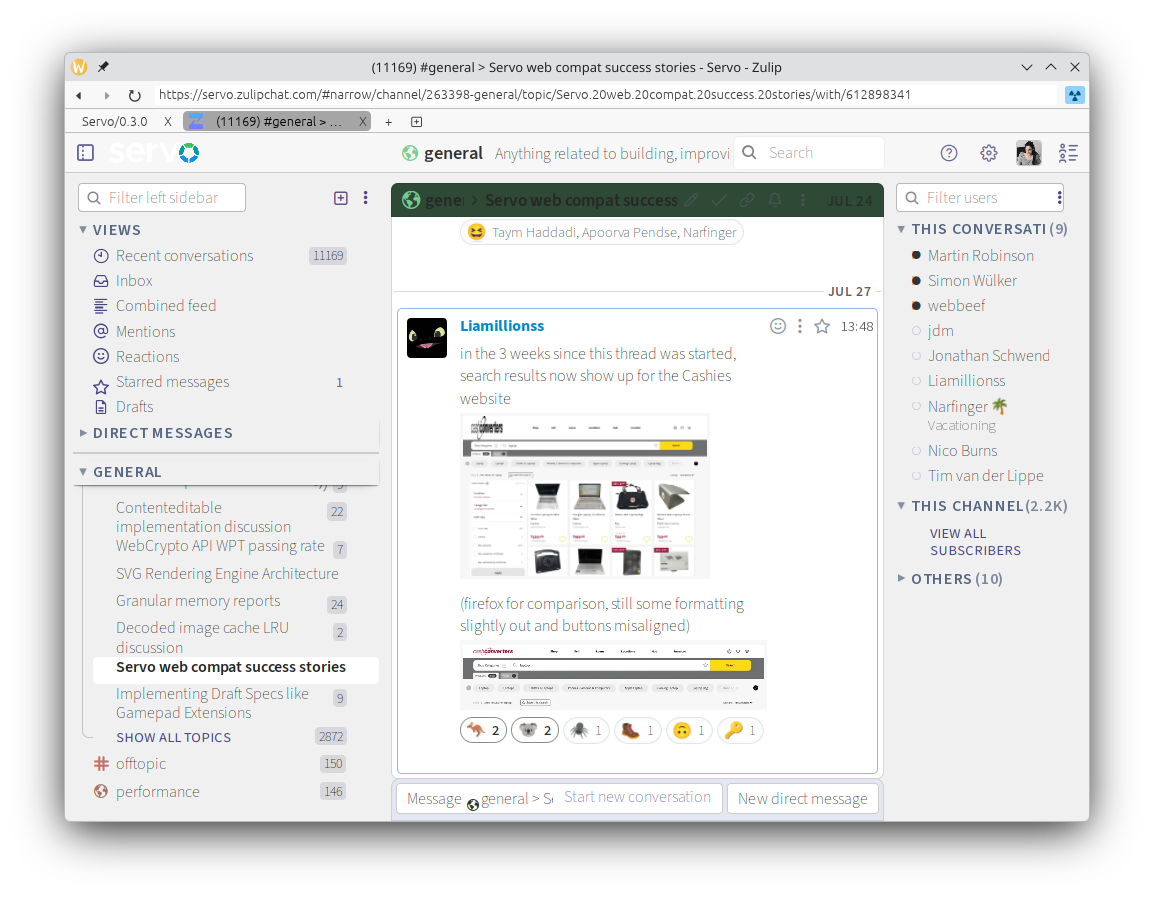
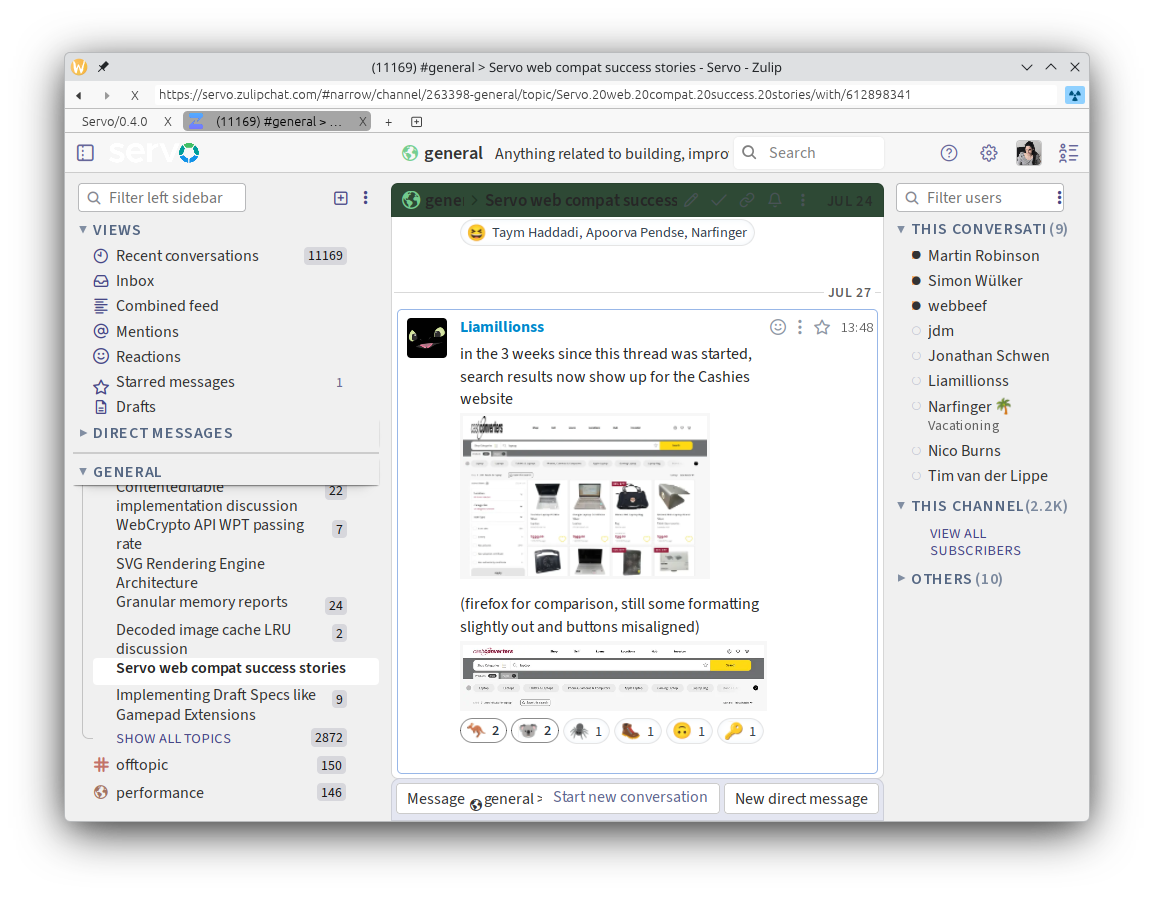
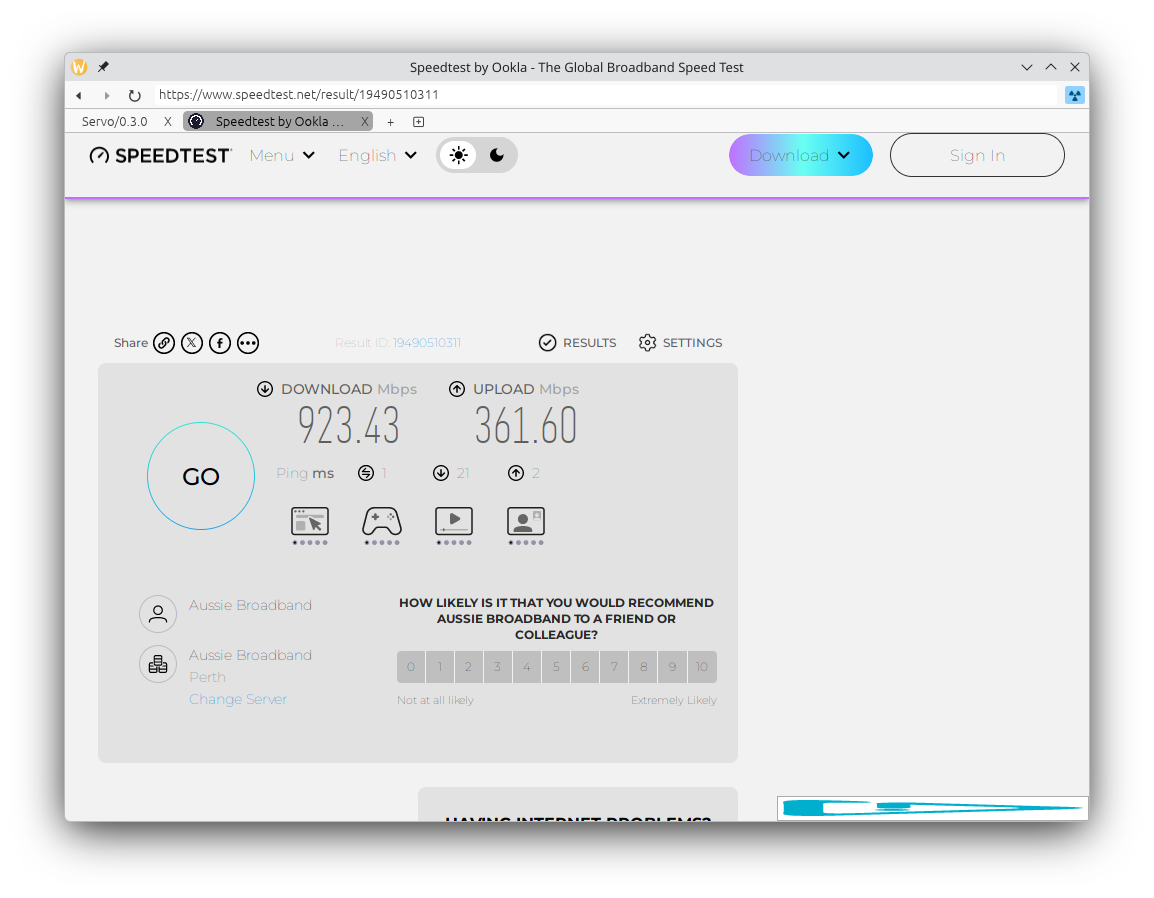
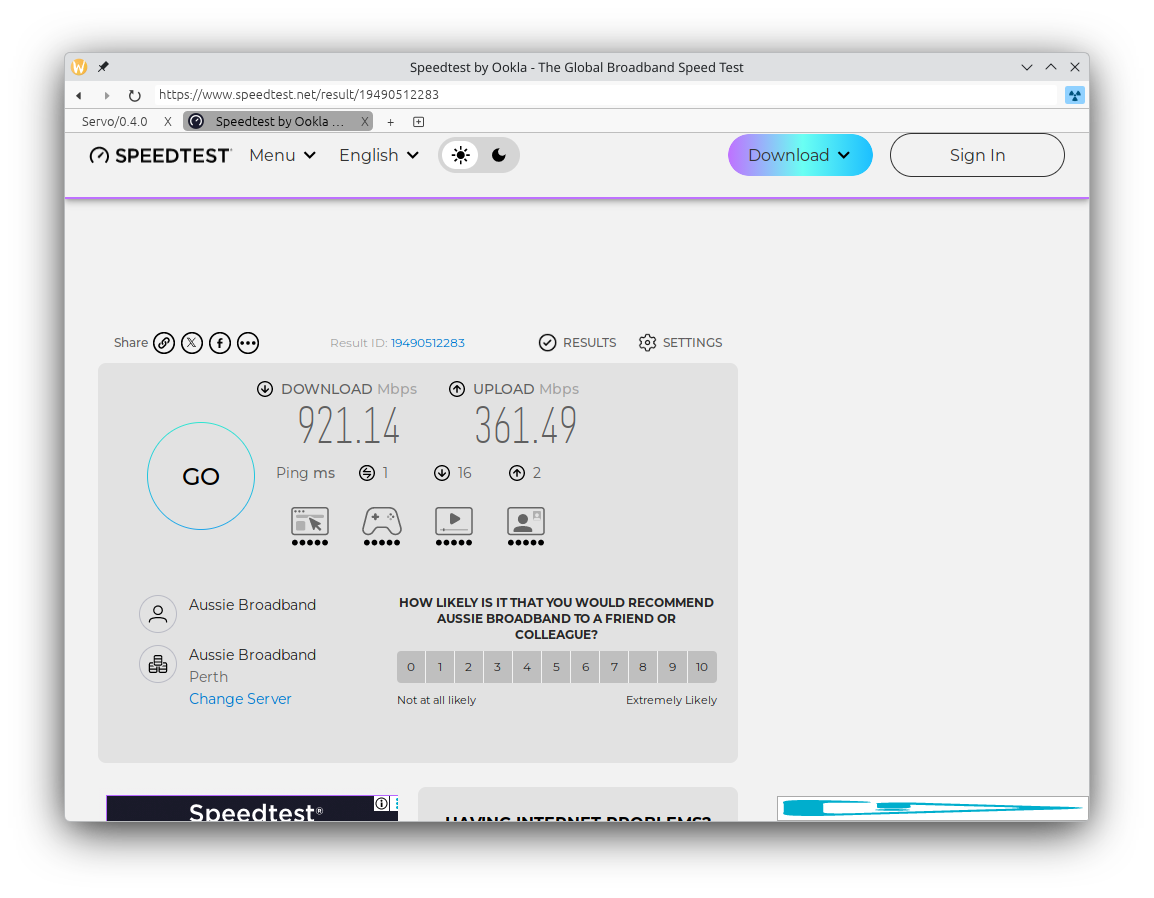
Many websites worked in Servo even before version 0.4.0, including Google Photos (photos.google.com) and Cash Converters (cashconverters.com.au), and continue to work in version 0.4.0. Other websites, like Google Maps (maps.google.com) and OpenStreetMap (www.openstreetmap.org), render well but have some issues with interactivity.
We're interested to hear how well your favourite websites run in Servo! Report successes in this Zulip thread, and failures in our GitHub issues.
Work in progress
We're implementing the more powerful version of 'attr()' that can be used anywhere, not just in 'content', under --pref layout_css_attr_enabled (@Loirooriol, #45041, #45421, #45495, #45752).
WebGPU support has improved, under --pref dom_webgpu_enabled:
- implemented copyExternalImageToTexture() on GPUQueue (@sagudev, #45646)
- implemented createQuerySet() on GPUDevice and resolveQuerySet() on GPUCommandEncoder (@sagudev, #45644)
- implemented pushDebugGroup(), popDebugGroup(), and insertDebugMarker() on GPUCommandEncoder, GPUComputePassEncoder, and GPURenderPassEncoder (@jschwe, #45489)
- more conformant GPUTexture (@sagudev, #45300)
- more conformant requestAdapter() on GPU (@sagudev, #45424)
- more conformant secure context enforcement (@sagudev, #45279)
All of the features above are enabled in servoshell's experimental mode.
We've made more progress towards accessibility support, under --pref accessibility_enabled (@alice, @delan, #45555, #45554, #44949).
We've started implementing visible and interactive text selection (@mrobinson, @SimonSapin, #46107), one of the most long-awaited features of any web browser. Stay tuned!
We've also started working on Web Animations, under --pref dom_web_animations_enabled (@simonwuelker, #45522, #45983), as well as webkitRelativePath on File, under --pref dom_entries_api_enabled (@yezhizhen, #45666).
Rust doesn't have a stable ABI, so it has generally not been possible to embed Servo in another application without building Servo from source. To make it possible, we've started designing a wrapper C API that will let you consume Servo as a prebuilt shared library using the stable and ubiquitous C ABI (@mukilan, #44984). Eventually the idea is that we'll create a wrapper Rust API around that wrapper C API, so you can have both the ergonomics of Rust and the build simplicity of C.
Embedding API
New in the Servo API:
Breaking changes:
WebView::send_errorhas been removed (@mukilan, #45502) - this method was always meant to be internal, and has become unused after we introduced the new WebView- and WebViewDelegate-based API
We've improved the docs for WebView, WebViewDelegate, JSValue, AlertDialog, AllowOrDenyRequest, AuthenticationResponse, BluetoothDeviceDescription, ConfirmDialog, ConsoleLogLevel, CreateNewWebViewRequest, EmbedderControl, EmbedderControlResponse, FilePicker, Image, JavaScriptErrorInfo, NavigationRequest, PermissionRequest, PixelFormat, PromptDialog, ProtocolHandlerRegistration, ProtocolHandlerUpdateRegistration, Scroll, SelectElement, SelectElementRequest, and WebViewVector (@mukilan, #45282, #45467).
For users and developers
In servoshell:
-
the Android version now requires Android 13+ (@jschwe, #46104)
-
the desktop version now lets you drag and drop files to open them (@simonwuelker, #45454)
-
the desktop version now lets the tab bar scroll horizontally if you have too many tabs open, but from one tab hoarder to another, maybe you should reconsider having so many tabs open (@Nylme, #44884)
-
the desktop version enters fullscreen on the monitor containing the window, even if you've moved it to a different monitor (@rhit-kapilaar, #45556)
-
the desktop UI is more performant, resizes more smoothly, and no longer gets stuck in hovered states (@mrobinson, #45289, #45456, #45290)
-
<select multiple> should now be interactable on all desktop platforms (@alexcat3, #45419)
-
localhost:<port>now implieshttp://in the location bar and on the command line, rather than treatinglocalhost:as an unsupported URL scheme (@SteveSharonSam, #45729, #45832)
When using the Firefox DevTools:
-
in the Console tab, uncaught exceptions are reported correctly (@jdm, #45549)
-
in the Console and Debugger tabs, you can now inspect the elements of nested arrays and the entries of Map objects (@atbrakhi, #45435, #45514, #45767)
-
in the Debugger tab, the Scopes panel now shows any '(uninitialized)' variables, the value of
this, and the global scope (@atbrakhi, @eerii, #45824, #45517)
We've fixed some build issues on riscv32, riscv64, and arm64 (@fxzjshm, @saschanaz, #45285, #45731), and modernised servoshell for Android to use Compose UI and Kotlin (@veyndan, #45923, #45932, #45941, #45982, #45985, #46015, #46035, #46037, #46046, #46053, #46061, #46071, #45641, #45643, #45650, #45665, #45671, #45676, #45679, #45683, #45712, #45713, #45734, #45738).
For developers of Servo itself:
-
mach try --helpnow lists all of the kinds of try jobs you can run (@shubhamg13, #45607) -
mach test-wpt --update-expectationslets you run Web Platform Tests and update expectations in a single command (@TimvdLippe, #45521), rather than having to runmach test-wpt --log-raw <path>followed bymach update-wpt <path>
More on the web platform
To allow for more performant scrolling, 'wheel' events are no longer .cancelable unless there are one or more non-passive event listeners (@kunalmohan, #45667). Note that like in Firefox, 'wheel' events are passive by default.
'dotted', 'dashed', and 'wavy' text decorations are now continuous across element boundaries (@mrobinson, #45726).
We've improved the conformance of <dialog> (@skyz1, @mrobinson, #45825, #45761), <iframe sandbox> (@cychronex-labs, #45880), <input minlength> and <input maxlength> (@skyz1, #45705), CSS gradients (@mrobinson, #43945), 'font-style' and 'unicode-range' in '@font-face' (@Loirooriol, #45821), FontFaceSet (@mrobinson, #45390, #45382), HTMLInputElement (@steigeo, #45416), IntersectionObserver (@jdm, #45655, #45659, #45680), new Response() (@yezhizhen, #45953), URL.createObjectURL() and URL.revokeObjectURL() (@yezhizhen, #45182, #45417), and ECDSA and Ed25519 in SubtleCrypto (@kkoyung, #45833, #46017).
We've fixed bugs related to <input hidden> (@mrobinson, #45750), 'animation-delay' (@yezhizhen, #45013), 'clip-path' (@Loirooriol, #45468, #45373), 'tab-size' (@SimonSapin, @mrobinson, #45309), 'width' and 'height' (@RichardTjokroutomo, #44627), 'box-shadow: inset' (@Loirooriol, #45620), 'animationiteration' events (@Loirooriol, #45990), 'click' events (@mrobinson, #45751), 'load' events (@jdm, #45883), 'error' events in Worker global scopes (@Gae24, #45829), and document.getElementById() (@mrobinson, #45433).
Garbage collection safety
We use a RefCell-based mechanism to store many of our DOM types in other DOM types, enforcing Rust's "aliasing xor mutability" rule at runtime by panicking if the rule is violated. But when garbage collection happens, we need to borrow() each DomRefCell to trace the references, and this is the source of many panic bugs. To fix that whole class of bugs, we initially created CanGc, a marker type that would annotate the code paths where GC can occur, in conjunction with custom static analysis (@jdm, #33140).
With the Rust type system we can do even better, if we flip that around and require any borrow_mut() call to prove that GC can not occur by passing a NoGC marker value. We can then require that a &NoGC must be borrowed from a &JSContext (which blocks GC) and not a &mut JSContext (which allows GC), taking advantage of how Rust references work without needing any custom static analysis.
We have a large codebase that needs to be migrated in parts, so for now we've created the new method safe_borrow_mut() (@sagudev, #46050). We also need to update all of our script-related code to borrow our safe JSContext wrapper, rather than creating an owned JSContext on the spot.
This continues our long-running effort to use the Rust type system to make Servo's integration with SpiderMonkey safer and more reliable (@Gae24, @Keerti707, @Narfinger, @TimvdLippe, @sagudev, @guptapiyush16, @ivomurrell, @kunalmohan, @skyz1, #45230, #45436, #45503, #45617, #45711, #45797, #45800, #45858, #45884, #45937, #45902, #45968, #45977, #45991, #46003, #46005, #46084, #45548, #45552, #45590, #45909, #45912, #45943, #46089, #46117, #46114, #45320, #45324, #45328, #45340, #45381, #45385, #45410, #45392, #45409, #45604, #45616, #45618, #45627, #45636, #45662, #45663, #45675, #45674, #45677, #45684, #45735, #45807, #45810, #45816, #45818, #45828, #45838, #45836, #45837, #45840, #45841, #45857, #45859, #45862, #45875, #45887, #45931, #45964, #45935, #45987, #45988, #46001, #46040, #46051, #46057, #46106, #46125, #45678, #46002, #45845, #45645, #45673, #45259, #45817, #45822, #45876, #45877, #45891).
Performance and stability
NoGC was designed to prevent dynamic borrow failures, but it also enables some performance optimisations! If we can prove that garbage collection is impossible in some part of Servo, we can often avoid rooting JavaScript objects when interacting with them within that region of code. This has allowed us to reduce overheads by over 1% in the layout process and in HTMLCollection (@Narfinger, #46092, #45582).
Our memory usage has improved, with BoxFragment now 17% smaller (288 → 240 bytes on amd64) and ShapeCacheEntry now smaller too (@SimonSapin, @mrobinson, @simonwuelker, #45183, #45496).
We've fixed some nasty memory leaks when reloading and in 2D canvases (@Taym95, @sagudev, @jschwe, #45455, #45261, #45414).
Speaking of which, 2D canvases now use up to 23% less power (@yezhizhen, #45301), and we now avoid rasterising the same SVG more than once (@Narfinger, @jschwe, #44805).
Servo now decodes all images asynchronously and fills image caches asynchronously, leaving script threads (web content processes) more time for other work (@Narfinger, #45542, #44483). On top of that, we've improved incremental layout (@mrobinson, @Loirooriol, #45411) and reduced reflows in IntersectionObserver (@jschwe, #45986).
We've started working on incremental updates for the stacking context tree, and as a side effect, we've made some layout-bound microbenchmarks up to 10% faster (@mrobinson, @Loirooriol, #45208).
We've also reduced allocations, copies, GC rooting steps, and other operations in many parts of Servo (@Narfinger, @SimonSapin, @mrobinson, @Loirooriol, #45506, #45969, #45940, #45760, #46090, #45335, #45413, #45511).
For several months, Frédéric (@fred-wang) has been fuzzing for Servo bugs, and thanks to his work we've fixed sixteen (16) crash bugs in June, affecting <iframe>, <slot>, <link onerror>, 'animation', 'clip-path', 'content', 'rotate', 'transition', 'transform-style', 'display: contents', 'overflow: clip', CSSKeyframesRule, FontFace, stop() on Window, document.elementFromPoint(), and the DOM tree (@mrobinson, @Loirooriol, @fred-wang, #46031, #46027, #46054, #46058, #46016, #46028, #46033, #45287, #45951, #45634, #45629, #46110, #46094, #45799, #45611, #45682, #45788, #45612, #45834).
We've also fixed crash bugs related to IPC failures, HTMLInputElement, Range, the DevTools Debugger tab, and when servoshell is built with --features native-bluetooth (@jschwe, @Taym95, @mrobinson, @atbrakhi, @mukilan, #45311, #45619, #45765, #45513, #45702).
New contributors
A special thanks to the following people for landing their first patch in Servo:
- Deepam Goyal (@Deepam02, #44836)
- Mark (@Mark-Boger, #45486)
- Mr SheerLuck (@MrSheerluck, #45557)
- Psychpsyo (Cameron) (@Psychpsyo, #45494)
- TusharSariya (@TusharSariya, #43663)
- Adam Sharif (@adamsharifc, #45551)
- Akash Ravikumar (@ak4shravikumar, #45736)
- Sean Cunneen (@alexcat3, #45419)
- Abdul Wahab Melethil Shibu (@cychronex-labs, #45880)
- darkdragon-001 (@darkdragon-001, #45267)
- Frédéric Wang Nélar (@fred-wang, #45834)
- fxzjshm (@fxzjshm, #45285)
- Piyush Gupta (@guptapiyush16, #45845)
- Ivo Murrell (@ivomurrell, #45645)
- rhit-kapilaar (@rhit-kapilaar, #45556)
- sahvx655-wq (@sahvx655-wq, #45510)
- Kagami Sascha Rosylight (@saschanaz, #45731)
- shangguanmachine-dot (@shangguanmachine-dot, #45310)
- Glenn Skrzypczak (@skyz1, #45471)
- Oskar Steiger (@steigeo, #45416)
- Veyndan Stuart (@veyndan, #45326)
Interested in helping build a web browser? Take a look at our curated list of issues that are good for new contributors!
Donations
Thanks again for your generous support! We are now receiving 7681 USD/month (+0.2% from May) in recurring donations. This helps us cover the cost of our speedy CI and benchmarking servers, one of our latest Outreachy interns, and funding maintainer work that helps more people contribute to Servo.
Servo is also on thanks.dev, and already 35 GitHub users (same as May) that depend on Servo are sponsoring us there. If you use Servo libraries like url, html5ever, selectors, or cssparser, signing up for thanks.dev could be a good way for you (or your employer) to give back to the community.
We now have sponsorship tiers that allow you or your organisation to donate to the Servo project with public acknowlegement of your support. If you're interested in this kind of sponsorship, please contact us at join@servo.org.
Use of donations is decided transparently via the Technical Steering Committee's public funding request process, and active proposals are tracked in servo/project#187. For more details, head to our Sponsorship page.
31 Jul 2026 12:00am GMT
30 Jul 2026
Planet Mozilla
Thunderbird Blog: Mobile Progress Report: July 2026

Thunderbird Mobile is moving forward with large steps on both platforms we support. On iOS, we're working on the very foundation of a new app-our first built from scratch-and continuing to make progress in bringing the Thunderbird for iOS app to the App Store. For Android, it's a matter of updating what we have in place to make it easier to use, more reliable, and more efficient. Both platforms are rushing forward to deliver exactly what our users expect from us.
iOS
Starting off with iOS, we've focused on a few vital components. This includes the compose screen, account drawer, and OAuth, which allows users to add their accounts using the sign in page of their email provider. For the compose view, our HTML rich text editor is coming along nicely. We forked a WYSIWYG repository, Infomaniak's "swift-rich-html-editor," to create a rich text view for both composing and editing. We also added view headers, fixed a bug where we weren't applying links properly to the DOM, and began porting a proof of concept over to the main app code. This will eventually become the compose view for the final app. We also started the technical design phase for the new account drawer design.
Android
The Android team has been busy looking into drastic changes to the app to make it more user-friendly, faster, and more reliable. We're directly targeting feedback we've received. We're also continuing work on developer-friendly features to make contributing to the project easier and faster.
Database Rewrite
We've started our large database refactor with a tentative selection of Room. We chose this for a number of reasons, including performance, easier writing of data entities, and the ease of introduction for new engineers. Room is common in Android development, which means we can more quickly onboard new contributors with it. We'll have an RFC out by the end of August detailing how we'll implement the new database.
So why are we rewriting the database? It's the source of a number of issues with the app. Everything runs through it, from fetching locally-stored drafts, triggering notifications for new messages, syncing, reliability, and even power consumption. By updating the database, we make it possible to drastically improve everything in the app it touches, which is to say, everything.
Feature Flags
Developers will also be happy to know we're improving the feature flag process. We've completed an RFC for a new schema and began work on the technical documentation. We're looking to develop a local feature flag library that will use OpenFeature and eventually enable remote feature flag management, though that's not our short term goal. For now, we want to make it easier to create and modify feature flags across build types, without needing to edit so many files to do so. In the future, however, this will make it easier for us to roll out releases, updated features, and even rolling back features that may have issues without having to wait for the app release and approval cycle. It allows us to make a more reliable app with faster feature implementations.
Notifications
Finally, we've heard that our users do not like how we handle notifications. We've been investigating reported bugs and working to find a path forward that allows us to use previous work to improve notifications.
We're also looking into a key complaint: setting up notifications and "push" (IMAP Idle) notifications is just too difficult. We don't make it easy enough for users to set up their notifications and ensure they get email notifications when their email server reports updates. Users have made it clear: that has to change.
We're currently discussing options with design to consolidate some settings, bring other settings to the forefront, and will be working next month to activate "push" notifications by default for new accounts that support it.
We know notifications are a cause of headaches, even for those who understand how to use the app's existing features, so we want to address them as quickly as possible. We'll also focus on identifying issues and helping our users report problems with notifications in detail with user-enabled and anonymous logging that can help us see why a notification did not show for a new email if they want to help us work through it.
Bolt Design Library
Android has also begun the work of moving our Bolt design library out of the app to serve as a standalone library. Currently, we've pulled out the foundation layer for mobile that includes fonts, colors, spacing, and other repeated values. Eventually we'll use WebASM to render the design system and allow contributions directly to the design system, without needing to touch the Android app, potentially allowing it to be platform independent.
Community
Two crashes were caught in the beta, including a crash related to relative date formats and another to webviews. We want to thank our amazing community of beta testers who helped us catch these before they made it to a full release. Our community contributors have also directly fixed bugs, like issues scrolling horizontally in message views, fixing a button that couldn't be seen properly in dark mode, fixing an issue with the wrong number of messages in confirmation dialogs, and updates to our historical changelog data to be in a more readable and usable format. We can't thank our community of testers, contributors, and users enough for the work they put in helping us make Thunderbird a better email client.
We couldn't do what we do without you, and, as always, thank you for being part of the Thunderbird community. Here's to another month making the best email client we can, together!
- Danielle G. (she/her), Senior Android Engineer
The post Mobile Progress Report: July 2026 appeared first on The Thunderbird Blog.
30 Jul 2026 7:00pm GMT
29 Jul 2026
Planet Mozilla
About:Community: Community Roundup: Project Nova, Tab Groups & more
Firefox keeps evolving, and the community continues to play a big part in shaping what's next.
In this edition, you can get an early look at Project Nova through our latest foxfooding opportunity, explore Tab Groups on Android, join the conversation on Mozilla's latest browser choice research, and meet an Outreachy contributor whose journey reminds us why open source thrives through collaboration.
Get ready to dive in!
Hot from the oven: Join Project Nova foxfooding
We teased it in the last edition, and now it's here. Project Nova has finally arrived on Firefox Nightly, and you're invited to be an early tester! Get a look at Firefox's refreshed design as we put the finishing touches on the experience ahead of its broader release later this year. If you're curious about what's coming next, this is your chance to try it out, share your feedback, and help shape the final product.
Monthly Community Call today!

Want to ask questions directly to the people working on Firefox? Join us for today's Monthly Community Call, where we'll discuss Project Nova and Firefox performance feature with members of the teams working on these projects. Join the call today, July 29, 2026, at 5:00 PM UTC, and bring your questions!
Tab groups arrives on Android
You've been calling out for tab group functionality on Firefox mobile and now Tab Groups have officially arrived on Firefox for Android! Tab Groups make it easier to organize related tabs into color-coded groups for work, travel, shopping, research, or whatever you're browsing. Give it a try, and if you have ideas for how it could be even better, let us know on Mozilla Connect.
From the Reddit Community
Mozilla recently shared new independent research examining how browser choice is shaped by the design of operating systems. The report explores the obstacles users can encounter when downloading, setting, or continuing to use their preferred browser, and argues that people should be able to choose their browser without unnecessary friction. Read the report, join the discussion, and share your perspective!
And of course, thanks to you for choosing Firefox!
Community spotlight
Every contributor starts somewhere. In a recent blog post, Ananya Shree Sharma reflects on her journey through the Outreachy internship with Firefox. From navigating a large open source codebase for the first time to collaborating with mentors, learning new skills, and shipping meaningful improvements. Her story is a reminder that open source is as much about learning, mentorship, and community as it is about writing code. If you've ever wondered what it feels like to contribute to Firefox, Ananya's reflections offer an inspiring look at the experience and the people who make it possible.
P.S.
Enjoyed these updates? Subscribe to the Mozilla Community Newsletter and get the latest updates delivered straight to your inbox.
29 Jul 2026 9:04am GMT
This Week In Rust: This Week in Rust 662
Hello and welcome to another issue of This Week in Rust! Rust is a programming language empowering everyone to build reliable and efficient software. This is a weekly summary of its progress and community. Want something mentioned? Tag us at @thisweekinrust.bsky.social on Bluesky or @ThisWeekinRust on mastodon.social, or send us a pull request. Want to get involved? We love contributions.
This Week in Rust is openly developed on GitHub and archives can be viewed at this-week-in-rust.org. If you find any errors in this week's issue, please submit a PR.
Want TWIR in your inbox? Subscribe here.
Updates from Rust Community
Newsletters
Project/Tooling Updates
- afrim 0.7.0: a generic input method framework
- Sharing Rust build work across Cargo worktrees with cargo-reapi
- exiftool-rs 0.7.0: localizing ExifTool's PrintConv values, not just its labels
- Announcing SeaORM 2.0
- kobe 0.37.0: easier to deploy and install
- kache 0.12.0: pluggable remotes, smarter GC, sharper diagnostics
- Progress toward compiling Linux with gccrs
- flodl 0.7.0: one dashboard view, repeated at every level
- samkhya 1.2.1 - the join-cardinality ceiling becomes provable
- BrewFS: a Rust and JuiceFS-like distributed filesystem
Observations/Thoughts
- Improving std::simd::swizzle_dyn
- Query cycles: A compiler murder mystery
- GDPatch: a versatile Godot mod loader
- Memory Safety Absolutists
- C++ to Rust Migration
- High-Performance Flat 2D Arrays in Rust with SIMD, L1 Cache
- Building Java-Rust Microservices with TeaQL: Models, Events, and Audit Intent
- How We Cut a Trading Bot's Reaction Time from ~2 Seconds to Milliseconds - by Moving Only the Hot Path to Rust
- ESP32 Server: Distributing HTTP/2 streams over TLS
- [video] Rust Berlin Talks · 23/07/2026
Rust Walkthroughs
- No Tokens Yet Does Not Mean a Rust LLM Stream Is Safe to Retry
- [series] Rama 101.2: Core Concepts
- [video] [series] What's Inside Axum?
Crate of the Week
This week's crate is cargo-efmt, a drop-in replacement for cargo fmt to support .editorconfig.
Thanks to kleines Filmröllchen for the self-suggestion!
Please submit your suggestions and votes for next week!
Calls for Testing
An important step for RFC implementation is for people to experiment with the implementation and give feedback, especially before stabilization.
If you are a feature implementer and would like your RFC to appear in this list, add a call-for-testing label to your RFC along with a comment providing testing instructions and/or guidance on which aspect(s) of the feature need testing.
No calls for testing were issued this week by Rust, Cargo, Rustup or Rust language RFCs.
Let us know if you would like your feature to be tracked as a part of this list.
Call for Participation; projects and speakers
CFP - Projects
Always wanted to contribute to open-source projects but did not know where to start? Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
- No Calls for participation were submitted this week.
If you are a Rust project owner and are looking for contributors, please submit tasks here or through a PR to TWiR or by reaching out on Bluesky or Mastodon!
CFP - Events
Are you a new or experienced speaker looking for a place to share something cool? This section highlights events that are being planned and are accepting submissions to join their event as a speaker.
- No Calls for papers or presentations were submitted this week.
If you are an event organizer hoping to expand the reach of your event, please submit a link to the website through a PR to TWiR or by reaching out on Bluesky or Mastodon!
Updates from the Rust Project
570 pull requests were merged in the last week
Compiler
- apply RemoveNoopLandingPads post-monomorphization
- closures inherit
#[optimize]from the enclosing function by default - fix
boolcalling convention for aarch64, etc - optimize
escape_string_symbol() proc_macro: Fixcfg_attrinner attrs in file modules- resolve: more preperation work for parallelizing the import resolution loop
- stabilize c-variadic function definitions
Library
- constify
vec![1, 2, 3]macro - core: implement
Rngfor references - define a
Simdtype inminicore - implement
CovariantUnsafeCell - implement
str::copy_from_str - iter: extend
step_byspecialization to coverStepBy<RangeIter<{integer}>> - move
std::io::bufferedtoalloc::io - num: improve error messages for
TryFromIntError - str: add ASCII fast path to
word_to_titlecase - switch implementations of
thread_local!for WASI
Cargo
- add haiku's dylib path
diag: bound transitive unused dependency traversalgit: Hide git fetch output without progressgit: Suggest libgit2 if git-cli failstest: gate trim-paths tests on split debuginfo supporttoml: warn on hyphenated lint names and duplicates- allow setting
-Zembed-metadatavalue from the config - enable build-dir layout v2 on nightly by default
- zsh completion: Add
-pand--packageflags forcargo add
Rustfmt
- allow file not found errors for external mods annotated with
#[my_macro] - discover modules via
cfg_select!
Rustdoc
- add paths for linked associated items
- Retrieve
cfg_attrinformation for derived impls fordoc_cfgfeature - only build extern trait impls if needed
- only inline impls for local primitives
Clippy
- add
EULER_GAMMAandGOLDEN_RATIOtoapprox_constant - add
assert_is_emptylint - apply safety comment to compound assignment statement
blocks_in_conditions: Don't lint if the block creates temporarie…- call
in_external_macroafter running other checks in various places - do not trigger
clippy::exitwhen expression comes from an external macro duration_suboptimal_units: print the complete method name in the suggestion- extend
branches_sharing_codeto match arms with a shared tail min_ident_charslint short idents even if follows trait namingmultiple_unsafe_ops_per_block: false positive in with taking an reference to a static, but not reading/writing it- fix
four_forward_slashesfalse positive on inner doc comments lint-page: add accessible labels to filters- new lint:
nonnull_unchecked_on_box_ptr - perf: avoid per-call type and path work in
unnecessary_mut_passed - perf: find tab groups in doc comments without allocating
- rewrite
EndianByteslint pass
Rust-Analyzer
- add diagnostic for
structpatterns which don't specify sub-patterns for its fields - add parentheses for invert general expression
- attach db on worker threads in parallel analysis-stats inference
- change unsupported toolchain version to match reality
- discover protocol should only parse stdout
- do not detect
#[rust_analyzer]as#[rust_analyzer::rust_fixture] - don't offer
replace_qualified_name_with_useon an unqualified path - don't panic on a qualified path whose trait is not a trait
- don't pick a discriminant type larger than typeck's
- fix stale lock file
- fix
.zip(None)call - give
impl_trait_with_diagnosticsa cycle result - make analysis-stats progress bar Unicode-safe
merge_importspanic on invalid paths- panic on macro-defined structs with unknown fields
- prefer
allocoverstdpaths whenpreferNoStdis set - record obligation chain for unimplemented trait diagnostics and show it
- replace detach with delete for
ast::IdentPat - resolve path on all namespace on
resolve_path - respect
references.exclude[Tests/Imports]in references lens - scoped lazy priming
- support inactive-code diagnostic in macros
- uses bool instead pat ty in guard
Rust Compiler Performance Triage
Several large improvements landed in the past week:
- rustdoc is on average roughly 16% faster across all of our doc benchmarks:
- rustdoc: Only inline impls for local primitives, 7% faster doc builds
- rustdoc: Only synthesize auto/blanket impls for documented items, another 7% faster doc builds
- rustdoc: Only build extern trait impls if needed, another 10% faster doc builds
- Early removal of no-op panic handling in debug builds. This speeds up Cargo by ~4% in cycle count.
- Optimize escape_string_symbol() sped up large
include_bytes!/include_str!through changes to string escaping, avoiding a regression in upcoming LLVM 23 upgrade.
Great to see so many improvements!
Triage done by @simulacrum. Revision range: d527bc9b..ad0c9dce
Approved RFCs
Changes to Rust follow the Rust RFC (request for comments) process. These are the RFCs that were approved for implementation this week:
- No RFCs were approved this week.
Final Comment Period
Every week, the team announces the 'final comment period' for RFCs and key PRs which are reaching a decision. Express your opinions now.
Tracking Issues & PRs
- Shallow resolve ty and const vars to their root vars, attempt 2
- Ensure inferred let pattern types are well-formed
- stabilize
c_variadic_naked_functions - lint against repeated repr attributes
- Stabilize passing 128-bit integers via vector registers with
asm!on x86 - Add new
invalid_markdown_tablerustdoc lint - allocations: document that they can be read-only
- allocations are allowed to grow (but not shrink)
- Tracking Issue for
bool::toggle - Tracking Issue for const_btree_len
- Wasm proc macro support
-
Optimize repr(Rust) enums by omitting tags in more cases involving uninhabited variants.
- Proposal for Adapt Stack Protector for Rust
- feat(profile): Add built-in profile debug
- feat(toml): allow overriding inherited default-features in 2024
No Items entered Final Comment Period this week for Language Reference, Language Team, Leadership Council or Unsafe Code Guidelines. Let us know if you would like your PRs, Tracking Issues or RFCs to be tracked as a part of this list.
New and Updated RFCs
Upcoming Events
Rusty Events between 2026-07-29 - 2026-08-26 🦀
Virtual
- 2026-07-30 | Virtual (Berlin, DE) | Rust Berlin
- 2026-07-31 | Virtual (Girona, ES) | Rust Girona
- 2026-08-01 | Virtual (Kampala, UG) | Rust Circle Meetup
- 2026-08-02 | Virtual (Dallas, TX, US) | Dallas Rust User Meetup
- 2026-08-03 | Virtual (Global) | Rust Maven
- 2026-08-04 | Virtual (London, UK) | Women in Rust
- 2026-08-04 | Virtual (Tel Aviv-yafo, IL) | Rust 🦀 TLV
- 2026-08-05 | Virtual (Cardiff, UK) | Rust and C++ Cardiff
- 2026-08-05 | Virtual (Indianapolis, IN, US) | Indy Rust
- 2026-08-07 | Virtual (Girona, ES) | Rust Girona
- 2026-08-11 | Virtual (Dallas, TX, US) | Dallas Rust User Meetup
- 2026-08-13 | Virtual (Berlin, DE) | Rust Berlin
- 2026-08-13 | Virtual (Nürnberg, DE) | Rust Nuremberg
- 2026-08-14 | Virtual (Girona, ES) | Rust Girona
- 2026-08-18 | Virtual (Washington, DC, US) | Rust DC
- 2026-08-19 | Hybrid (Vancouver, BC, CA) | Vancouver Rust
- 2026-08-20 | Hybrid (Seattle, WA, US) | Seattle Rust User Group
- 2026-08-20 | Virtual (Charlottesville, VA, US) | Charlottesville Rust Meetup
- 2026-08-21 | Virtual (Girona, ES) | Rust Girona
- 2026-08-25 | Virtual (Dallas, TX, US) | Dallas Rust User Meetup
Africa
- 2026-08-11 | Johannesburg, ZA | Johannesburg Rust Meetup
Asia
- 2026-08-22 | Bangalore, IN | Rust Bangalore
- 2026-08-22 | Delhi, IN | Rust Delhi
- 2026-08-22 | Noida, IN | SciPy India
Europe
- 2026-07-29 | Poland, PL | Rust Poland
- 2026-07-30 | Copenhagen, DK | Copenhagen Rust Community
- 2026-07-30 | Manchester, UK | Rust Manchester
- 2026-08-06 | Oxford, UK | Oxford ACCU/Rust Meetup.
- 2026-08-18 | Aarhus, DK | Rust Aarhus
- 2026-08-18 | Leipzig, DE | Rust - Modern Systems Programming in Leipzig
- 2026-08-20 | Frankfurt, DE | Rust Rhein-Main
North America
- 2026-07-30 | Atlanta, GA, US | Rust Atlanta
- 2026-08-01 | Boston, MA, US | Boston Rust Meetup
- 2026-08-04 | Boston, MA, US | Boston Rust Meetup
- 2026-08-06 | Mountain View, CA, US | Hacker Dojo
- 2026-08-06 | Saint Louis, MO, US | STL Rust
- 2026-08-13 | Lehi, UT, US | Utah Rust
- 2026-08-13 | San Diego, CA, US | San Diego Rust
- 2026-08-15 | San Francisco, CA, US | Flower
- 2026-08-18 | San Francisco, CA, US | San Francisco Rust Study Group
- 2026-08-19 | Hybrid (Vancouver, BC, CA) | Vancouver Rust
- 2026-08-19 | San Francisco, CA, US | Rust Bay Area
- 2026-08-20 | Hybrid (Seattle, WA, US) | Seattle Rust User Group
- 2026-08-26 | Austin, TX, US | Rust ATX
Oceania
- 2026-07-30 | Melbourne, AU | Rust Melbourne
South America
- 2026-08-08 | São Paulo, SP | Rust-SP
If you are running a Rust event please add it to the calendar to get it mentioned here. Please remember to add a link to the event too. Email the Rust Community Team for access.
Jobs
Please see the latest Who's Hiring thread on r/rust
Quote of the Week
So let's talk about what the process has looked like for Netstack3. For 11 months, the team has been ramping up a dogfooding program. At peak, that program has seen about 60 devices running nearly 24/7 in developers' homes.
Again, if this were any other netstack, we would have expected to uncover a giant mountain of bugs in that time. So, over the past year, how many bugs did the team uncover in the field?
Three.
- Josh Liebow-Feeser on his blog
llogiq again has no one to thank for a suggestion, so he is thankful to himself for finding this quote instead.
Please submit quotes and vote for next week!
This Week in Rust is edited by:
- nellshamrell
- llogiq
- ericseppanen
- extrawurst
- U007D
- mariannegoldin
- bdillo
- opeolluwa
- bnchi
- KannanPalani57
- tzilist
Email list hosting is sponsored by The Rust Foundation
29 Jul 2026 4:00am GMT
27 Jul 2026
Planet Mozilla
Firefox Tooling Announcements: MozPhab 2.15.4 Released
Bugs resolved in Moz-Phab 2.15.4:
- bug 2058150
moz-phab patchcrashes withKeyErrorwhen a stack relative is not visible to the user
Discuss these changes in #engineering-workflow on Slack or #Conduit Matrix.
1 post - 1 participant
27 Jul 2026 4:15pm GMT
Firefox Nightly: Try the New Firefox Design in Nightly
This past May, we shared our vision for the future of Firefox. Starting today, you can try out the next design evolution of Firefox in Nightly.
It's still Firefox, now with a more cohesive look and feel across tabs, menus, panels, and other browser surfaces. You'll notice softer tab shapes, a warmer color palette, updated icons, and - after hearing from many of you - the return of Compact Mode and new theme options to make Firefox your own.
Many of you have already spotted pieces of the new design in Nightly over the past few months. Now they're coming together into one complete experience.
You'll continue to see updates over the coming weeks as we polish the new Firefox design before it reaches Firefox users more broadly later this year. As you browse, we're especially interested in any visual or functional issues you encounter.
Keep an eye out for things like:
- Icons, spacing, and alignment
- Themes and personalization
- Different window sizes and display scaling
- Keyboard navigation
- Screen readers and other accessibility features
- Different languages and layouts
Found a bug?
If something doesn't look or behave as expected, please file a bug in Bugzilla.
When possible, include:
- Steps to reproduce the issue
- Screenshots or screen recordings
- Your operating system and Nightly version
If you have broader thoughts or questions about your experience, join the discussion on Mozilla Connect.
Thanks for using Nightly and helping us improve Firefox. Every bug report helps us identify issues and continue refining the new Firefox design before it reaches Firefox users more broadly later this year.
27 Jul 2026 3:00pm GMT
23 Jul 2026
Planet Mozilla
Firefox Tooling Announcements: Happy BMO Push Day! (20260723.{1,2})
The following changes have been pushed to bugzilla.mozilla.org:
- Bug 2055236 - The column headers in Github PR are barely visible in dark mode
- Bug 2054574 - Do not auto-assigning Hackbot when submitting a Phabricator revision
The following changes have been pushed to bugzilla.mozilla.org:
- Bug 2055285 - Remove the "Show closed/merged PR" checkbox in the GH PR view
Discuss these changes in the BMO Matrix Room
1 post - 1 participant
23 Jul 2026 10:34pm GMT
Mozilla Addons Blog: Firefox 153 WebExtensions API updates
We had a bumper release of WebExtensions API updates in Firefox 153. To start, there is a permissions change that affects how your extensions access local files. We then have two contributions from the community members: userScripts.execute() and the new publicSuffix API. We're covering those contributions in more depth, including the people behind them, in a separate post. And there is more, read on…
File access now requires a dedicated permission
Extensions that need to read file:// URLs used to get that access as part of the "Access your data for all websites" host permission. Starting in Firefox 153, file access is a separate, explicit permission, "Access local files on your computer", shown in the extension's permissions settings. It's off by default for every extension, including ones already installed.
This change has a few concrete effects on code:
- Before: an extension with <all_urls> or a matching host permission could read file:// pages without any additional grant, and extension.isAllowedFileSchemeAccess() always returned false regardless of the permission setting.
- After: the extension must have the new file-access permission granted, and extension.isAllowedFileSchemeAccess() correctly reflects whether the user has granted it.
async function checkFileSchemeAccess() {
const isAllowed = await browser.extension.isAllowedFileSchemeAccess();
if (!isAllowed) {
await browser.notifications.create("file-scheme-access-needed", {
type: "basic",
iconUrl: browser.runtime.getURL("icons/icon-48.png"),
title: "Local file access required",
message:
'This extension needs "Allow access to file URLs" enabled to work ' +
"with local files. Go to about:addons → select this extension → " +
"turn on that setting, then reload the page.",
});
return false;
}
return true;
}
devtools.inspectedWindow.eval() calls targeting file:// URLs are affected the same way; they now require this permission to succeed.
If your extension depends on file:// access, expect existing users to see that access stops after upgrading (until they enable the permission), and consider adding a prompt or fallback path, for example by specifying an embedded options page (options_ui) and calling browser.runtime.openOptionsPage() to open about:addons and including instructions to toggle the setting in the "Permissions and data" tab.
userScripts.execute() and publicSuffix: covered in our next post
Firefox 153 adds two community-contributed APIs:
- userScripts.execute(), which provides for one-off injection of one or more user script sources into a tab or frame, in a defined order, as a complement to the persistent, URL-pattern-based userScripts.register().
- publicSuffix, which enables synchronous lookups against the browser's built-in Public Suffix List using publicSuffix.isKnownSuffix(), publicSuffix.getKnownSuffix(), and publicSuffix.getDomain(). This API means that extensions no longer need to bundle or maintain a suffix list to determine a hostname's registrable domain (eTLD+1).
Both APIs were built by contributors motivated by real needs in their extensions. We take an in-depth look at these contributions, their developers, impact, and history in a forthcoming post.
documentId support across more APIs
Firefox 153 introduces documentId, a stable identifier for a document instance, including a new runtime.getDocumentId() method, several webNavigation events and methods, webRequest events, scripting injection targets, and the extension messaging APIs.
Many WebExtension APIs use tabId and frameId to identify where to perform an operation. However, because frameId identifies the frame rather than its content, the loaded document can change and the extension's subsequent operation ends up targeting the new (intended) document. documentId addresses this problem by providing a unique ID for the document. Now, if an extension uses the ID and the frame's document has changed, the operation fails rather than silently targeting the wrong document.
See Work with documentId for the full list of supported events and methods, along with guidance on using it.
Content scripts can read and modify adopted stylesheets
Content scripts can now access document.adoptedStyleSheets and ShadowRoot.adoptedStyleSheets directly.
const sheet = new CSSStyleSheet();
sheet.replaceSync("* { background: pink; }");
document.adoptedStyleSheets = [sheet];
This enables extensions to inspect or modify constructed stylesheets from a content script, without using .wrappedJSObject, a workaround that risks interference from the web page.
Theme manifest key: gradients in additional backgrounds
The theme manifest key's images.additional_backgrounds property now accepts CSS gradients alongside image URLs. A new properties.additional_backgrounds_size property controls the size of each additional background item.
Contextual identities (containers)
If your extension supports contextual identities, you now have access to two new methods: contextualIdentities.getSupportedColors() and contextualIdentities.getSupportedIcons(). These methods return the supported colors and icons, so your extension doesn't need to hardcode either list.
Also, the colors have been updated to align with the new UI theme: "turquoise" is now "cyan", "toolbar" is now "gray", and "violet" has been added. The old names still work for backward compatibility, but your extension should switch to using getSupportedColors() rather than hardcoding either the old or new names.
Add a build-for-amo script
While this isn't about new APIs, I wanted to mention a change that's part of our work to make source code review faster and more reliable. When you submit an extension version, AMO now attempts to build your extensions from the submitted source code and compares the result to the package you uploaded. When the two match, reviewers don't have to verify the build manually. This means submission can move through its review faster.
For now, this applies only if you submit source code that includes a package.json file to build your extension. If your extension has no build step, or you use a different build system, nothing changes. The AMO builder keeps its zero-config approach.
So, if your extension's source code uses a package.json file, add an npm script named build-for-amo that runs the commands needed to build your extension for Firefox:
{
"scripts": {
"fx-build": "some commands to build your add-on for Firefox",
"build-for-amo": "npm run fx-build"
}
}
If you've a Firefox-specific build command, just point build-for-amo at it. When present, the builder invokes this script instead of guessing how to build your extension. And while you are at it, make sure all your dev dependencies are listed in the package.json file.
For more information, including documentation and Bugzilla links, see the Changes for add-on developers section of the Firefox 153 for developers release notes on MDN.
As always, file extension-related issues on Bugzilla under the WebExtensions product, cross-browser API proposals are discussed in the W3C WebExtensions Community Group, and questions are welcome on the Add-ons Discourse.
The post Firefox 153 WebExtensions API updates appeared first on Mozilla Add-ons Community Blog.
23 Jul 2026 11:35am GMT
22 Jul 2026
Planet Mozilla
Thunderbird Blog: Thunderbird 153 “Meadow” is out now!

As we head into the summer months, a new Extended Support Release (ESR) is in full bloom. Thunderbird 153 "Meadow" is out now, and from all of us at MZLA, the Thunderbird Council, and our global community of contributors, we can't wait for you to try it out.
"Meadow" builds on Thunderbird 140 "Eclipse," along with the steady stream of features and improvements that have landed in the Monthly Release channel over the past year. This release makes first-time setup smoother with a redesigned Account Hub, brings native Microsoft Exchange support out into the open, and lets Thunderbird take on the colors of your desktop. Add privacy-minded networking, friendlier notifications, and a healthy crop of refinements, and Meadow is ready to grow with you.

Easier Account Creation
The all-new Account Hub makes setting up accounts faster and more intuitive than ever, with improved autodiscover, automatic protocol detection, and automatic setup of connected calendars and address books.
Address Book Setup
The new Account Hub modal lets you set up all types of local and remote address books. Existing email accounts are automatically scanned to detect available address books that haven't been configured yet.


Microsoft Exchange Support
We've added full support for Exchange email servers via Exchange Web Services: set up Microsoft Exchange accounts natively to read, manage, and write emails, no add-ons required. Experimental Microsoft Graph support is already in core but temporarily disabled behind a preference while we finish it, with full support plus Calendar and Address Book integration aimed for later this year.
Accent Colors
Meadow now inherits your operating system's accent color to match your preferred look. You can also customize your colors with the new accent color settings in the Appearance tab.


Do More From Your Notifications
Mark an email as read, delete it, flag it as spam, and more right from the native notifications on your operating system.
In addition to these headline features, there's a whole host of other updates you'll love, including:

OAuth in Browser
Thunderbird now supports OAuth authentication directly in your default browser.

Login With Thundermail
If you have a Thundermail account, you can sign in to Thunderbird with one-click authentication in the Account Hub.

Folder Sorting
An improved UI and better visual indicators make sorting your emails easier than ever.

Bug Fixes and Improvements
Thousands of bug fixes and performance improvements bring you the smooth, reliable Thunderbird experience you expect.
Looking Forward
Thunderbird 153 "Meadow" might seem soothing and calm, but we're excited to get these features into your hands. And if you'd like updates like these more often, there's no need to wait for the annual release: switching to Thunderbird Release gets you new updates on a monthly basis.
Thunderbird 153 Availability for Windows, Linux, and macOS
Even with QA and beta testing, any major software release may have issues that only surface after significant public use. That's why we're rolling out automatic updates gradually, enabling them more broadly as we confirm everything is stable.
Manual upgrade to 153 is now enabled via Help > About - you can upgrade now or wait to receive automatic updates. Thunderbird 153.0 is also offered as a direct download from thunderbird.net. Be sure to select 'Thunderbird Extended Support Release' in the 'Release Channel' drop-down menu.
For Linux users running Thunderbird from the Snap or Flatpak, 153 will be available within the next few weeks. Likewise, Thunderbird 153 will arrive on the Microsoft Store by mid-July.
Full release notes can be found here.
If you have any issues, please reach out to support.
Have an idea? We want to hear it! Submit your ideas here.
The post Thunderbird 153 "Meadow" is out now! appeared first on The Thunderbird Blog.
22 Jul 2026 9:45pm GMT
Firefox Tooling Announcements: July 22nd Deploy
The latest version of PerfCompare is now live!
Check out the change-log below to see the updates:
[kala-moz]
-
Add KdeModesPanel to expanded view (#1052)
-
Dark Mode Bugs Fix (#1063)
-
Bug 2037556: simplify wording of tooltip text for CD and CLES; fix dark mode links in tooltips (#1067)
[moijes]
[sumairq]
Thank you for the contributions!
Bugs or feature requests can be filed on Bugzilla. The team can also be found on the #perfcompare channel on Element. Come and chat!
1 post - 1 participant
22 Jul 2026 5:36pm GMT
This Week In Rust: This Week in Rust 661
Hello and welcome to another issue of This Week in Rust! Rust is a programming language empowering everyone to build reliable and efficient software. This is a weekly summary of its progress and community. Want something mentioned? Tag us at @thisweekinrust.bsky.social on Bluesky or @ThisWeekinRust on mastodon.social, or send us a pull request. Want to get involved? We love contributions.
This Week in Rust is openly developed on GitHub and archives can be viewed at this-week-in-rust.org. If you find any errors in this week's issue, please submit a PR.
Want TWIR in your inbox? Subscribe here.
Updates from Rust Community
Official
Newsletters
Project/Tooling Updates
- Announcing Topcoat: a framework for building full-stack reactive web apps with Rust
- Syn 3.0.0
- What's New in RustRover 2026.2
- kobe 0.35.0: readiness gates and cert recycling
- Comhad v0.1.0: a ranger-style tui cyberduck replacement for browsing S3
- Nova v0.2.1: computer-use MCP server
- winit now has comprehensive cross-platform drag-and-drop support, exposing most of the power of the underlying OS APIs
- crimson-crab v0.1.0 - a production-grade Rust SDK for the Claude API (streaming, tool use, prompt caching, batches)
- ferrovec: dependency-light HNSW vector search in Rust, compiled to WebAssembly for private in-browser semantic search
- OrdoFP 0.1.0 released - a functional-programming toolbelt for Rust (HList, GAT type classes, optics, effects, monad transformers)
- Freya 0.4
- buildline: merging cargo and ninja's build profiling into one timeline
- cochlea 0.3.0: melody read-back, MFCC timbre, a master limiter, and MIDI import for the deterministic agent-audio engine
- flodl 0.6.0: multi-host heterogeneous DDP - mismatched GPUs across hosts beat the fastest card alone
- hwatu: a daemon-based WebKitGTK browser for tiling WMs with ~13ms window spawn
- kache 0.11.0: broader compiler coverage and libc-aware keys
tracing-reload- reload layer without panics- Introducing OpenTypeless: Voice Input That Actually Works
- Reading a Rust crate's capabilities out of its compiled symbols
Observations/Thoughts
- Battery packs: Let's talk about crates, baby
- Capture Clauses as Effects
- Hardening Rust Code For Production
- Tokio Gives Progress, Not Ordering: Scheduling 1M Tasks
- Rust service hardening and production checklist
- [audio] The Rust Foundation with Rebecca Rumbul, Lori Lorusso, and David Wood, Rust Foundation leadership and board
- [video] Jon Gjengset: Open Source Maintenance 2026-07-18
- [video] Rust Release Changelog - 1.97.0
- [video] Livestream: Rust in Ubuntu
Rust Walkthroughs
- I hash-chained my agent's audit log. Then I found 13 breaks in it - all mine, all benign.
- Two tricky bugs in a Rust daemon
- [video] Backend Concepts in Rust: Securely Managing App Secrets
- [video] Build with Naz - Ep 21: High Performance Flat 2D Arrays in Rust (SIMD, L1 cache)
Crate of the Week
This week's crate is xan, a TUI toolkit to work with CSV files.
Thanks to Simeon H.K. Fitch for the suggestion!
Please submit your suggestions and votes for next week!
Calls for Testing
An important step for RFC implementation is for people to experiment with the implementation and give feedback, especially before stabilization.
If you are a feature implementer and would like your RFC to appear in this list, add a call-for-testing label to your RFC along with a comment providing testing instructions and/or guidance on which aspect(s) of the feature need testing.
No calls for testing were issued this week by Rust, Cargo, Rustup or Rust language RFCs.
Let us know if you would like your feature to be tracked as a part of this list.
Call for Participation; projects and speakers
CFP - Projects
Always wanted to contribute to open-source projects but did not know where to start? Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
- No Calls for participation were submitted this week.
If you are a Rust project owner and are looking for contributors, please submit tasks here or through a PR to TWiR or by reaching out on Bluesky or Mastodon!
CFP - Events
Are you a new or experienced speaker looking for a place to share something cool? This section highlights events that are being planned and are accepting submissions to join their event as a speaker.
- No Calls for papers or presentations were submitted this week.
If you are an event organizer hoping to expand the reach of your event, please submit a link to the website through a PR to TWiR or by reaching out on Bluesky or Mastodon!
Updates from the Rust Project
576 pull requests were merged in the last week
Compiler
- account for async closures when pointing at lifetime in return type
- comptime inherent impls
dep_graph: deduplicate task reads with an epoch-filtered index recorder- eagerly check for ambiguity in macro parsing
- implement
#[diagnostic::opaque]attribute to hide backtraces of macros - shrink
ast::Expr64
Library
- add explicit
Iterator::countimpl forstr::EncodeUtf16 - implement
bool::toggle - implement
const_binary_search - implement
Debughelpers viaCell - implement
VecDeque::truncate_to_range - make
pin!()more foolproof - move
std::io::BufReadtoalloc::io - move
std::io::Readtoalloc::io - move
std::io::read_to_stringtoalloc::io
Cargo
- use PGO for Cargo
timings: only report units the job queue actually ran- do not include proc-macro deps in rustc search path args
- include SBOM outputs in fingerprints
- lazily initialize git2 fetch transports
Rustdoc
Clippy
- add
block_scrutineelint - avoid invalid
ref_as_ptrsuggestions in const/static initializers - detect
== 0on unsigned types as amanual_clamplower bound - fix
if_not_elselinting on macro expanded conditions - fix
needless_collectsuggests a suggestion that cannot be typed non_zero_suggestions: don't lint signed integer div/rem as NonZeromanual_filter: don't eat comments in theand_thensuggestion- require the use of
as _for indirectly used traits in clippy sources - rewrite
min_ident_chars - use
#[must_use]determination from the compiler
Rust-Analyzer
- avoid index panic when flycheck list is empty
- add capture hints to coroutines
- add handler for E0572
- do not assume array destructuring assignments with rest pattern are constant-sized
- eagerly normalize
.await'sIntoFuture::Output - enable auto trait inference
- extract variable preserving whitespace from macro input
- fix coroutines not recording binding owners correctly
- fix crashes in assists due to
.unwrap()calls in SyntaxFactory - fix
hircrate leaking bound variables from skipped binders - fix
InferenceContext:identity_argsusing the wrong DefId - fix syntax bridge panic when spilting float
- handle
enumvariants in next-solvergenerics - implement lowering of HRTB
- invalid
pattern_matching_variantlowering due to recovery - merge
WherePredicate::ForLifetimesintoWherePredicate::TypeBound - only write anon const ty in parent's inference result if it doesn't have its own inference
- panic with a function item and a proc macro item having a duplicate name
- parser to error on macro type bound
- spawn proc-macro servers on requests clearing the client cache
- use quote! inside
ast::make::expr_call() - use
Resultfor the lsp-serverResponsepayload type - record expressions in types in
ExprScope
Rust Compiler Performance Triage
The two most notable changes this week were #159115, which resulted in pretty nice instruction count wins for full incremental builds on several benchmarks, and #159091, which enabled PGO for rustdoc, which makes it ~3-4% faster across the board.
There were two large rollups with tiny performance regressions, which made it difficult to find the offending PRs.
Triage done by @Kobzol. Revision range: 5503df87..d527bc9b
Summary:
| (instructions:u) | mean | range | count |
|---|---|---|---|
| Regressions ❌ (primary) |
0.4% | [0.2%, 1.0%] | 40 |
| Regressions ❌ (secondary) |
0.7% | [0.2%, 4.6%] | 69 |
| Improvements ✅ (primary) |
-2.0% | [-6.2%, -0.2%] | 136 |
| Improvements ✅ (secondary) |
-2.6% | [-8.4%, -0.2%] | 119 |
| All ❌✅ (primary) | -1.4% | [-6.2%, 1.0%] | 176 |
2 Regressions, 3 Improvements, 6 Mixed; 4 of them in rollups 34 artifact comparisons made in total
Approved RFCs
Changes to Rust follow the Rust RFC (request for comments) process. These are the RFCs that were approved for implementation this week:
- No RFCs were approved this week.
Final Comment Period
Every week, the team announces the 'final comment period' for RFCs and key PRs which are reaching a decision. Express your opinions now.
Tracking Issues & PRs
- Tracking Issue for
bool::toggle - Tracking Issue for vec_try_remove
- Avoid computing layout of enums with non-int discriminants
- Tracking Issue for const_btree_len
- Add
raw_borrows_via_referenceslint - stabilize size_of_val_raw, align_of_val_raw, Layout::for_value_raw
- rustc_passes: lint unused
#[path]attributes on inline modules
- Emit
notewhen callingrustcwithout specifying an edition - Let the OS handle stack growth
- Add
target_feature_available_at_call_site
No Items entered Final Comment Period this week for Cargo, Language Reference, Language Team or Rust RFCs.
Let us know if you would like your PRs, Tracking Issues or RFCs to be tracked as a part of this list.
New and Updated RFCs
Upcoming Events
Rusty Events between 2026-07-22 - 2026-08-19 🦀
Virtual
- 2026-07-24 | Virtual (Girona, ES) | Rust Girona
- 2026-07-28 | Virtual (Dallas, TX, US) | Dallas Rust User Meetup
- 2026-07-28 | Virtual (Washington, DC, US) | Rust DC
- 2026-07-30 | Virtual (Berlin, DE) | Rust Berlin
- 2026-07-31 | Virtual (Girona, ES) | Rust Girona
- 2026-08-01 | Virtual (Kampala, UG) | Rust Circle Meetup
- 2026-08-02 | Virtual (Dallas, TX, US) | Dallas Rust User Meetup
- 2026-08-04 | Virtual (London, UK) | Women in Rust
- 2026-08-05 | Virtual (Indianapolis, IN, US) | Indy Rust
- 2026-08-07 | Virtual (Girona, ES) | Rust Girona
- 2026-08-11 | Virtual (Dallas, TX, US) | Dallas Rust User Meetup
- 2026-08-13 | Virtual (Berlin, DE) | Rust Berlin
- 2026-08-13 | Virtual (Nürnberg, DE) | Rust Nuremberg
- 2026-08-14 | Virtual (Girona, ES) | Rust Girona
- 2026-08-18 | Virtual (Washington, DC, US) | Rust DC
- 2026-08-19 | Hybrid (Vancouver, BC, CA) | Vancouver Rust
Africa
- 2026-08-11 | Johannesburg, ZA | Johannesburg Rust Meetup
Asia
- 2026-07-25 | Mumbai, IN | Rust Mumbai
- 2026-07-26 | Pune, IN | Rust Pune
Europe
- 2026-07-23 | Berlin, DE | Rust Berlin
- 2026-07-23 | London, UK | Rust London User Group
- 2026-07-23 | London, UK | London Rust Project Group
- 2026-07-23 | Paris, FR | Rust Paris
- 2026-07-25 | Stockholm, SE | Stockholm Rust
- 2026-07-27 | Augsburg, DE | Rust Meetup Augsburg
- 2026-07-29 | Poland, PL | Rust Poland
- 2026-07-30 | Copenhagen, DK | Copenhagen Rust Community
- 2026-07-30 | Manchester, UK | Rust Manchester
- 2026-08-18 | Aarhus, DK | Rust Aarhus
- 2026-08-18 | Leipzig, DE | Rust - Modern Systems Programming in Leipzig
North America
- 2026-07-22 | Austin, TX, US | Rust ATX
- 2026-07-22 | Los Angeles, CA, US | Rust Los Angeles
- 2026-07-22 | New York, NY, US | Rust NYC
- 2026-07-23 | Mountain View, CA, US | Hacker Dojo
- 2026-07-25 | Boston, MA, US | Boston Rust Meetup
- 2026-07-25 | Brooklyn, NY, US | Flower
- 2026-07-30 | Atlanta, GA, US | Rust Atlanta
- 2026-08-01 | Boston, MA, US | Boston Rust Meetup
- 2026-08-04 | Boston, MA, US | Boston Rust Meetup
- 2026-08-06 | Saint Louis, MO, US | STL Rust
- 2026-08-13 | Lehi, UT, US | Utah Rust
- 2026-08-13 | San Diego, CA, US | San Diego Rust
- 2026-08-15 | San Francisco, CA, US | Flower
- 2026-08-18 | San Francisco, CA, US | San Francisco Rust Study Group
- 2026-08-19 | Hybrid (Vancouver, BC, CA) | Vancouver Rust
Oceania
- 2026-07-23 | Perth, AU | Rust Perth Meetup Group
- 2026-07-30 | Melbourne, AU | Rust Melbourne
South America
- 2026-08-08 | São Paulo, SP | Rust-SP
If you are running a Rust event please add it to the calendar to get it mentioned here. Please remember to add a link to the event too. Email the Rust Community Team for access.
Jobs
Please see the latest Who's Hiring thread on r/rust
Quote of the Week
We were planning on publishing a blog post announcing this at the same time as making the repo public, but ran out of private repo CI usage 😭.
- Carl Lerche on r/rust about the launch of topcoat
Despite a lamentable lack of suggestions, llogiq is glad to have found this quote.
Please submit quotes and vote for next week!
This Week in Rust is edited by:
- nellshamrell
- llogiq
- ericseppanen
- extrawurst
- U007D
- mariannegoldin
- bdillo
- opeolluwa
- bnchi
- KannanPalani57
- tzilist
Email list hosting is sponsored by The Rust Foundation
22 Jul 2026 4:00am GMT
21 Jul 2026
Planet Mozilla
Firefox Developer Experience: Firefox WebDriver Newsletter 153
WebDriver is a remote control interface that enables introspection and control of user agents. As such, it can help developers to verify that their websites are working and performing well with all major browsers. The protocol is standardized by the W3C and consists of two separate specifications: WebDriver classic (HTTP) and the new WebDriver BiDi (Bi-Directional).
This newsletter gives an overview of the work we've done as part of the Firefox 153 release cycle.
Contributions
Firefox is an open source project, and we are always happy to receive external code contributions to our WebDriver implementation. We want to give special thanks to everyone who filed issues, bugs and submitted patches.
Firefox 153, multiple WebDriver bugs were fixed by contributors:
- Khalid AlHaddad updated our codebase to use constants instead of hard-coded strings for all our session data types.
- Khalid AlHaddad improved the window manipulation commands in Marionette and WebDriver BiDi to allow individual window geometry properties, such as x, y, width, and height, to be adjusted independently.
- Sameem updated the "Take Element Screenshot" command from WebDriver Classic to crop screenshots of elements which exceed the viewport. This aligns with the specification and avoids errors when attempting to capture huge elements.
WebDriver code is written in JavaScript, Python, and Rust so any web developer can contribute! Read how to setup the work environment and check the list of mentored issues for Marionette, or the list of mentored JavaScript bugs for WebDriver BiDi. Join our chatroom if you need any help to get started!
All Changes
A complete list of developer-facing changes included in this Firefox release is available in the MDN Firefox 153 Release Notes.
21 Jul 2026 8:18pm GMT
The Mozilla Blog: Your Android tabs just got a lot more organized with Firefox
Tabs pile up fast on mobile. Imagine you're planning a summer barbecue, and you start by searching for the best rib recipe. Twenty minutes later, you're 17 tabs deep: comparing marinades, debating side dishes, checking the weather, making a grocery list and adding songs to a playlist.
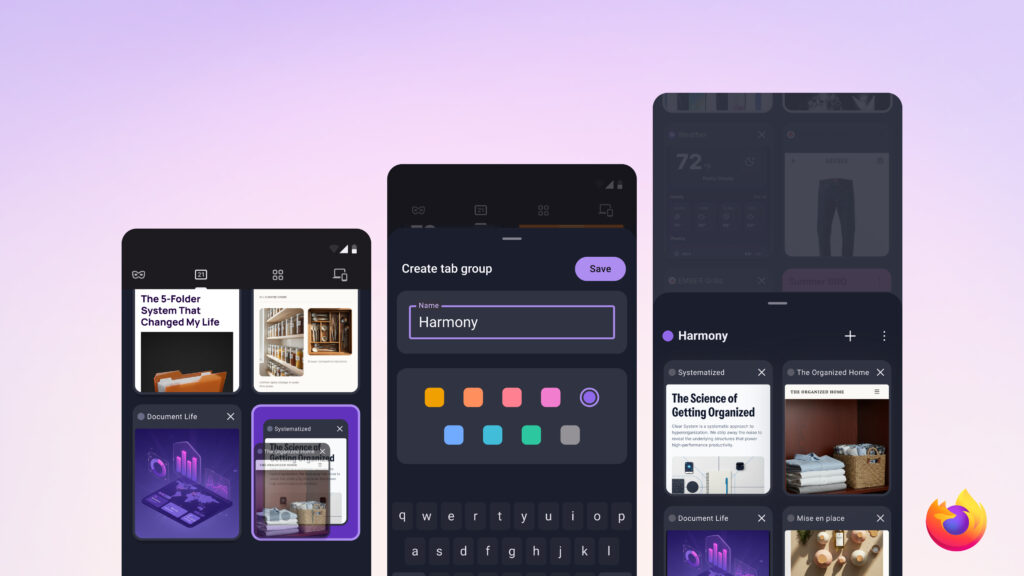
None of those tabs are organized. They're mixed in with everything else you've been browsing, making it hard to keep track of what you're saving for later.
Now you can group related tabs in Firefox for Android, keeping them together in labeled, colored groups so you can actually find what you need when you need it.

How it works
Drag one tab onto another, or select a few and tap "Add to group." Name it, pick a color, and you're done.
Each group appears as a single card in the tab tray rather than a dozen separate tabs. You can open it, rename it, recolor it, or delete it whenever you want. Search still finds tabs inside a group, too.
So when you're standing in the produce aisle looking for that rib recipe, you won't have to scroll past dozens of unrelated tabs just to find it. Everything for your barbecue is organized together in one place, ready when you need it.
Finally sorted, as it should be
Tab grouping was the most requested feature from Firefox mobile users in 2025. And we get it: your tabs shouldn't get harder to manage the more you use your browser. Download the latest version of Firefox for Android now to try Tab Groups, with iOS support on the way.
The post Your Android tabs just got a lot more organized with Firefox appeared first on The Mozilla Blog.
21 Jul 2026 4:00pm GMT
The Mozilla Blog: Quick Answers: For the questions in between
You're planning a trip. Reading an article. Following a recipe.
Then a question pops into your head. Sometimes it leads down a rabbit hole - with more searches, more tabs and plenty to explore. Other times, you just need a little context so you can get back to what you were doing.
That's why we're introducing Quick Answers for Firefox on iOS.
With Quick Answers, you can ask a question using your voice and get a concise answer. Just open a new tab, long-press the voice button and ask.
For example:
- "What does mellifluous mean?"
- "What is 95 degrees Fahrenheit in Celsius?"
- "What's the difference between suede and nubuck?"
If a quick answer is all you need, you're done.
If you want to dig in deeper, the links to supporting sources are there for exploration.
Built with transparency and privacy in mind
We've built Quick Answers to be transparent about how it works and what data is shared.
Voice is processed on your device using Apple's speech recognition technology. No raw audio is stored or sent to the server, and Firefox doesn't share your browsing history or personal context with the AI model. Only the transcribed text of your question is sent to generate an answer. You can turn the feature off at any time in Settings → AI Controls.
Quick Answers is starting to roll out today to Firefox for iOS users in the U.S. using English.
Oh, and if you're wondering…
- Mellifluous means pleasant and musical to hear.
- 95 degrees Fahrenheit is 35 degrees Celsius.
- Suede is made from the underside of the hide, while nubuck is made from the outer side and buffed to create a soft, velvety texture.
Take control of your internet
Download FirefoxThe post Quick Answers: For the questions in between appeared first on The Mozilla Blog.
21 Jul 2026 4:00pm GMT
The Mozilla Blog: Experience Better Browsing: Introducing Native Containers in Firefox 153
Today, we're excited to announce the Preview of Containers in Firefox version 153, which lets you keep separate parts of your online life (work, shopping, personal, banking) logged into different accounts in the same browser window, but keeps your cookies and ad tracking isolated inside each container.
This means that stuff you do in one container isn't seen by other containers. No longer will you search for a new hat to wear to a party, only to be inundated with ads for hats at every twist and turn on the internet for weeks to come.
For almost a decade, many of you have relied on our Multi-Account Containers extension to keep work, personal, and privacy-sensitive browsing separate without needing multiple browsers or profiles.
We've heard your feedback and understood the value you find in that separation. Now, we're bringing the power of the Multi-Account Containers extension directly into the heart of Firefox for all to benefit from.
Why bring Containers into Firefox?
Whether you're managing multiple social media accounts, separating work projects from personal shopping, or simply keeping your banking activity distinct, Containers are designed to help you organize your digital space. By making Containers a native, first-party feature in Firefox 153, we are:
- Making it visible by default: You no longer need to hunt for an add-on to get started. Containers are built right into your browser, ready to help you manage your context from day one.
- Simplifying your workflow: We've focused on making it easier to open, create, and manage your containers from the places you already browse.
- Preserving what you love: For our long-time users who have relied on the add-on, the native experience is designed to maintain the core functionality, flexibility, and visual identity you depend on.
- Driving continued investment into the future of this feature, ensuring it lives on as a first party citizen of Firefox.
What to expect in the Preview
In this preview release, you can:
- Open tabs in specific containers: Keep your browsing activity isolated by context.
- Customize your workspace: Create and manage containers with your own names, colors, and icons.
- Manage settings easily: Control your container setup directly from the Firefox settings surface.
- Get Started: Right-click any tab or long-press the new tab (+) button to open a container tab - or head to Firefox Settings to create your first container.
If you're already using the Multi-Account Containers, there's nothing special you need to do. Not all of the features of the add-on are available in the first-party version of containers just yet, we're still building them out. You can continue to use the add-on alongside the built in containers, no need to uninstall the add-on.
This release represents our first step in making Firefox more adaptable to how you actually live and work online. While this is just the beginning, we have plans to refine this experience and build a foundation for future features that make context separation even more seamless.
Join the Conversation
We're eager to hear how this native experience fits into your daily routine. As you explore the new Containers Preview in Firefox 153, please let us know what you think by posting your feedback in this Mozilla Connect thread. Your feedback helps us shape the future of these tools and ensures we're building features that truly matter to you.
Take control of your internet
Download FirefoxThe post Experience Better Browsing: Introducing Native Containers in Firefox 153 appeared first on The Mozilla Blog.
21 Jul 2026 4:00pm GMT
Firefox Tooling Announcements: Firefox Profiler Deployment (July 21, 2026)
The latest version of the Firefox Profiler is now live! Check out the full changelog below to see what's changed:
Highlights:
- [fatadel] Show counter values over time in profiler-cli (#6136)
- [Markus Stange] More typed arrays: sample + counter times, some frametable columns (#6139)
- [Nazım Can Altınova] Add marker handles to
profiler-cli thread network(#6172) - [Nazım Can Altınova] Surface network activity across profiler-cli (#6175)
- [Nazım Can Altınova] Add
profile metacommand to profiler-cli (#6177) - [Markus Stange] Allow raw marker table's
startTimeandendTimecolumns to be Float64Array (#6169)
Other Changes:
- [Sky Ning] Skip preview links for non-main PRs (#6161)
- [spokodev] fix(gecko-upgrade): don't crash on a counter with empty sample_groups (#6160)
- [Markus Stange] Make profile-conversion snapshots more compact and meaningful (#6152)
- [Nazım Can Altınova] Only render a marker url field as a link when the whole value is a URL (#6163)
- [fatadel] Show each counter's owning process in profiler-cli (#6164)
- [Nazım Can Altınova] Document the pre-existing thread info and network JSON schemas in the cli (#6171)
- [Markus Stange] Copy column contents in getRawSamplesTableBuilderFromExisting for consistency (#6168)
- [Markus Stange] Convert eligible columns to typed arrays when outputting from profiler-edit (#6167)
- [Markus Stange] Remove unused samples.thread column (#6151)
- [Markus Stange] Fixed botched merge which broke 'yarn ts' (#6174)
- [Markus Stange] Update json-slabs 0.3.0 → 0.4.0 (major) (#6176)
- [nightcityblade] Fix light theme text selection colors (#6186)
- [Nazım Can Altınova] Import source map URLs from Chrome DevTools traces (#6190)
- [Nazım Can Altınova] Rename yarn
build-profiler-cliscript tobuild-cli(#6191) - [Nazım Can Altınova] Migrate husky to version 9 (#6201)
- [Nazım Can Altınova] Fix horizontal overflow when the transform navigator is long (#6199)
- [fatadel] Add a 'hexadecimal' marker schema field format (#6197)
- [Nazım Can Altınova] Bump source-map to 0.8.0 and remove the old type workaround (#6202)
- [Nazım Can Altınova]
 Sync: l10n → main (July 21, 2026) (#6209)
Sync: l10n → main (July 21, 2026) (#6209)
Big thanks to our amazing localizers for making this release possible:
- fr: parmegiani.thomas
- fr: Théo Chevalier
- sr: Марко Костић (Marko Kostić)
- sv-SE: Luna Jernberg
- tr: Grk
- zh-CN: Ariel
- zh-CN: Olvcpr423
Find out more about the Firefox Profiler on profiler.firefox.com! If you have any questions, join the discussion on our Matrix channel!
1 post - 1 participant
21 Jul 2026 12:44pm GMT